注册账号
diff --git a/frontend/src/lib/axios.ts b/frontend/src/lib/axios.ts
new file mode 100644
index 0000000..3e48110
--- /dev/null
+++ b/frontend/src/lib/axios.ts
@@ -0,0 +1,50 @@
+/**
+ * Axios 实例配置
+ * 全局拦截 401/403 响应,自动跳转登录页
+ */
+import axios from 'axios';
+
+// 动态获取 API 地址:服务端使用 localhost,客户端使用当前域名
+const API_BASE = typeof window === 'undefined'
+ ? 'http://localhost:8006'
+ : '';
+
+// 防止重复跳转
+let isRedirecting = false;
+
+// 创建 axios 实例
+const api = axios.create({
+ baseURL: API_BASE,
+ withCredentials: true, // 自动携带 cookie
+ headers: {
+ 'Content-Type': 'application/json',
+ },
+});
+
+// 响应拦截器 - 全局处理 401/403
+api.interceptors.response.use(
+ (response) => response,
+ async (error) => {
+ const status = error.response?.status;
+
+ if ((status === 401 || status === 403) && !isRedirecting) {
+ isRedirecting = true;
+
+ // 调用 logout API 清除 HttpOnly cookie
+ try {
+ await fetch('/api/auth/logout', { method: 'POST' });
+ } catch (e) {
+ // 忽略错误
+ }
+
+ // 跳转登录页
+ if (typeof window !== 'undefined') {
+ window.location.replace('/login');
+ }
+ }
+
+ return Promise.reject(error);
+ }
+);
+
+export default api;
diff --git a/frontend/src/proxy.ts b/frontend/src/proxy.ts
new file mode 100644
index 0000000..02cea53
--- /dev/null
+++ b/frontend/src/proxy.ts
@@ -0,0 +1,33 @@
+import { NextResponse } from 'next/server';
+import type { NextRequest } from 'next/server';
+
+// 需要登录才能访问的路径
+const protectedPaths = ['/', '/publish', '/admin'];
+
+// 公开路径 (无需登录)
+const publicPaths = ['/login', '/register'];
+
+export function proxy(request: NextRequest) {
+ const { pathname } = request.nextUrl;
+
+ // 检查是否有 access_token cookie
+ const token = request.cookies.get('access_token');
+
+ // 访问受保护页面但未登录 → 重定向到登录页
+ if (protectedPaths.some(path => pathname === path || pathname.startsWith(path + '/')) && !token) {
+ const loginUrl = new URL('/login', request.url);
+ loginUrl.searchParams.set('from', pathname);
+ return NextResponse.redirect(loginUrl);
+ }
+
+ // 已登录用户访问登录/注册页 → 重定向到首页
+ if (publicPaths.includes(pathname) && token) {
+ return NextResponse.redirect(new URL('/', request.url));
+ }
+
+ return NextResponse.next();
+}
+
+export const config = {
+ matcher: ['/', '/publish/:path*', '/admin/:path*', '/login', '/register']
+};
diff --git a/models/Qwen3-TTS/.gitignore b/models/Qwen3-TTS/.gitignore
new file mode 100644
index 0000000..1f6b14c
--- /dev/null
+++ b/models/Qwen3-TTS/.gitignore
@@ -0,0 +1,24 @@
+__pycache__/
+*.py[cod]
+*$py.class
+*.so
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+.idea/
+.vscode/
+venv/
+env/
\ No newline at end of file
diff --git a/models/Qwen3-TTS/LICENSE b/models/Qwen3-TTS/LICENSE
new file mode 100644
index 0000000..c347eb5
--- /dev/null
+++ b/models/Qwen3-TTS/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2026 Alibaba Cloud
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/models/Qwen3-TTS/MANIFEST.in b/models/Qwen3-TTS/MANIFEST.in
new file mode 100644
index 0000000..aa79178
--- /dev/null
+++ b/models/Qwen3-TTS/MANIFEST.in
@@ -0,0 +1,13 @@
+global-exclude *
+
+recursive-include qwen_tts *.py *.pyi py.typed
+recursive-include qwen_tts *.npz
+
+include LICENSE
+include MANIFEST.in
+include pyproject.toml
+
+prune assets
+prune examples
+prune finetuning
+prune qwen_tts.egg-info
\ No newline at end of file
diff --git a/models/Qwen3-TTS/README.md b/models/Qwen3-TTS/README.md
new file mode 100644
index 0000000..8287bac
--- /dev/null
+++ b/models/Qwen3-TTS/README.md
@@ -0,0 +1,1361 @@
+# Qwen3-TTS
+
+
+
+
+  +
+
+
+
+ 🤗 Hugging Face | 🤖 ModelScope | 📑 Blog | 📑 Paper
+
+🖥️ Hugging Face Demo | 🖥️ ModelScope Demo | 💬 WeChat (微信) | 🫨 Discord | 📑 API
+
+
+
+We release **Qwen3-TTS**, a series of powerful speech generation capabilities developed by Qwen, offering comprehensive support for voice clone, voice design, ultra-high-quality human-like speech generation, and natural language-based voice control. It provides developers and users with the most extensive set of speech generation features available.
+
+
+## News
+* 2026.1.22: 🎉🎉🎉 We have released [Qwen3-TTS](https://huggingface.co/collections/Qwen/qwen3-tts) series (0.6B/1.7B) based on Qwen3-TTS-Tokenizer-12Hz. Please check our [blog](https://qwen.ai/blog?id=qwen3tts-0115)!
+
+## Contents
+
+- [Overview](#overview)
+ - [Introduction](#introduction)
+ - [Model Architecture](#model-architecture)
+ - [Released Models Description and Download](#released-models-description-and-download)
+- [Quickstart](#quickstart)
+ - [Environment Setup](#environment-setup)
+ - [Python Package Usage](#python-package-usage)
+ - [Custom Voice Generation](#custom-voice-generate)
+ - [Voice Design](#voice-design)
+ - [Voice Clone](#voice-clone)
+ - [Voice Design then Clone](#voice-design-then-clone)
+ - [Tokenizer Encode and Decode](#tokenizer-encode-and-decode)
+ - [Launch Local Web UI Demo](#launch-local-web-ui-demo)
+ - [DashScope API Usage](#dashscope-api-usage)
+- [vLLM Usage](#vllm-usage)
+- [Fine Tuning](#fine-tuning)
+- [Evaluation](#evaluation)
+- [Citation](#citation)
+
+## Overview
+### Introduction
+
+
+  +
+
+
+Qwen3-TTS covers 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles to meet global application needs. In addition, the models feature strong contextual understanding, enabling adaptive control of tone, speaking rate, and emotional expression based on instructions and text semantics, and they show markedly improved robustness to noisy input text. Key features:
+
+* **Powerful Speech Representation**: Powered by the self-developed Qwen3-TTS-Tokenizer-12Hz, it achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals. It fully preserves paralinguistic information and acoustic environmental features, enabling high-speed, high-fidelity speech reconstruction through a lightweight non-DiT architecture.
+* **Universal End-to-End Architecture**: Utilizing a discrete multi-codebook LM architecture, it realizes full-information end-to-end speech modeling. This completely bypasses the information bottlenecks and cascading errors inherent in traditional LM+DiT schemes, significantly enhancing the model’s versatility, generation efficiency, and performance ceiling.
+* **Extreme Low-Latency Streaming Generation**: Based on the innovative Dual-Track hybrid streaming generation architecture, a single model supports both streaming and non-streaming generation. It can output the first audio packet immediately after a single character is input, with end-to-end synthesis latency as low as 97ms, meeting the rigorous demands of real-time interactive scenarios.
+* **Intelligent Text Understanding and Voice Control**: Supports speech generation driven by natural language instructions, allowing for flexible control over multi-dimensional acoustic attributes such as timbre, emotion, and prosody. By deeply integrating text semantic understanding, the model adaptively adjusts tone, rhythm, and emotional expression, achieving lifelike “what you imagine is what you hear” output.
+
+
+### Model Architecture
+
+
+ 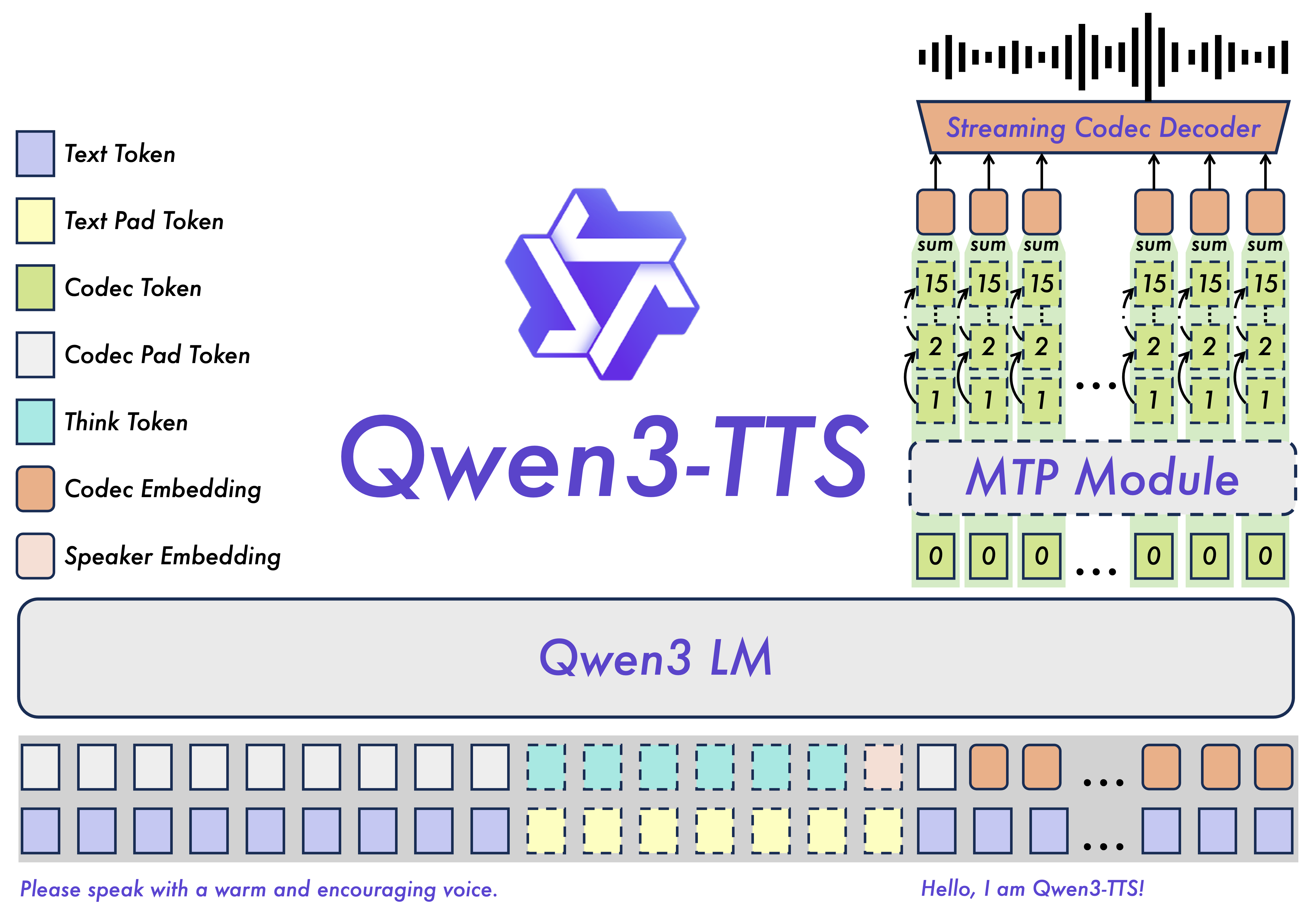 +
+
+
+### Released Models Description and Download
+
+Below is an introduction and download information for the Qwen3-TTS models that have already been released. Other models mentioned in the technical report will be released in the near future. Please select and download the model that fits your needs.
+
+| Tokenizer Name | Description |
+|---------------------------------|-------------|
+| Qwen3-TTS-Tokenizer-12Hz | The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech. |
+
+
+| Model | Features | Language Support | Streaming | Instruction Control |
+|---|---|---|---|---|
+| Qwen3-TTS-12Hz-1.7B-VoiceDesign | Performs voice design based on user-provided descriptions. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
+| Qwen3-TTS-12Hz-1.7B-CustomVoice | Provides style control over target timbres via user instructions; supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
+| Qwen3-TTS-12Hz-1.7B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+| Qwen3-TTS-12Hz-0.6B-CustomVoice | Supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+| Qwen3-TTS-12Hz-0.6B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+
+During model loading in the qwen-tts package or vLLM, model weights will be automatically downloaded based on the model name. However, if your runtime environment is not conducive to downloading weights during execution, you can refer to the following commands to manually download the model weights to a local directory:
+
+```bash
+# Download through ModelScope (recommended for users in Mainland China)
+pip install -U modelscope
+modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
+modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
+modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
+
+# Download through Hugging Face
+pip install -U "huggingface_hub[cli]"
+huggingface-cli download Qwen/Qwen3-TTS-Tokenizer-12Hz --local-dir ./Qwen3-TTS-Tokenizer-12Hz
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local-dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-Base --local-dir ./Qwen3-TTS-12Hz-1.7B-Base
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-Base --local-dir ./Qwen3-TTS-12Hz-0.6B-Base
+```
+
+
+## Quickstart
+
+### Environment Setup
+
+The easiest way to quickly use Qwen3-TTS is to install the `qwen-tts` Python package from PyPI. This will pull in the required runtime dependencies and allow you to load any released Qwen3-TTS model. We recommend using a **fresh, isolated environment** to avoid dependency conflicts with existing packages. You can create a clean Python 3.12 environment like this:
+
+```bash
+conda create -n qwen3-tts python=3.12 -y
+conda activate qwen3-tts
+```
+
+then run:
+
+```bash
+pip install -U qwen-tts
+```
+
+If you want to develop or modify the code locally, install from source in editable mode.
+
+```bash
+git clone https://github.com/QwenLM/Qwen3-TTS.git
+cd Qwen3-TTS
+pip install -e .
+```
+
+Additionally, we recommend using FlashAttention 2 to reduce GPU memory usage.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+If your machine has less than 96GB of RAM and lots of CPU cores, run:
+
+```bash
+MAX_JOBS=4 pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the [FlashAttention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention 2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+
+### Python Package Usage
+
+After installation, you can import `Qwen3TTSModel` to run custom voice TTS, voice design, and voice clone. The model weights can be specified either as a Hugging Face model id (recommended) or as a local directory path you downloaded. For all the `generate_*` functions below, besides the parameters shown and explicitly documented, you can also pass generation kwargs supported by Hugging Face Transformers `model.generate`, e.g., `max_new_tokens`, `top_p`, etc.
+
+#### Custom Voice Generate
+
+For custom voice models (`Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice`), you just need to call `generate_custom_voice`, passing a single string or a batch list, along with `language`, `speaker`, and optional `instruct`. You can also call `model.get_supported_speakers()` and `model.get_supported_languages()` to see which speakers and languages the current model supports.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+# single inference
+wavs, sr = model.generate_custom_voice(
+ text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",
+ language="Chinese", # Pass `Auto` (or omit) for auto language adaptive; if the target language is known, set it explicitly.
+ speaker="Vivian",
+ instruct="用特别愤怒的语气说", # Omit if not needed.
+)
+sf.write("output_custom_voice.wav", wavs[0], sr)
+
+# batch inference
+wavs, sr = model.generate_custom_voice(
+ text=[
+ "其实我真的有发现,我是一个特别善于观察别人情绪的人。",
+ "She said she would be here by noon."
+ ],
+ language=["Chinese", "English"],
+ speaker=["Vivian", "Ryan"],
+ instruct=["", "Very happy."]
+)
+sf.write("output_custom_voice_1.wav", wavs[0], sr)
+sf.write("output_custom_voice_2.wav", wavs[1], sr)
+```
+
+For `Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice` models, the supported speaker list and speaker descriptions are provided below. We recommend using each speaker’s native language for the best quality. Of course, each speaker can speak any language supported by the model.
+
+| Speaker | Voice Description | Native language |
+| --- | --- | --- |
+| Vivian | Bright, slightly edgy young female voice. | Chinese |
+| Serena | Warm, gentle young female voice. | Chinese |
+| Uncle_Fu | Seasoned male voice with a low, mellow timbre. | Chinese |
+| Dylan | Youthful Beijing male voice with a clear, natural timbre. | Chinese (Beijing Dialect) |
+| Eric | Lively Chengdu male voice with a slightly husky brightness. | Chinese (Sichuan Dialect) |
+| Ryan | Dynamic male voice with strong rhythmic drive. | English |
+| Aiden | Sunny American male voice with a clear midrange. | English |
+| Ono_Anna | Playful Japanese female voice with a light, nimble timbre. | Japanese |
+| Sohee | Warm Korean female voice with rich emotion. | Korean |
+
+#### Voice Design
+
+For the voice design model (`Qwen3-TTS-12Hz-1.7B-VoiceDesign`), you can use `generate_voice_design` to provide the target text and a natural-language `instruct` description.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+# single inference
+wavs, sr = model.generate_voice_design(
+ text="哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
+ language="Chinese",
+ instruct="体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
+)
+sf.write("output_voice_design.wav", wavs[0], sr)
+
+# batch inference
+wavs, sr = model.generate_voice_design(
+ text=[
+ "哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
+ "It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there!"
+ ],
+ language=["Chinese", "English"],
+ instruct=[
+ "体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
+ "Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice."
+ ]
+)
+sf.write("output_voice_design_1.wav", wavs[0], sr)
+sf.write("output_voice_design_2.wav", wavs[1], sr)
+```
+
+#### Voice Clone
+
+For the voice clone model (`Qwen3-TTS-12Hz-1.7B/0.6B-Base`), to clone a voice and synthesize new content, you just need to provide a reference audio clip (`ref_audio`) along with its transcript (`ref_text`). `ref_audio` can be a local file path, a URL, a base64 string, or a `(numpy_array, sample_rate)` tuple. If you set `x_vector_only_mode=True`, only the speaker embedding is used so `ref_text` is not required, but cloning quality may be reduced.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
+ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
+
+wavs, sr = model.generate_voice_clone(
+ text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
+ language="English",
+ ref_audio=ref_audio,
+ ref_text=ref_text,
+)
+sf.write("output_voice_clone.wav", wavs[0], sr)
+```
+
+If you need to reuse the same reference prompt across multiple generations (to avoid recomputing prompt features), build it once with `create_voice_clone_prompt` and pass it via `voice_clone_prompt`.
+
+```python
+prompt_items = model.create_voice_clone_prompt(
+ ref_audio=ref_audio,
+ ref_text=ref_text,
+ x_vector_only_mode=False,
+)
+wavs, sr = model.generate_voice_clone(
+ text=["Sentence A.", "Sentence B."],
+ language=["English", "English"],
+ voice_clone_prompt=prompt_items,
+)
+sf.write("output_voice_clone_1.wav", wavs[0], sr)
+sf.write("output_voice_clone_2.wav", wavs[1], sr)
+```
+
+For more examples of reusable voice clone prompts, batch cloning, and batch inference, please refer to the [example codes](https://github.com/QwenLM/Qwen3-TTS/blob/main/examples/test_model_12hz_base.py). With those examples and the `generate_voice_clone` function description, you can explore more advanced usage patterns.
+
+#### Voice Design then Clone
+
+If you want a designed voice that you can reuse like a cloned speaker, a practical workflow is: (1) use the **VoiceDesign** model to synthesize a short reference clip that matches your target persona, (2) feed that clip into `create_voice_clone_prompt` to build a reusable prompt, and then (3) call `generate_voice_clone` with `voice_clone_prompt` to generate new content without re-extracting features every time. This is especially useful when you want a consistent character voice across many lines.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+# create a reference audio in the target style using the VoiceDesign model
+design_model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+ref_text = "H-hey! You dropped your... uh... calculus notebook? I mean, I think it's yours? Maybe?"
+ref_instruct = "Male, 17 years old, tenor range, gaining confidence - deeper breath support now, though vowels still tighten when nervous"
+ref_wavs, sr = design_model.generate_voice_design(
+ text=ref_text,
+ language="English",
+ instruct=ref_instruct
+)
+sf.write("voice_design_reference.wav", ref_wavs[0], sr)
+
+# build a reusable clone prompt from the voice design reference
+clone_model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+voice_clone_prompt = clone_model.create_voice_clone_prompt(
+ ref_audio=(ref_wavs[0], sr), # or "voice_design_reference.wav"
+ ref_text=ref_text,
+)
+
+sentences = [
+ "No problem! I actually... kinda finished those already? If you want to compare answers or something...",
+ "What? No! I mean yes but not like... I just think you're... your titration technique is really precise!",
+]
+
+# reuse it for multiple single calls
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences[0],
+ language="English",
+ voice_clone_prompt=voice_clone_prompt,
+)
+sf.write("clone_single_1.wav", wavs[0], sr)
+
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences[1],
+ language="English",
+ voice_clone_prompt=voice_clone_prompt,
+)
+sf.write("clone_single_2.wav", wavs[0], sr)
+
+# or batch generate in one call
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences,
+ language=["English", "English"],
+ voice_clone_prompt=voice_clone_prompt,
+)
+for i, w in enumerate(wavs):
+ sf.write(f"clone_batch_{i}.wav", w, sr)
+```
+
+#### Tokenizer Encode and Decode
+
+If you only want to encode and decode audio for transport or training and so on, `Qwen3TTSTokenizer` supports encode/decode with paths, URLs, numpy waveforms, and dict/list payloads, for example:
+
+```python
+import soundfile as sf
+from qwen_tts import Qwen3TTSTokenizer
+
+tokenizer = Qwen3TTSTokenizer.from_pretrained(
+ "Qwen/Qwen3-TTS-Tokenizer-12Hz",
+ device_map="cuda:0",
+)
+
+enc = tokenizer.encode("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/tokenizer_demo_1.wav")
+wavs, sr = tokenizer.decode(enc)
+sf.write("decode_output.wav", wavs[0], sr)
+```
+
+For more tokenizer examples (including different input formats and batch usage), please refer to the [example codes](https://github.com/QwenLM/Qwen3-TTS/blob/main/examples/test_tokenizer_12hz.py). With those examples and the description for `Qwen3TTSTokenizer`, you can explore more advanced usage patterns.
+
+### Launch Local Web UI Demo
+
+To launch the Qwen3-TTS web ui demo, simply install the `qwen-tts` package and run `qwen-tts-demo`. Use the command below for help:
+
+```bash
+qwen-tts-demo --help
+```
+
+To launch the demo, you can use the following commands:
+
+```bash
+# CustomVoice model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --ip 0.0.0.0 --port 8000
+# VoiceDesign model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --ip 0.0.0.0 --port 8000
+# Base model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --ip 0.0.0.0 --port 8000
+```
+
+And then open `http://:8000`, or access it via port forwarding in tools like VS Code.
+
+#### Base Model HTTPS Notes
+
+To avoid browser microphone permission issues after deploying the server, for Base model deployments, it is recommended/required to run the gradio service over **HTTPS** (especially when accessed remotely or behind modern browsers/gateways). Use `--ssl-certfile` and `--ssl-keyfile` to enable HTTPS. First we need to generate a private key and a self-signed cert (valid for 365 days):
+
+```bash
+openssl req -x509 -newkey rsa:2048 \
+ -keyout key.pem -out cert.pem \
+ -days 365 -nodes \
+ -subj "/CN=localhost"
+```
+
+Then run the demo with HTTPS:
+
+```bash
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base \
+ --ip 0.0.0.0 --port 8000 \
+ --ssl-certfile cert.pem \
+ --ssl-keyfile key.pem \
+ --no-ssl-verify
+```
+
+And open `https://:8000` to experience it. If your browser shows a warning, it’s expected for self-signed certificates. For production, use a real certificate.
+
+### DashScope API Usage
+
+To further explore Qwen3-TTS, we encourage you to try our DashScope API for a faster and more efficient experience. For detailed API information and documentation, please refer to the following:
+
+| API Description | API Documentation (Mainland China) | API Documentation (International) |
+|------------------|-----------------------------------|------------------------------------|
+| Real-time API for Qwen3-TTS of custom voice model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-realtime](https://help.aliyun.com/zh/model-studio/qwen-tts-realtime) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-realtime](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-realtime) |
+| Real-time API for Qwen3-TTS of voice clone model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-voice-cloning](https://help.aliyun.com/zh/model-studio/qwen-tts-voice-cloning) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-cloning](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-cloning) |
+| Real-time API for Qwen3-TTS of voice design model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-voice-design](https://help.aliyun.com/zh/model-studio/qwen-tts-voice-design) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-design](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-design) |
+
+
+## vLLM Usage
+
+vLLM officially provides day-0 support for Qwen3-TTS! Welcome to use vLLM-Omni for Qwen3-TTS deployment and inference. For installation and more details, please check [vLLM-Omni official documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/getting_started/quickstart/#installation). Now only offline inference is supported. Online serving will be supported later, and vLLM-Omni will continue to offer support and optimization for Qwen3-TTS in areas such as inference speed and streaming capabilities.
+
+### Offline Inference
+You can use vLLM-Omni to inference Qwen3-TTS locally, we provide examples in [vLLM-Omni repo](https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/qwen3_tts) which can generate audio output:
+```bash
+# git clone https://github.com/vllm-project/vllm-omni.git
+
+# cd vllm-omni/examples/offline_inference/qwen3_tts
+
+# Run a single sample with CustomVoice task
+python end2end.py --query-type CustomVoice
+
+# Batch sample (multiple prompts in one run) with CustomVoice task:
+python end2end.py --query-type CustomVoice --use-batch-sample
+
+# Run a single sample with VoiceDesign task
+python end2end.py --query-type VoiceDesign
+
+# Batch sample (multiple prompts in one run) with VoiceDesign task:
+python end2end.py --query-type VoiceDesign --use-batch-sample
+
+# Run a single sample with Base task in icl mode-tag
+python end2end.py --query-type Base --mode-tag icl
+```
+
+## Fine Tuning
+
+Please refer to [Qwen3-TTS-Finetuning](finetuning/) for detailed instructions on fine-tuning Qwen3-TTS.
+
+## Evaluation
+
+During evaluation, we ran inference for all models with `dtype=torch.bfloat16` and set `max_new_tokens=2048`. All other sampling parameters used the defaults from the checkpoint’s `generate_config.json`. For the Seed-Test and InstructTTS-Eval test sets, we set `language="auto"`, while for all other test sets we explicitly passed the corresponding `language`. The detailed results are shown below.
+
+
+
+Speech Generation Benchmarks
+
+*Zero-shot speech generation on the Seed-TTS test set. Performance is measured by Word Error Rate (WER, ↓), where lower is better.*
+
+
+
+
+ | Datasets |
+ Model |
+ Performance |
+
+
+ | Content Consistency |
+
+
+
+
+ SEED
test-zh | test-en |
+ Seed-TTS (Anastassiou et al., 2024) |
+ 1.12 |
+ 2.25 |
+
+
+ | MaskGCT (Wang et al., 2024) |
+ 2.27 |
+ 2.62 |
+
+
+ | E2 TTS (Eskimez et al., 2024) |
+ 1.97 |
+ 2.19 |
+
+
+ | F5-TTS (Chen et al., 2024) |
+ 1.56 |
+ 1.83 |
+
+
+ | Spark TTS (Wang et al., 2025) |
+ 1.20 |
+ 1.98 |
+
+
+ | Llasa-8B (Ye et al., 2025b) |
+ 1.59 |
+ 2.97 |
+
+
+ | KALL-E (Xia et al., 2024) |
+ 0.96 |
+ 1.94 |
+
+
+ | FireRedTTS 2 (Xie et al., 2025) |
+ 1.14 |
+ 1.95 |
+
+
+ | CosyVoice 3 (Du et al., 2025) |
+ 0.71 |
+ 1.45 |
+
+
+ | MiniMax-Speech (Zhang et al., 2025a) |
+ 0.83 |
+ 1.65 |
+
+
+ | Qwen3-TTS-25Hz-0.6B-Base |
+ 1.18 |
+ 1.64 |
+
+
+ | Qwen3-TTS-25Hz-1.7B-Base |
+ 1.10 |
+ 1.49 |
+
+
+ | Qwen3-TTS-12Hz-0.6B-Base |
+ 0.92 |
+ 1.32 |
+
+
+ | Qwen3-TTS-12Hz-1.7B-Base |
+ 0.77 |
+ 1.24 |
+
+
+
+
+
+
+*Multilingual speech generation on the TTS multilingual test set. Performance is measured by Word Error Rate (WER, ↓) for content consistency and Cosine Similarity (SIM, ↑) for speaker similarity.*
+
+
+
+
+ | Language |
+ Qwen3-TTS-25Hz |
+ Qwen3-TTS-12Hz |
+ MiniMax |
+ ElevenLabs |
+
+
+ | 0.6B-Base |
+ 1.7B-Base |
+ 0.6B-Base |
+ 1.7B-Base |
+
+
+
+
+ | Content Consistency |
+
+
+ | Chinese |
+ 1.108 |
+ 0.777 |
+ 1.145 |
+ 0.928 |
+ 2.252 |
+ 16.026 |
+
+
+ | English |
+ 1.048 |
+ 1.014 |
+ 0.836 |
+ 0.934 |
+ 2.164 |
+ 2.339 |
+
+
+ | German |
+ 1.501 |
+ 0.960 |
+ 1.089 |
+ 1.235 |
+ 1.906 |
+ 0.572 |
+
+
+ | Italian |
+ 1.169 |
+ 1.105 |
+ 1.534 |
+ 0.948 |
+ 1.543 |
+ 1.743 |
+
+
+ | Portuguese |
+ 2.046 |
+ 1.778 |
+ 2.254 |
+ 1.526 |
+ 1.877 |
+ 1.331 |
+
+
+ | Spanish |
+ 2.031 |
+ 1.491 |
+ 1.491 |
+ 1.126 |
+ 1.029 |
+ 1.084 |
+
+
+ | Japanese |
+ 4.189 |
+ 5.121 |
+ 6.404 |
+ 3.823 |
+ 3.519 |
+ 10.646 |
+
+
+ | Korean |
+ 2.852 |
+ 2.631 |
+ 1.741 |
+ 1.755 |
+ 1.747 |
+ 1.865 |
+
+
+ | French |
+ 2.852 |
+ 2.631 |
+ 2.931 |
+ 2.858 |
+ 4.099 |
+ 5.216 |
+
+
+ | Russian |
+ 5.957 |
+ 4.535 |
+ 4.458 |
+ 3.212 |
+ 4.281 |
+ 3.878 |
+
+
+ | Speaker Similarity |
+
+
+ | Chinese |
+ 0.797 |
+ 0.796 |
+ 0.811 |
+ 0.799 |
+ 0.780 |
+ 0.677 |
+
+
+ | English |
+ 0.811 |
+ 0.815 |
+ 0.829 |
+ 0.775 |
+ 0.756 |
+ 0.613 |
+
+
+ | German |
+ 0.749 |
+ 0.737 |
+ 0.769 |
+ 0.775 |
+ 0.733 |
+ 0.614 |
+
+
+ | Italian |
+ 0.722 |
+ 0.718 |
+ 0.792 |
+ 0.817 |
+ 0.699 |
+ 0.579 |
+
+
+ | Portuguese |
+ 0.790 |
+ 0.783 |
+ 0.794 |
+ 0.817 |
+ 0.805 |
+ 0.711 |
+
+
+ | Spanish |
+ 0.732 |
+ 0.731 |
+ 0.812 |
+ 0.814 |
+ 0.762 |
+ 0.615 |
+
+
+ | Japanese |
+ 0.810 |
+ 0.807 |
+ 0.798 |
+ 0.788 |
+ 0.776 |
+ 0.738 |
+
+
+ | Korean |
+ 0.824 |
+ 0.814 |
+ 0.812 |
+ 0.799 |
+ 0.779 |
+ 0.700 |
+
+
+ | French |
+ 0.698 |
+ 0.703 |
+ 0.700 |
+ 0.714 |
+ 0.628 |
+ 0.535 |
+
+
+ | Russian |
+ 0.734 |
+ 0.744 |
+ 0.781 |
+ 0.792 |
+ 0.761 |
+ 0.676 |
+
+
+
+
+
+
+*Cross-lingual speech generation on the Cross-Lingual benchmark. Performance is measured by Mixed Error Rate (WER for English, CER for others, ↓).*
+
+
+
+
+ | Task |
+ Qwen3-TTS-25Hz-1.7B-Base |
+ Qwen3-TTS-12Hz-1.7B-Base |
+ CosyVoice3 |
+ CosyVoice2 |
+
+
+
+
+ | en-to-zh |
+ 5.66 |
+ 4.77 |
+ 5.09 |
+ 13.5 |
+
+
+ | ja-to-zh |
+ 3.92 |
+ 3.43 |
+ 3.05 |
+ 48.1 |
+
+
+ | ko-to-zh |
+ 1.14 |
+ 1.08 |
+ 1.06 |
+ 7.70 |
+
+
+ | zh-to-en |
+ 2.91 |
+ 2.77 |
+ 2.98 |
+ 6.47 |
+
+
+ | ja-to-en |
+ 3.95 |
+ 3.04 |
+ 4.20 |
+ 17.1 |
+
+
+ | ko-to-en |
+ 3.48 |
+ 3.09 |
+ 4.19 |
+ 11.2 |
+
+
+ | zh-to-ja |
+ 9.29 |
+ 8.40 |
+ 7.08 |
+ 13.1 |
+
+
+ | en-to-ja |
+ 7.74 |
+ 7.21 |
+ 6.80 |
+ 14.9 |
+
+
+ | ko-to-ja |
+ 4.17 |
+ 3.67 |
+ 3.93 |
+ 5.86 |
+
+
+ | zh-to-ko |
+ 8.12 |
+ 4.82 |
+ 14.4 |
+ 24.8 |
+
+
+ | en-to-ko |
+ 6.83 |
+ 5.14 |
+ 5.87 |
+ 21.9 |
+
+
+ | ja-to-ko |
+ 6.86 |
+ 5.59 |
+ 7.92 |
+ 21.5 |
+
+
+
+
+
+
+*Controllable speech generation on InstructTTSEval. Performance is measured by Attribute Perception and Synthesis accuracy (APS), Description-Speech Consistency (DSD), and Response Precision (RP).*
+
+
+
+
+ | Type |
+ Model |
+ InstructTTSEval-ZH |
+ InstructTTSEval-EN |
+
+
+ | APS (↑) |
+ DSD (↑) |
+ RP (↑) |
+ APS (↑) |
+ DSD (↑) |
+ RP (↑) |
+
+
+
+
+ Target
Speaker |
+ Gemini-flash |
+ 88.2 |
+ 90.9 |
+ 77.3 |
+ 92.3 |
+ 93.8 |
+ 80.1 |
+
+
+ | Gemini-pro |
+ 89.0 |
+ 90.1 |
+ 75.5 |
+ 87.6 |
+ 86.0 |
+ 67.2 |
+
+
+ | Qwen3TTS-25Hz-1.7B-CustomVoice |
+ 83.1 |
+ 75.0 |
+ 63.0 |
+ 79.0 |
+ 82.8 |
+ 69.3 |
+
+
+ | Qwen3TTS-12Hz-1.7B-CustomVoice |
+ 83.0 |
+ 77.8 |
+ 61.2 |
+ 77.3 |
+ 77.1 |
+ 63.7 |
+
+
+ | GPT-4o-mini-tts |
+ 54.9 |
+ 52.3 |
+ 46.0 |
+ 76.4 |
+ 74.3 |
+ 54.8 |
+
+
+ Voice
Design |
+ Qwen3TTS-12Hz-1.7B-VD |
+ 85.2 |
+ 81.1 |
+ 65.1 |
+ 82.9 |
+ 82.4 |
+ 68.4 |
+
+
+ | Mimo-Audio-7B-Instruct (Zhang et al., 2025b) |
+ 75.7 |
+ 74.3 |
+ 61.5 |
+ 80.6 |
+ 77.6 |
+ 59.5 |
+
+
+ | VoiceSculptor (Hu et al., 2026) |
+ 75.7 |
+ 64.7 |
+ 61.5 |
+ - |
+ - |
+ - |
+
+
+ | Hume |
+ - |
+ - |
+ - |
+ 83.0 |
+ 75.3 |
+ 54.3 |
+
+
+ | VoxInstruct (Zhou et al., 2024) |
+ 47.5 |
+ 52.3 |
+ 42.6 |
+ 54.9 |
+ 57.0 |
+ 39.3 |
+
+
+ | Parler-tts-mini (Lyth & King, 2024) |
+ - |
+ - |
+ - |
+ 63.4 |
+ 48.7 |
+ 28.6 |
+
+
+ | Parler-tts-large (Lyth & King, 2024) |
+ - |
+ - |
+ - |
+ 60.0 |
+ 45.9 |
+ 31.2 |
+
+
+ | PromptTTS (Guo et al., 2023) |
+ - |
+ - |
+ - |
+ 64.3 |
+ 47.2 |
+ 31.4 |
+
+
+ | PromptStyle (Liu et al., 2023) |
+ - |
+ - |
+ - |
+ 57.4 |
+ 46.4 |
+ 30.9 |
+
+
+
+
+
+
+*Target-Speaker Multilingual Speech Generation on the TTS multilingual test set. Performance is measured by Word Error Rate (WER, ↓).*
+
+
+
+
+ | Language |
+ Qwen3-TTS-25Hz |
+ Qwen3-TTS-12Hz |
+ GPT-4o-Audio
Preview |
+
+
+ | 0.6B-CustomVoice |
+ 1.7B-CustomVoice |
+ 0.6B-CustomVoice |
+ 1.7B-CustomVoice |
+
+
+
+
+ | Chinese |
+ 0.874 |
+ 0.708 |
+ 0.944 |
+ 0.903 |
+ 3.519 |
+
+
+ | English |
+ 1.332 |
+ 0.936 |
+ 1.188 |
+ 0.899 |
+ 2.197 |
+
+
+ | German |
+ 0.990 |
+ 0.634 |
+ 2.722 |
+ 1.057 |
+ 1.161 |
+
+
+ | Italian |
+ 1.861 |
+ 1.271 |
+ 2.545 |
+ 1.362 |
+ 1.194 |
+
+
+ | Portuguese |
+ 1.728 |
+ 1.854 |
+ 3.219 |
+ 2.681 |
+ 1.504 |
+
+
+ | Spanish |
+ 1.309 |
+ 1.284 |
+ 1.154 |
+ 1.330 |
+ 4.000 |
+
+
+ | Japanese |
+ 3.875 |
+ 4.518 |
+ 6.877 |
+ 4.924 |
+ 5.001 |
+
+
+ | Korean |
+ 2.202 |
+ 2.274 |
+ 3.053 |
+ 1.741 |
+ 2.763 |
+
+
+ | French |
+ 3.865 |
+ 3.080 |
+ 3.841 |
+ 3.781 |
+ 3.605 |
+
+
+ | Russian |
+ 6.529 |
+ 4.444 |
+ 5.809 |
+ 4.734 |
+ 5.250 |
+
+
+
+
+
+
+*Long speech generation results. Performance is measured by Word Error Rate (WER, ↓).*
+
+
+
+
+ | Datasets |
+ Model |
+ Performance |
+
+
+ | Content Consistency |
+
+
+
+
+ | long-zh | long-en |
+ Higgs-Audio-v2 (chunk) (Boson AI, 2025) |
+ 5.505 |
+ 6.917 |
+
+
+ | VibeVoice (Peng et al., 2025) |
+ 22.619 |
+ 1.780 |
+
+
+ | VoxCPM (Zhou et al., 2025) |
+ 4.835 |
+ 7.474 |
+
+
+ | Qwen3-TTS-25Hz-1.7B-CustomVoice |
+ 1.517 |
+ 1.225 |
+
+
+ | Qwen3-TTS-12Hz-1.7B-CustomVoice |
+ 2.356 |
+ 2.812 |
+
+
+
+
+
+
+
+Speech Tokenizer Benchmarks
+
+*Comparison between different supervised semantic speech tokenizers on ASR Task.*
+
+
+
+
+ | Model |
+ Codebook Size |
+ FPS |
+ C.V. EN |
+ C.V. CN |
+ Fluers EN |
+ Fluers CN |
+
+
+
+
+ | S3 Tokenizer(VQ) (Du et al., 2024a) |
+ 4096 |
+ 50 |
+ 12.06 |
+ 15.38 |
+ - |
+ - |
+
+
+ | S3 Tokenizer(VQ) (Du et al., 2024a) |
+ 4096 |
+ 25 |
+ 11.56 |
+ 18.26 |
+ 7.65 |
+ 5.03 |
+
+
+ | S3 Tokenizer(FSQ) (Du et al., 2024a) |
+ 6561 |
+ 25 |
+ 10.67 |
+ 7.29 |
+ 6.58 |
+ 4.43 |
+
+
+ | Qwen-TTS-Tokenizer-25Hz (Stage 1) |
+ 32768 |
+ 25 |
+ 7.51 |
+ 10.73 |
+ 3.07 |
+ 4.23 |
+
+
+ | Qwen-TTS-Tokenizer-25Hz (Stage 2) |
+ 32768 |
+ 25 |
+ 10.40 |
+ 14.99 |
+ 4.14 |
+ 4.67 |
+
+
+
+
+
+
+*Comparison between different semantic-related speech tokenizers.*
+
+
+
+
+ | Model |
+ NQ |
+ Codebook Size |
+ FPS |
+ PESQ_WB |
+ PESQ_NB |
+ STOI |
+ UTMOS |
+ SIM |
+
+
+
+
+ | SpeechTokenizer (Zhang et al., 2023a) |
+ 8 |
+ 1024 |
+ 50 |
+ 2.60 |
+ 3.05 |
+ 0.92 |
+ 3.90 |
+ 0.85 |
+
+
+ | X-codec (Ye et al., 2025a) |
+ 2 |
+ 1024 |
+ 50 |
+ 2.68 |
+ 3.27 |
+ 0.86 |
+ 4.11 |
+ 0.84 |
+
+
+ | X-codec 2 (Ye et al., 2025b) |
+ 1 |
+ 65536 |
+ 50 |
+ 2.43 |
+ 3.04 |
+ 0.92 |
+ 4.13 |
+ 0.82 |
+
+
+ | XY-Tokenizer (Gong et al., 2025) |
+ 8 |
+ 1024 |
+ 12.5 |
+ 2.41 |
+ 3.00 |
+ 0.91 |
+ 3.98 |
+ 0.83 |
+
+
+ | Mimi (Défossez et al., 2024) |
+ 16 |
+ 2048 |
+ 12.5 |
+ 2.88 |
+ 3.42 |
+ 0.94 |
+ 3.87 |
+ 0.87 |
+
+
+ | FireredTTS 2 Tokenizer (Xie et al., 2025) |
+ 16 |
+ 2048 |
+ 12.5 |
+ 2.73 |
+ 3.28 |
+ 0.94 |
+ 3.88 |
+ 0.87 |
+
+
+ | Qwen-TTS-Tokenizer-12Hz |
+ 16 |
+ 2048 |
+ 12.5 |
+ 3.21 |
+ 3.68 |
+ 0.96 |
+ 4.16 |
+ 0.95 |
+
+
+
+
+
+
+
+## Citation
+
+If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
+
+```BibTeX
+@article{Qwen3-TTS,
+ title={Qwen3-TTS Technical Report},
+ author={Hangrui Hu and Xinfa Zhu and Ting He and Dake Guo and Bin Zhang and Xiong Wang and Zhifang Guo and Ziyue Jiang and Hongkun Hao and Zishan Guo and Xinyu Zhang and Pei Zhang and Baosong Yang and Jin Xu and Jingren Zhou and Junyang Lin},
+ journal={arXiv preprint arXiv:2601.15621},
+ year={2026}
+}
+```
+
+
+## Star History
+
+[](https://star-history.com/#QwenLM/Qwen3-TTS&Date)
+
+
+
\ No newline at end of file
diff --git a/models/Qwen3-TTS/finetuning/README.md b/models/Qwen3-TTS/finetuning/README.md
new file mode 100644
index 0000000..7cd48b0
--- /dev/null
+++ b/models/Qwen3-TTS/finetuning/README.md
@@ -0,0 +1,121 @@
+## Fine Tuning Qwen3-TTS-12Hz-1.7B/0.6B-Base
+
+The Qwen3-TTS-12Hz-1.7B/0.6B-Base model series currently supports single-speaker fine-tuning. Please run `pip install qwen-tts` first, then run the command below:
+
+```
+git clone https://github.com/QwenLM/Qwen3-TTS.git
+cd Qwen3-TTS/finetuning
+```
+
+Then follow the steps below to complete the entire fine-tuning workflow. Multi-speaker fine-tuning and other advanced fine-tuning features will be supported in future releases.
+
+### 1) Input JSONL format
+
+Prepare your training file as a JSONL (one JSON object per line). Each line must contain:
+
+- `audio`: path to the target training audio (wav)
+- `text`: transcript corresponding to `audio`
+- `ref_audio`: path to the reference speaker audio (wav)
+
+Example:
+```jsonl
+{"audio":"./data/utt0001.wav","text":"其实我真的有发现,我是一个特别善于观察别人情绪的人。","ref_audio":"./data/ref.wav"}
+{"audio":"./data/utt0002.wav","text":"She said she would be here by noon.","ref_audio":"./data/ref.wav"}
+```
+
+`ref_audio` recommendation:
+- Strongly recommended: use the same `ref_audio` for all samples.
+- Keeping `ref_audio` identical across the dataset usually improves speaker consistency and stability during generation.
+
+
+### 2) Prepare data (extract `audio_codes`)
+
+Convert `train_raw.jsonl` into a training JSONL that includes `audio_codes`:
+
+```bash
+python prepare_data.py \
+ --device cuda:0 \
+ --tokenizer_model_path Qwen/Qwen3-TTS-Tokenizer-12Hz \
+ --input_jsonl train_raw.jsonl \
+ --output_jsonl train_with_codes.jsonl
+```
+
+
+### 3) Fine-tune
+
+Run SFT using the prepared JSONL:
+
+```bash
+python sft_12hz.py \
+ --init_model_path Qwen/Qwen3-TTS-12Hz-1.7B-Base \
+ --output_model_path output \
+ --train_jsonl train_with_codes.jsonl \
+ --batch_size 2 \
+ --lr 2e-5 \
+ --num_epochs 3 \
+ --speaker_name speaker_test
+```
+
+Checkpoints will be written to:
+- `output/checkpoint-epoch-0`
+- `output/checkpoint-epoch-1`
+- `output/checkpoint-epoch-2`
+- ...
+
+
+### 4) Quick inference test
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+device = "cuda:0"
+tts = Qwen3TTSModel.from_pretrained(
+ "output/checkpoint-epoch-2",
+ device_map=device,
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+wavs, sr = tts.generate_custom_voice(
+ text="She said she would be here by noon.",
+ speaker="speaker_test",
+)
+sf.write("output.wav", wavs[0], sr)
+```
+
+### One-click shell script example
+
+```bash
+#!/usr/bin/env bash
+set -e
+
+DEVICE="cuda:0"
+TOKENIZER_MODEL_PATH="Qwen/Qwen3-TTS-Tokenizer-12Hz"
+INIT_MODEL_PATH="Qwen/Qwen3-TTS-12Hz-1.7B-Base"
+
+RAW_JSONL="train_raw.jsonl"
+TRAIN_JSONL="train_with_codes.jsonl"
+OUTPUT_DIR="output"
+
+BATCH_SIZE=2
+LR=2e-5
+EPOCHS=3
+SPEAKER_NAME="speaker_1"
+
+python prepare_data.py \
+ --device ${DEVICE} \
+ --tokenizer_model_path ${TOKENIZER_MODEL_PATH} \
+ --input_jsonl ${RAW_JSONL} \
+ --output_jsonl ${TRAIN_JSONL}
+
+python sft_12hz.py \
+ --init_model_path ${INIT_MODEL_PATH} \
+ --output_model_path ${OUTPUT_DIR} \
+ --train_jsonl ${TRAIN_JSONL} \
+ --batch_size ${BATCH_SIZE} \
+ --lr ${LR} \
+ --num_epochs ${EPOCHS} \
+ --speaker_name ${SPEAKER_NAME}
+```
\ No newline at end of file
diff --git a/models/Qwen3-TTS/finetuning/dataset.py b/models/Qwen3-TTS/finetuning/dataset.py
new file mode 100644
index 0000000..f7c1cbe
--- /dev/null
+++ b/models/Qwen3-TTS/finetuning/dataset.py
@@ -0,0 +1,218 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Any, List, Tuple, Union
+
+import librosa
+import numpy as np
+import torch
+from qwen_tts.core.models.configuration_qwen3_tts import Qwen3TTSConfig
+from qwen_tts.core.models.modeling_qwen3_tts import mel_spectrogram
+from torch.utils.data import Dataset
+
+AudioLike = Union[
+ str, # wav path, URL, base64
+ np.ndarray, # waveform (requires sr)
+ Tuple[np.ndarray, int], # (waveform, sr)
+]
+
+MaybeList = Union[Any, List[Any]]
+
+class TTSDataset(Dataset):
+ def __init__(self, data_list, processor, config:Qwen3TTSConfig, lag_num = -1):
+ self.data_list = data_list
+ self.processor = processor
+ self.lag_num = lag_num
+ self.config = config
+
+ def __len__(self):
+ return len(self.data_list)
+
+ def _load_audio_to_np(self, x: str) -> Tuple[np.ndarray, int]:
+
+ audio, sr = librosa.load(x, sr=None, mono=True)
+
+ if audio.ndim > 1:
+ audio = np.mean(audio, axis=-1)
+
+ return audio.astype(np.float32), int(sr)
+
+ def _normalize_audio_inputs(self, audios: Union[AudioLike, List[AudioLike]]) -> List[Tuple[np.ndarray, int]]:
+ """
+ Normalize audio inputs into a list of (waveform, sr).
+
+ Supported forms:
+ - str: wav path / URL / base64 audio string
+ - np.ndarray: waveform (NOT allowed alone here because sr is unknown)
+ - (np.ndarray, sr): waveform + sampling rate
+ - list of the above
+
+ Args:
+ audios:
+ Audio input(s).
+
+ Returns:
+ List[Tuple[np.ndarray, int]]:
+ List of (float32 waveform, original sr).
+
+ Raises:
+ ValueError: If a numpy waveform is provided without sr.
+ """
+ if isinstance(audios, list):
+ items = audios
+ else:
+ items = [audios]
+
+ out: List[Tuple[np.ndarray, int]] = []
+ for a in items:
+ if isinstance(a, str):
+ out.append(self._load_audio_to_np(a))
+ elif isinstance(a, tuple) and len(a) == 2 and isinstance(a[0], np.ndarray):
+ out.append((a[0].astype(np.float32), int(a[1])))
+ elif isinstance(a, np.ndarray):
+ raise ValueError("For numpy waveform input, pass a tuple (audio, sr).")
+ else:
+ raise TypeError(f"Unsupported audio input type: {type(a)}")
+ return out
+
+
+ def _build_assistant_text(self, text: str) -> str:
+ return f"<|im_start|>assistant\n{text}<|im_end|>\n<|im_start|>assistant\n"
+
+ def _ensure_list(self, x: MaybeList) -> List[Any]:
+ return x if isinstance(x, list) else [x]
+
+ def _tokenize_texts(self, text) -> List[torch.Tensor]:
+ input = self.processor(text=text, return_tensors="pt", padding=True)
+ input_id = input["input_ids"]
+ input_id = input_id.unsqueeze(0) if input_id.dim() == 1 else input_id
+ return input_id
+
+ @torch.inference_mode()
+ def extract_mels(self, audio, sr):
+ assert sr == 24000, "Only support 24kHz audio"
+ mels = mel_spectrogram(
+ torch.from_numpy(audio).unsqueeze(0),
+ n_fft=1024,
+ num_mels=128,
+ sampling_rate=24000,
+ hop_size=256,
+ win_size=1024,
+ fmin=0,
+ fmax=12000
+ ).transpose(1, 2)
+ return mels
+
+
+
+ def __getitem__(self, idx):
+ item = self.data_list[idx]
+
+ audio_path = item["audio"]
+ text = item["text"]
+ audio_codes = item["audio_codes"]
+ language = item.get('language','Auto')
+ ref_audio_path = item['ref_audio']
+
+ text = self._build_assistant_text(text)
+ text_ids = self._tokenize_texts(text)
+
+ audio_codes = torch.tensor(audio_codes, dtype=torch.long)
+
+ ref_audio_list = self._ensure_list(ref_audio_path)
+ normalized = self._normalize_audio_inputs(ref_audio_list)
+ wav,sr = normalized[0]
+
+ ref_mel = self.extract_mels(audio=wav, sr=sr)
+
+ return {
+ "text_ids": text_ids[:,:-5], # 1 , t
+ "audio_codes":audio_codes, # t, 16
+ "ref_mel":ref_mel
+ }
+
+ def collate_fn(self, batch):
+ assert self.lag_num == -1
+
+ item_length = [b['text_ids'].shape[1] + b['audio_codes'].shape[0] for b in batch]
+ max_length = max(item_length) + 8
+ b,t = len(batch),max_length
+
+ input_ids = torch.zeros((b,t,2),dtype=torch.long)
+ codec_ids = torch.zeros((b,t,16),dtype=torch.long)
+ text_embedding_mask = torch.zeros((b,t),dtype=torch.bool)
+ codec_embedding_mask = torch.zeros((b,t),dtype=torch.bool)
+ codec_mask = torch.zeros((b,t),dtype=torch.bool)
+ attention_mask = torch.zeros((b,t),dtype=torch.long)
+ codec_0_labels = torch.full((b, t), -100, dtype=torch.long)
+
+ for i,data in enumerate(batch):
+ text_ids = data['text_ids']
+ audio_codec_0 = data['audio_codes'][:,0]
+ audio_codecs = data['audio_codes']
+
+ text_ids_len = text_ids.shape[1]
+ codec_ids_len = audio_codec_0.shape[0]
+
+ # text channel
+ input_ids[i, :3, 0] = text_ids[0,:3]
+ input_ids[i, 3:7, 0] = self.config.tts_pad_token_id
+ input_ids[i, 7, 0] = self.config.tts_bos_token_id
+ input_ids[i, 8:8+text_ids_len-3, 0] = text_ids[0,3:]
+ input_ids[i, 8+text_ids_len-3, 0] = self.config.tts_eos_token_id
+ input_ids[i, 8+text_ids_len-2:8+text_ids_len+codec_ids_len , 0] = self.config.tts_pad_token_id
+ text_embedding_mask[i, :8+text_ids_len+codec_ids_len] = True
+
+ # codec channel
+ # input_ids[i, :3, 1] = 0
+ input_ids[i, 3:8 ,1] = torch.tensor(
+ [
+ self.config.talker_config.codec_nothink_id,
+ self.config.talker_config.codec_think_bos_id,
+ self.config.talker_config.codec_think_eos_id,
+ 0, # for speaker embedding
+ self.config.talker_config.codec_pad_id
+ ]
+ )
+ input_ids[i, 8:8+text_ids_len-3 ,1] = self.config.talker_config.codec_pad_id
+ input_ids[i, 8+text_ids_len-3 ,1] = self.config.talker_config.codec_pad_id
+ input_ids[i, 8+text_ids_len-2 ,1] = self.config.talker_config.codec_bos_id
+ input_ids[i, 8+text_ids_len-1:8+text_ids_len-1+codec_ids_len, 1] = audio_codec_0
+ input_ids[i, 8+text_ids_len-1+codec_ids_len, 1] = self.config.talker_config.codec_eos_token_id
+
+ codec_0_labels[i, 8+text_ids_len-1:8+text_ids_len-1+codec_ids_len] = audio_codec_0
+ codec_0_labels[i, 8+text_ids_len-1+codec_ids_len] = self.config.talker_config.codec_eos_token_id
+
+ codec_ids[i, 8+text_ids_len-1:8+text_ids_len-1+codec_ids_len,:] = audio_codecs
+
+ codec_embedding_mask[i, 3:8+text_ids_len+codec_ids_len] = True
+ codec_embedding_mask[i, 6] = False # for speaker embedding
+
+ codec_mask[i, 8+text_ids_len-1:8+text_ids_len-1+codec_ids_len] = True
+ attention_mask[i, :8+text_ids_len+codec_ids_len] = True
+
+ ref_mels = [data['ref_mel'] for data in batch]
+ ref_mels = torch.cat(ref_mels,dim=0)
+
+ return {
+ 'input_ids':input_ids,
+ 'ref_mels':ref_mels,
+ 'attention_mask':attention_mask,
+ 'text_embedding_mask':text_embedding_mask.unsqueeze(-1),
+ 'codec_embedding_mask':codec_embedding_mask.unsqueeze(-1),
+ 'codec_0_labels':codec_0_labels,
+ 'codec_ids': codec_ids,
+ 'codec_mask':codec_mask
+ }
\ No newline at end of file
diff --git a/models/Qwen3-TTS/finetuning/prepare_data.py b/models/Qwen3-TTS/finetuning/prepare_data.py
new file mode 100644
index 0000000..7e64610
--- /dev/null
+++ b/models/Qwen3-TTS/finetuning/prepare_data.py
@@ -0,0 +1,71 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import json
+
+from qwen_tts import Qwen3TTSTokenizer
+
+BATCH_INFER_NUM = 32
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--device", type=str, default="cuda:0")
+ parser.add_argument("--tokenizer_model_path", type=str, default="Qwen/Qwen3-TTS-Tokenizer-12Hz")
+ parser.add_argument("--input_jsonl", type=str, required=True)
+ parser.add_argument("--output_jsonl", type=str, required=True)
+ args = parser.parse_args()
+
+ tokenizer_12hz = Qwen3TTSTokenizer.from_pretrained(
+ args.tokenizer_model_path,
+ device_map=args.device,
+ )
+
+ total_lines = open(args.input_jsonl).readlines()
+ total_lines = [json.loads(line.strip()) for line in total_lines]
+
+ final_lines = []
+ batch_lines = []
+ batch_audios = []
+ for line in total_lines:
+
+ batch_lines.append(line)
+ batch_audios.append(line['audio'])
+
+ if len(batch_lines) >= BATCH_INFER_NUM:
+ enc_res = tokenizer_12hz.encode(batch_audios)
+ for code, line in zip(enc_res.audio_codes, batch_lines):
+ line['audio_codes'] = code.cpu().tolist()
+ final_lines.append(line)
+ batch_lines.clear()
+ batch_audios.clear()
+
+ if len(batch_audios) > 0:
+ enc_res = tokenizer_12hz.encode(batch_audios)
+ for code, line in zip(enc_res.audio_codes, batch_lines):
+ line['audio_codes'] = code.cpu().tolist()
+ final_lines.append(line)
+ batch_lines.clear()
+ batch_audios.clear()
+
+ final_lines = [json.dumps(line, ensure_ascii=False) for line in final_lines]
+
+ with open(args.output_jsonl, 'w') as f:
+ for line in final_lines:
+ f.writelines(line + '\n')
+
+if __name__ == "__main__":
+ main()
diff --git a/models/Qwen3-TTS/finetuning/sft_12hz.py b/models/Qwen3-TTS/finetuning/sft_12hz.py
new file mode 100644
index 0000000..9ed8c48
--- /dev/null
+++ b/models/Qwen3-TTS/finetuning/sft_12hz.py
@@ -0,0 +1,161 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import json
+import os
+import shutil
+
+import torch
+from accelerate import Accelerator
+from dataset import TTSDataset
+from qwen_tts.inference.qwen3_tts_model import Qwen3TTSModel
+from safetensors.torch import save_file
+from torch.optim import AdamW
+from torch.utils.data import DataLoader
+from transformers import AutoConfig
+
+target_speaker_embedding = None
+def train():
+ global target_speaker_embedding
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--init_model_path", type=str, default="Qwen/Qwen3-TTS-12Hz-1.7B-Base")
+ parser.add_argument("--output_model_path", type=str, default="output")
+ parser.add_argument("--train_jsonl", type=str, required=True)
+ parser.add_argument("--batch_size", type=int, default=2)
+ parser.add_argument("--lr", type=float, default=2e-5)
+ parser.add_argument("--num_epochs", type=int, default=3)
+ parser.add_argument("--speaker_name", type=str, default="speaker_test")
+ args = parser.parse_args()
+
+ accelerator = Accelerator(gradient_accumulation_steps=4, mixed_precision="bf16", log_with="tensorboard")
+
+ MODEL_PATH = args.init_model_path
+
+ qwen3tts = Qwen3TTSModel.from_pretrained(
+ MODEL_PATH,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ )
+ config = AutoConfig.from_pretrained(MODEL_PATH)
+
+ train_data = open(args.train_jsonl).readlines()
+ train_data = [json.loads(line) for line in train_data]
+ dataset = TTSDataset(train_data, qwen3tts.processor, config)
+ train_dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, collate_fn=dataset.collate_fn)
+
+ optimizer = AdamW(qwen3tts.model.parameters(), lr=args.lr, weight_decay=0.01)
+
+ model, optimizer, train_dataloader = accelerator.prepare(
+ qwen3tts.model, optimizer, train_dataloader
+ )
+
+ num_epochs = args.num_epochs
+ model.train()
+
+ for epoch in range(num_epochs):
+ for step, batch in enumerate(train_dataloader):
+ with accelerator.accumulate(model):
+
+ input_ids = batch['input_ids']
+ codec_ids = batch['codec_ids']
+ ref_mels = batch['ref_mels']
+ text_embedding_mask = batch['text_embedding_mask']
+ codec_embedding_mask = batch['codec_embedding_mask']
+ attention_mask = batch['attention_mask']
+ codec_0_labels = batch['codec_0_labels']
+ codec_mask = batch['codec_mask']
+
+ speaker_embedding = model.speaker_encoder(ref_mels.to(model.device).to(model.dtype)).detach()
+ if target_speaker_embedding is None:
+ target_speaker_embedding = speaker_embedding
+
+ input_text_ids = input_ids[:, :, 0]
+ input_codec_ids = input_ids[:, :, 1]
+
+ input_text_embedding = model.talker.model.text_embedding(input_text_ids) * text_embedding_mask
+ input_codec_embedding = model.talker.model.codec_embedding(input_codec_ids) * codec_embedding_mask
+ input_codec_embedding[:, 6, :] = speaker_embedding
+
+ input_embeddings = input_text_embedding + input_codec_embedding
+
+ for i in range(1, 16):
+ codec_i_embedding = model.talker.code_predictor.get_input_embeddings()[i - 1](codec_ids[:, :, i])
+ codec_i_embedding = codec_i_embedding * codec_mask.unsqueeze(-1)
+ input_embeddings = input_embeddings + codec_i_embedding
+
+ outputs = model.talker(
+ inputs_embeds=input_embeddings[:, :-1, :],
+ attention_mask=attention_mask[:, :-1],
+ labels=codec_0_labels[:, 1:],
+ output_hidden_states=True
+ )
+
+ hidden_states = outputs.hidden_states[0][-1]
+ talker_hidden_states = hidden_states[codec_mask[:, 1:]]
+ talker_codec_ids = codec_ids[codec_mask]
+
+ sub_talker_logits, sub_talker_loss = model.talker.forward_sub_talker_finetune(talker_codec_ids, talker_hidden_states)
+
+ loss = outputs.loss + sub_talker_loss
+
+ accelerator.backward(loss)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+
+ optimizer.step()
+ optimizer.zero_grad()
+
+ if step % 10 == 0:
+ accelerator.print(f"Epoch {epoch} | Step {step} | Loss: {loss.item():.4f}")
+
+ if accelerator.is_main_process:
+ output_dir = os.path.join(args.output_model_path, f"checkpoint-epoch-{epoch}")
+ shutil.copytree(MODEL_PATH, output_dir, dirs_exist_ok=True)
+
+ input_config_file = os.path.join(MODEL_PATH, "config.json")
+ output_config_file = os.path.join(output_dir, "config.json")
+ with open(input_config_file, 'r', encoding='utf-8') as f:
+ config_dict = json.load(f)
+ config_dict["tts_model_type"] = "custom_voice"
+ talker_config = config_dict.get("talker_config", {})
+ talker_config["spk_id"] = {
+ args.speaker_name: 3000
+ }
+ talker_config["spk_is_dialect"] = {
+ args.speaker_name: False
+ }
+ config_dict["talker_config"] = talker_config
+
+ with open(output_config_file, 'w', encoding='utf-8') as f:
+ json.dump(config_dict, f, indent=2, ensure_ascii=False)
+
+ unwrapped_model = accelerator.unwrap_model(model)
+ state_dict = {k: v.detach().to("cpu") for k, v in unwrapped_model.state_dict().items()}
+
+ drop_prefix = "speaker_encoder"
+ keys_to_drop = [k for k in state_dict.keys() if k.startswith(drop_prefix)]
+ for k in keys_to_drop:
+ del state_dict[k]
+
+ weight = state_dict['talker.model.codec_embedding.weight']
+ state_dict['talker.model.codec_embedding.weight'][3000] = target_speaker_embedding[0].detach().to(weight.device).to(weight.dtype)
+ save_path = os.path.join(output_dir, "model.safetensors")
+ save_file(state_dict, save_path)
+
+if __name__ == "__main__":
+ train()
diff --git a/models/Qwen3-TTS/pyproject.toml b/models/Qwen3-TTS/pyproject.toml
new file mode 100644
index 0000000..b2b180a
--- /dev/null
+++ b/models/Qwen3-TTS/pyproject.toml
@@ -0,0 +1,46 @@
+[build-system]
+requires = ["setuptools>=68", "wheel"]
+build-backend = "setuptools.build_meta"
+
+[project]
+name = "qwen-tts"
+version = "0.0.4"
+description = "Qwen-TTS python package"
+readme = "README.md"
+requires-python = ">=3.9"
+classifiers = [
+ "Programming Language :: Python :: 3",
+ "Programming Language :: Python :: 3.9",
+ "Programming Language :: Python :: 3.10",
+ "Programming Language :: Python :: 3.11",
+ "Programming Language :: Python :: 3.12",
+ "Programming Language :: Python :: 3.13",
+]
+license = { text = "Apache-2.0" }
+authors = [{ name = "Alibaba Qwen Team" }]
+
+dependencies = [
+ "transformers==4.57.3",
+ "accelerate==1.12.0",
+ "gradio",
+ "librosa",
+ "torchaudio",
+ "soundfile",
+ "sox",
+ "onnxruntime",
+ "einops",
+]
+
+[project.urls]
+Homepage = "https://github.com/Qwen/Qwen3-TTS"
+Repository = "https://github.com/Qwen/Qwen3-TTS"
+
+[project.scripts]
+qwen-tts-demo = "qwen_tts.cli.demo:main"
+
+[tool.setuptools]
+packages = { find = { where = ["."] , include = ["qwen_tts*"] } }
+include-package-data = true
+
+[tool.setuptools.package-data]
+qwen_tts = ["py.typed", "**/*.npz"]
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/__init__.py b/models/Qwen3-TTS/qwen_tts/__init__.py
new file mode 100644
index 0000000..848c8dd
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/__init__.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+qwen_tts: Qwen-TTS package.
+"""
+
+from .inference.qwen3_tts_model import Qwen3TTSModel, VoiceClonePromptItem
+from .inference.qwen3_tts_tokenizer import Qwen3TTSTokenizer
+
+__all__ = ["__version__"]
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/__main__.py b/models/Qwen3-TTS/qwen_tts/__main__.py
new file mode 100644
index 0000000..315d8da
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/__main__.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+def main():
+ print(
+ "qwen_tts package.\n"
+ "Use CLI entrypoints:\n"
+ " - qwen-tts-demo\n"
+ )
+
+if __name__ == "__main__":
+ main()
diff --git a/models/Qwen3-TTS/qwen_tts/cli/demo.py b/models/Qwen3-TTS/qwen_tts/cli/demo.py
new file mode 100644
index 0000000..e267861
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/cli/demo.py
@@ -0,0 +1,634 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A gradio demo for Qwen3 TTS models.
+"""
+
+import argparse
+import os
+import tempfile
+from dataclasses import asdict
+from typing import Any, Dict, List, Optional, Tuple
+
+import gradio as gr
+import numpy as np
+import torch
+
+from .. import Qwen3TTSModel, VoiceClonePromptItem
+
+
+def _title_case_display(s: str) -> str:
+ s = (s or "").strip()
+ s = s.replace("_", " ")
+ return " ".join([w[:1].upper() + w[1:] if w else "" for w in s.split()])
+
+
+def _build_choices_and_map(items: Optional[List[str]]) -> Tuple[List[str], Dict[str, str]]:
+ if not items:
+ return [], {}
+ display = [_title_case_display(x) for x in items]
+ mapping = {d: r for d, r in zip(display, items)}
+ return display, mapping
+
+
+def _dtype_from_str(s: str) -> torch.dtype:
+ s = (s or "").strip().lower()
+ if s in ("bf16", "bfloat16"):
+ return torch.bfloat16
+ if s in ("fp16", "float16", "half"):
+ return torch.float16
+ if s in ("fp32", "float32"):
+ return torch.float32
+ raise ValueError(f"Unsupported torch dtype: {s}. Use bfloat16/float16/float32.")
+
+
+def _maybe(v):
+ return v if v is not None else gr.update()
+
+
+def build_parser() -> argparse.ArgumentParser:
+ parser = argparse.ArgumentParser(
+ prog="qwen-tts-demo",
+ description=(
+ "Launch a Gradio demo for Qwen3 TTS models (CustomVoice / VoiceDesign / Base).\n\n"
+ "Examples:\n"
+ " qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice\n"
+ " qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --port 8000 --ip 127.0.0.01\n"
+ " qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --device cuda:0\n"
+ " qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --dtype bfloat16 --no-flash-attn\n"
+ ),
+ formatter_class=argparse.RawTextHelpFormatter,
+ add_help=True,
+ )
+
+ # Positional checkpoint (also supports -c/--checkpoint)
+ parser.add_argument(
+ "checkpoint_pos",
+ nargs="?",
+ default=None,
+ help="Model checkpoint path or HuggingFace repo id (positional).",
+ )
+ parser.add_argument(
+ "-c",
+ "--checkpoint",
+ default=None,
+ help="Model checkpoint path or HuggingFace repo id (optional if positional is provided).",
+ )
+
+ # Model loading / from_pretrained args
+ parser.add_argument(
+ "--device",
+ default="cuda:0",
+ help="Device for device_map, e.g. cpu, cuda, cuda:0 (default: cuda:0).",
+ )
+ parser.add_argument(
+ "--dtype",
+ default="bfloat16",
+ choices=["bfloat16", "bf16", "float16", "fp16", "float32", "fp32"],
+ help="Torch dtype for loading the model (default: bfloat16).",
+ )
+ parser.add_argument(
+ "--flash-attn/--no-flash-attn",
+ dest="flash_attn",
+ default=True,
+ action=argparse.BooleanOptionalAction,
+ help="Enable FlashAttention-2 (default: enabled).",
+ )
+
+ # Gradio server args
+ parser.add_argument(
+ "--ip",
+ default="0.0.0.0",
+ help="Server bind IP for Gradio (default: 0.0.0.0).",
+ )
+ parser.add_argument(
+ "--port",
+ type=int,
+ default=8000,
+ help="Server port for Gradio (default: 8000).",
+ )
+ parser.add_argument(
+ "--share/--no-share",
+ dest="share",
+ default=False,
+ action=argparse.BooleanOptionalAction,
+ help="Whether to create a public Gradio link (default: disabled).",
+ )
+ parser.add_argument(
+ "--concurrency",
+ type=int,
+ default=16,
+ help="Gradio queue concurrency (default: 16).",
+ )
+
+ # HTTPS args
+ parser.add_argument(
+ "--ssl-certfile",
+ default=None,
+ help="Path to SSL certificate file for HTTPS (optional).",
+ )
+ parser.add_argument(
+ "--ssl-keyfile",
+ default=None,
+ help="Path to SSL key file for HTTPS (optional).",
+ )
+ parser.add_argument(
+ "--ssl-verify/--no-ssl-verify",
+ dest="ssl_verify",
+ default=True,
+ action=argparse.BooleanOptionalAction,
+ help="Whether to verify SSL certificate (default: enabled).",
+ )
+
+ # Optional generation args
+ parser.add_argument("--max-new-tokens", type=int, default=None, help="Max new tokens for generation (optional).")
+ parser.add_argument("--temperature", type=float, default=None, help="Sampling temperature (optional).")
+ parser.add_argument("--top-k", type=int, default=None, help="Top-k sampling (optional).")
+ parser.add_argument("--top-p", type=float, default=None, help="Top-p sampling (optional).")
+ parser.add_argument("--repetition-penalty", type=float, default=None, help="Repetition penalty (optional).")
+ parser.add_argument("--subtalker-top-k", type=int, default=None, help="Subtalker top-k (optional, only for tokenizer v2).")
+ parser.add_argument("--subtalker-top-p", type=float, default=None, help="Subtalker top-p (optional, only for tokenizer v2).")
+ parser.add_argument(
+ "--subtalker-temperature", type=float, default=None, help="Subtalker temperature (optional, only for tokenizer v2)."
+ )
+
+ return parser
+
+
+def _resolve_checkpoint(args: argparse.Namespace) -> str:
+ ckpt = args.checkpoint or args.checkpoint_pos
+ if not ckpt:
+ raise SystemExit(0) # main() prints help
+ return ckpt
+
+
+def _collect_gen_kwargs(args: argparse.Namespace) -> Dict[str, Any]:
+ mapping = {
+ "max_new_tokens": args.max_new_tokens,
+ "temperature": args.temperature,
+ "top_k": args.top_k,
+ "top_p": args.top_p,
+ "repetition_penalty": args.repetition_penalty,
+ "subtalker_top_k": args.subtalker_top_k,
+ "subtalker_top_p": args.subtalker_top_p,
+ "subtalker_temperature": args.subtalker_temperature,
+ }
+ return {k: v for k, v in mapping.items() if v is not None}
+
+
+def _normalize_audio(wav, eps=1e-12, clip=True):
+ x = np.asarray(wav)
+
+ if np.issubdtype(x.dtype, np.integer):
+ info = np.iinfo(x.dtype)
+
+ if info.min < 0:
+ y = x.astype(np.float32) / max(abs(info.min), info.max)
+ else:
+ mid = (info.max + 1) / 2.0
+ y = (x.astype(np.float32) - mid) / mid
+
+ elif np.issubdtype(x.dtype, np.floating):
+ y = x.astype(np.float32)
+ m = np.max(np.abs(y)) if y.size else 0.0
+
+ if m <= 1.0 + 1e-6:
+ pass
+ else:
+ y = y / (m + eps)
+ else:
+ raise TypeError(f"Unsupported dtype: {x.dtype}")
+
+ if clip:
+ y = np.clip(y, -1.0, 1.0)
+
+ if y.ndim > 1:
+ y = np.mean(y, axis=-1).astype(np.float32)
+
+ return y
+
+
+def _audio_to_tuple(audio: Any) -> Optional[Tuple[np.ndarray, int]]:
+ if audio is None:
+ return None
+
+ if isinstance(audio, tuple) and len(audio) == 2 and isinstance(audio[0], int):
+ sr, wav = audio
+ wav = _normalize_audio(wav)
+ return wav, int(sr)
+
+ if isinstance(audio, dict) and "sampling_rate" in audio and "data" in audio:
+ sr = int(audio["sampling_rate"])
+ wav = _normalize_audio(audio["data"])
+ return wav, sr
+
+ return None
+
+
+def _wav_to_gradio_audio(wav: np.ndarray, sr: int) -> Tuple[int, np.ndarray]:
+ wav = np.asarray(wav, dtype=np.float32)
+ return sr, wav
+
+
+def _detect_model_kind(ckpt: str, tts: Qwen3TTSModel) -> str:
+ mt = getattr(tts.model, "tts_model_type", None)
+ if mt in ("custom_voice", "voice_design", "base"):
+ return mt
+ else:
+ raise ValueError(f"Unknown Qwen-TTS model type: {mt}")
+
+
+def build_demo(tts: Qwen3TTSModel, ckpt: str, gen_kwargs_default: Dict[str, Any]) -> gr.Blocks:
+ model_kind = _detect_model_kind(ckpt, tts)
+
+ supported_langs_raw = None
+ if callable(getattr(tts.model, "get_supported_languages", None)):
+ supported_langs_raw = tts.model.get_supported_languages()
+
+ supported_spks_raw = None
+ if callable(getattr(tts.model, "get_supported_speakers", None)):
+ supported_spks_raw = tts.model.get_supported_speakers()
+
+ lang_choices_disp, lang_map = _build_choices_and_map([x for x in (supported_langs_raw or [])])
+ spk_choices_disp, spk_map = _build_choices_and_map([x for x in (supported_spks_raw or [])])
+
+ def _gen_common_kwargs() -> Dict[str, Any]:
+ return dict(gen_kwargs_default)
+
+ theme = gr.themes.Soft(
+ font=[gr.themes.GoogleFont("Source Sans Pro"), "Arial", "sans-serif"],
+ )
+
+ css = ".gradio-container {max-width: none !important;}"
+
+ with gr.Blocks(theme=theme, css=css) as demo:
+ gr.Markdown(
+ f"""
+# Qwen3 TTS Demo
+**Checkpoint:** `{ckpt}`
+**Model Type:** `{model_kind}`
+"""
+ )
+
+ if model_kind == "custom_voice":
+ with gr.Row():
+ with gr.Column(scale=2):
+ text_in = gr.Textbox(
+ label="Text (待合成文本)",
+ lines=4,
+ placeholder="Enter text to synthesize (输入要合成的文本).",
+ )
+ with gr.Row():
+ lang_in = gr.Dropdown(
+ label="Language (语种)",
+ choices=lang_choices_disp,
+ value="Auto",
+ interactive=True,
+ )
+ spk_in = gr.Dropdown(
+ label="Speaker (说话人)",
+ choices=spk_choices_disp,
+ value="Vivian",
+ interactive=True,
+ )
+ instruct_in = gr.Textbox(
+ label="Instruction (Optional) (控制指令,可不输入)",
+ lines=2,
+ placeholder="e.g. Say it in a very angry tone (例如:用特别伤心的语气说).",
+ )
+ btn = gr.Button("Generate (生成)", variant="primary")
+ with gr.Column(scale=3):
+ audio_out = gr.Audio(label="Output Audio (合成结果)", type="numpy")
+ err = gr.Textbox(label="Status (状态)", lines=2)
+
+ def run_instruct(text: str, lang_disp: str, spk_disp: str, instruct: str):
+ try:
+ if not text or not text.strip():
+ return None, "Text is required (必须填写文本)."
+ if not spk_disp:
+ return None, "Speaker is required (必须选择说话人)."
+ language = lang_map.get(lang_disp, "Auto")
+ speaker = spk_map.get(spk_disp, spk_disp)
+ kwargs = _gen_common_kwargs()
+ wavs, sr = tts.generate_custom_voice(
+ text=text.strip(),
+ language=language,
+ speaker=speaker,
+ instruct=(instruct or "").strip() or None,
+ **kwargs,
+ )
+ return _wav_to_gradio_audio(wavs[0], sr), "Finished. (生成完成)"
+ except Exception as e:
+ return None, f"{type(e).__name__}: {e}"
+
+ btn.click(run_instruct, inputs=[text_in, lang_in, spk_in, instruct_in], outputs=[audio_out, err])
+
+ elif model_kind == "voice_design":
+ with gr.Row():
+ with gr.Column(scale=2):
+ text_in = gr.Textbox(
+ label="Text (待合成文本)",
+ lines=4,
+ value="It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there!"
+ )
+ with gr.Row():
+ lang_in = gr.Dropdown(
+ label="Language (语种)",
+ choices=lang_choices_disp,
+ value="Auto",
+ interactive=True,
+ )
+ design_in = gr.Textbox(
+ label="Voice Design Instruction (音色描述)",
+ lines=3,
+ value="Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice."
+ )
+ btn = gr.Button("Generate (生成)", variant="primary")
+ with gr.Column(scale=3):
+ audio_out = gr.Audio(label="Output Audio (合成结果)", type="numpy")
+ err = gr.Textbox(label="Status (状态)", lines=2)
+
+ def run_voice_design(text: str, lang_disp: str, design: str):
+ try:
+ if not text or not text.strip():
+ return None, "Text is required (必须填写文本)."
+ if not design or not design.strip():
+ return None, "Voice design instruction is required (必须填写音色描述)."
+ language = lang_map.get(lang_disp, "Auto")
+ kwargs = _gen_common_kwargs()
+ wavs, sr = tts.generate_voice_design(
+ text=text.strip(),
+ language=language,
+ instruct=design.strip(),
+ **kwargs,
+ )
+ return _wav_to_gradio_audio(wavs[0], sr), "Finished. (生成完成)"
+ except Exception as e:
+ return None, f"{type(e).__name__}: {e}"
+
+ btn.click(run_voice_design, inputs=[text_in, lang_in, design_in], outputs=[audio_out, err])
+
+ else: # voice_clone for base
+ with gr.Tabs():
+ with gr.Tab("Clone & Generate (克隆并合成)"):
+ with gr.Row():
+ with gr.Column(scale=2):
+ ref_audio = gr.Audio(
+ label="Reference Audio (参考音频)",
+ )
+ ref_text = gr.Textbox(
+ label="Reference Text (参考音频文本)",
+ lines=2,
+ placeholder="Required if not set use x-vector only (不勾选use x-vector only时必填).",
+ )
+ xvec_only = gr.Checkbox(
+ label="Use x-vector only (仅用说话人向量,效果有限,但不用传入参考音频文本)",
+ value=False,
+ )
+
+ with gr.Column(scale=2):
+ text_in = gr.Textbox(
+ label="Target Text (待合成文本)",
+ lines=4,
+ placeholder="Enter text to synthesize (输入要合成的文本).",
+ )
+ lang_in = gr.Dropdown(
+ label="Language (语种)",
+ choices=lang_choices_disp,
+ value="Auto",
+ interactive=True,
+ )
+ btn = gr.Button("Generate (生成)", variant="primary")
+
+ with gr.Column(scale=3):
+ audio_out = gr.Audio(label="Output Audio (合成结果)", type="numpy")
+ err = gr.Textbox(label="Status (状态)", lines=2)
+
+ def run_voice_clone(ref_aud, ref_txt: str, use_xvec: bool, text: str, lang_disp: str):
+ try:
+ if not text or not text.strip():
+ return None, "Target text is required (必须填写待合成文本)."
+ at = _audio_to_tuple(ref_aud)
+ if at is None:
+ return None, "Reference audio is required (必须上传参考音频)."
+ if (not use_xvec) and (not ref_txt or not ref_txt.strip()):
+ return None, (
+ "Reference text is required when use x-vector only is NOT enabled.\n"
+ "(未勾选 use x-vector only 时,必须提供参考音频文本;否则请勾选 use x-vector only,但效果会变差.)"
+ )
+ language = lang_map.get(lang_disp, "Auto")
+ kwargs = _gen_common_kwargs()
+ wavs, sr = tts.generate_voice_clone(
+ text=text.strip(),
+ language=language,
+ ref_audio=at,
+ ref_text=(ref_txt.strip() if ref_txt else None),
+ x_vector_only_mode=bool(use_xvec),
+ **kwargs,
+ )
+ return _wav_to_gradio_audio(wavs[0], sr), "Finished. (生成完成)"
+ except Exception as e:
+ return None, f"{type(e).__name__}: {e}"
+
+ btn.click(
+ run_voice_clone,
+ inputs=[ref_audio, ref_text, xvec_only, text_in, lang_in],
+ outputs=[audio_out, err],
+ )
+
+ with gr.Tab("Save / Load Voice (保存/加载克隆音色)"):
+ with gr.Row():
+ with gr.Column(scale=2):
+ gr.Markdown(
+ """
+### Save Voice (保存音色)
+Upload reference audio and text, choose use x-vector only or not, then save a reusable voice prompt file.
+(上传参考音频和参考文本,选择是否使用 use x-vector only 模式后保存为可复用的音色文件)
+"""
+ )
+ ref_audio_s = gr.Audio(label="Reference Audio (参考音频)", type="numpy")
+ ref_text_s = gr.Textbox(
+ label="Reference Text (参考音频文本)",
+ lines=2,
+ placeholder="Required if not set use x-vector only (不勾选use x-vector only时必填).",
+ )
+ xvec_only_s = gr.Checkbox(
+ label="Use x-vector only (仅用说话人向量,效果有限,但不用传入参考音频文本)",
+ value=False,
+ )
+ save_btn = gr.Button("Save Voice File (保存音色文件)", variant="primary")
+ prompt_file_out = gr.File(label="Voice File (音色文件)")
+
+ with gr.Column(scale=2):
+ gr.Markdown(
+ """
+### Load Voice & Generate (加载音色并合成)
+Upload a previously saved voice file, then synthesize new text.
+(上传已保存提示文件后,输入新文本进行合成)
+"""
+ )
+ prompt_file_in = gr.File(label="Upload Prompt File (上传提示文件)")
+ text_in2 = gr.Textbox(
+ label="Target Text (待合成文本)",
+ lines=4,
+ placeholder="Enter text to synthesize (输入要合成的文本).",
+ )
+ lang_in2 = gr.Dropdown(
+ label="Language (语种)",
+ choices=lang_choices_disp,
+ value="Auto",
+ interactive=True,
+ )
+ gen_btn2 = gr.Button("Generate (生成)", variant="primary")
+
+ with gr.Column(scale=3):
+ audio_out2 = gr.Audio(label="Output Audio (合成结果)", type="numpy")
+ err2 = gr.Textbox(label="Status (状态)", lines=2)
+
+ def save_prompt(ref_aud, ref_txt: str, use_xvec: bool):
+ try:
+ at = _audio_to_tuple(ref_aud)
+ if at is None:
+ return None, "Reference audio is required (必须上传参考音频)."
+ if (not use_xvec) and (not ref_txt or not ref_txt.strip()):
+ return None, (
+ "Reference text is required when use x-vector only is NOT enabled.\n"
+ "(未勾选 use x-vector only 时,必须提供参考音频文本;否则请勾选 use x-vector only,但效果会变差.)"
+ )
+ items = tts.create_voice_clone_prompt(
+ ref_audio=at,
+ ref_text=(ref_txt.strip() if ref_txt else None),
+ x_vector_only_mode=bool(use_xvec),
+ )
+ payload = {
+ "items": [asdict(it) for it in items],
+ }
+ fd, out_path = tempfile.mkstemp(prefix="voice_clone_prompt_", suffix=".pt")
+ os.close(fd)
+ torch.save(payload, out_path)
+ return out_path, "Finished. (生成完成)"
+ except Exception as e:
+ return None, f"{type(e).__name__}: {e}"
+
+ def load_prompt_and_gen(file_obj, text: str, lang_disp: str):
+ try:
+ if file_obj is None:
+ return None, "Voice file is required (必须上传音色文件)."
+ if not text or not text.strip():
+ return None, "Target text is required (必须填写待合成文本)."
+
+ path = getattr(file_obj, "name", None) or getattr(file_obj, "path", None) or str(file_obj)
+ payload = torch.load(path, map_location="cpu", weights_only=True)
+ if not isinstance(payload, dict) or "items" not in payload:
+ return None, "Invalid file format (文件格式不正确)."
+
+ items_raw = payload["items"]
+ if not isinstance(items_raw, list) or len(items_raw) == 0:
+ return None, "Empty voice items (音色为空)."
+
+ items: List[VoiceClonePromptItem] = []
+ for d in items_raw:
+ if not isinstance(d, dict):
+ return None, "Invalid item format in file (文件内部格式错误)."
+ ref_code = d.get("ref_code", None)
+ if ref_code is not None and not torch.is_tensor(ref_code):
+ ref_code = torch.tensor(ref_code)
+ ref_spk = d.get("ref_spk_embedding", None)
+ if ref_spk is None:
+ return None, "Missing ref_spk_embedding (缺少说话人向量)."
+ if not torch.is_tensor(ref_spk):
+ ref_spk = torch.tensor(ref_spk)
+
+ items.append(
+ VoiceClonePromptItem(
+ ref_code=ref_code,
+ ref_spk_embedding=ref_spk,
+ x_vector_only_mode=bool(d.get("x_vector_only_mode", False)),
+ icl_mode=bool(d.get("icl_mode", not bool(d.get("x_vector_only_mode", False)))),
+ ref_text=d.get("ref_text", None),
+ )
+ )
+
+ language = lang_map.get(lang_disp, "Auto")
+ kwargs = _gen_common_kwargs()
+ wavs, sr = tts.generate_voice_clone(
+ text=text.strip(),
+ language=language,
+ voice_clone_prompt=items,
+ **kwargs,
+ )
+ return _wav_to_gradio_audio(wavs[0], sr), "Finished. (生成完成)"
+ except Exception as e:
+ return None, (
+ f"Failed to read or use voice file. Check file format/content.\n"
+ f"(读取或使用音色文件失败,请检查文件格式或内容)\n"
+ f"{type(e).__name__}: {e}"
+ )
+
+ save_btn.click(save_prompt, inputs=[ref_audio_s, ref_text_s, xvec_only_s], outputs=[prompt_file_out, err2])
+ gen_btn2.click(load_prompt_and_gen, inputs=[prompt_file_in, text_in2, lang_in2], outputs=[audio_out2, err2])
+
+ gr.Markdown(
+ """
+**Disclaimer (免责声明)**
+- The audio is automatically generated/synthesized by an AI model solely to demonstrate the model’s capabilities; it may be inaccurate or inappropriate, does not represent the views of the developer/operator, and does not constitute professional advice. You are solely responsible for evaluating, using, distributing, or relying on this audio; to the maximum extent permitted by applicable law, the developer/operator disclaims liability for any direct, indirect, incidental, or consequential damages arising from the use of or inability to use the audio, except where liability cannot be excluded by law. Do not use this service to intentionally generate or replicate unlawful, harmful, defamatory, fraudulent, deepfake, or privacy/publicity/copyright/trademark‑infringing content; if a user prompts, supplies materials, or otherwise facilitates any illegal or infringing conduct, the user bears all legal consequences and the developer/operator is not responsible.
+- 音频由人工智能模型自动生成/合成,仅用于体验与展示模型效果,可能存在不准确或不当之处;其内容不代表开发者/运营方立场,亦不构成任何专业建议。用户应自行评估并承担使用、传播或依赖该音频所产生的一切风险与责任;在适用法律允许的最大范围内,开发者/运营方不对因使用或无法使用本音频造成的任何直接、间接、附带或后果性损失承担责任(法律另有强制规定的除外)。严禁利用本服务故意引导生成或复制违法、有害、诽谤、欺诈、深度伪造、侵犯隐私/肖像/著作权/商标等内容;如用户通过提示词、素材或其他方式实施或促成任何违法或侵权行为,相关法律后果由用户自行承担,与开发者/运营方无关。
+"""
+ )
+
+ return demo
+
+
+def main(argv=None) -> int:
+ parser = build_parser()
+ args = parser.parse_args(argv)
+
+ if not args.checkpoint and not args.checkpoint_pos:
+ parser.print_help()
+ return 0
+
+ ckpt = _resolve_checkpoint(args)
+
+ dtype = _dtype_from_str(args.dtype)
+ attn_impl = "flash_attention_2" if args.flash_attn else None
+
+ tts = Qwen3TTSModel.from_pretrained(
+ ckpt,
+ device_map=args.device,
+ dtype=dtype,
+ attn_implementation=attn_impl,
+ )
+
+ gen_kwargs_default = _collect_gen_kwargs(args)
+ demo = build_demo(tts, ckpt, gen_kwargs_default)
+
+ launch_kwargs: Dict[str, Any] = dict(
+ server_name=args.ip,
+ server_port=args.port,
+ share=args.share,
+ ssl_verify=True if args.ssl_verify else False,
+ )
+ if args.ssl_certfile is not None:
+ launch_kwargs["ssl_certfile"] = args.ssl_certfile
+ if args.ssl_keyfile is not None:
+ launch_kwargs["ssl_keyfile"] = args.ssl_keyfile
+
+ demo.queue(default_concurrency_limit=int(args.concurrency)).launch(**launch_kwargs)
+ return 0
+
+
+if __name__ == "__main__":
+ raise SystemExit(main())
diff --git a/models/Qwen3-TTS/qwen_tts/core/__init__.py b/models/Qwen3-TTS/qwen_tts/core/__init__.py
new file mode 100644
index 0000000..6664236
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/__init__.py
@@ -0,0 +1,19 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .tokenizer_25hz.configuration_qwen3_tts_tokenizer_v1 import Qwen3TTSTokenizerV1Config
+from .tokenizer_25hz.modeling_qwen3_tts_tokenizer_v1 import Qwen3TTSTokenizerV1Model
+from .tokenizer_12hz.configuration_qwen3_tts_tokenizer_v2 import Qwen3TTSTokenizerV2Config
+from .tokenizer_12hz.modeling_qwen3_tts_tokenizer_v2 import Qwen3TTSTokenizerV2Model
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/core/models/__init__.py b/models/Qwen3-TTS/qwen_tts/core/models/__init__.py
new file mode 100644
index 0000000..f376f68
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/models/__init__.py
@@ -0,0 +1,18 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .configuration_qwen3_tts import Qwen3TTSConfig
+from .modeling_qwen3_tts import Qwen3TTSForConditionalGeneration
+from .processing_qwen3_tts import Qwen3TTSProcessor
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/core/models/configuration_qwen3_tts.py b/models/Qwen3-TTS/qwen_tts/core/models/configuration_qwen3_tts.py
new file mode 100644
index 0000000..0bd426d
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/models/configuration_qwen3_tts.py
@@ -0,0 +1,502 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from transformers.configuration_utils import PretrainedConfig, layer_type_validation
+from transformers.modeling_rope_utils import rope_config_validation
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+
+class Qwen3TTSSpeakerEncoderConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen3TTSSpeakerEncoder`].
+ It is used to instantiate a Qwen3TTS speaker encoder model according to the specified arguments, defining the model
+ architecture. The architecture is based on the ECAPA-TDNN model.
+
+ Args:
+ mel_dim (`int`, *optional*, defaults to 128):
+ The dimension of the input mel-spectrogram.
+ enc_dim (`int`, *optional*, defaults to 192):
+ The dimension of the final speaker embedding.
+ enc_channels (`list[int]`, *optional*, defaults to `[512, 512, 512, 512, 1536]`):
+ A list of output channels for each TDNN/SERes2Net layer in the encoder. The first channel size is for the initial TDNN layer,
+ the intermediate ones for the `SqueezeExcitationRes2NetBlock` layers, and the last one for the multi-layer feature aggregation.
+ enc_kernel_sizes (`list[int]`, *optional*, defaults to `[5, 3, 3, 3, 1]`):
+ A list of kernel sizes for each layer in the encoder, corresponding to `enc_channels`.
+ enc_dilations (`list[int]`, *optional*, defaults to `[1, 2, 3, 4, 1]`):
+ A list of dilations for each layer in the encoder, corresponding to `enc_channels`.
+ enc_attention_channels (`int`, *optional*, defaults to 128):
+ The number of attention channels in the `AttentiveStatisticsPooling` layer.
+ enc_res2net_scale (`int`, *optional*,defaults to 8):
+ The scale of the `Res2NetBlock` in the encoder.
+ enc_se_channels (`int`, *optional*, defaults to 128):
+ The number of channels in the squeeze part of the `SqueezeExcitationBlock`.
+ """
+ def __init__(
+ self,
+ mel_dim=128,
+ enc_dim=1024,
+ enc_channels=[512, 512, 512, 512, 1536],
+ enc_kernel_sizes=[5, 3, 3, 3, 1],
+ enc_dilations=[1, 2, 3, 4, 1],
+ enc_attention_channels=128,
+ enc_res2net_scale=8,
+ enc_se_channels=128,
+ sample_rate=24000,
+ ):
+ self.mel_dim = mel_dim
+ self.enc_dim = enc_dim
+ self.enc_channels = enc_channels
+ self.enc_kernel_sizes = enc_kernel_sizes
+ self.enc_dilations = enc_dilations
+ self.enc_attention_channels = enc_attention_channels
+ self.enc_res2net_scale = enc_res2net_scale
+ self.enc_se_channels = enc_se_channels
+ self.sample_rate = sample_rate
+
+
+class Qwen3TTSTalkerCodePredictorConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen3TTSTalkerCodePredictorModel`]. It is used to instantiate a
+ Qwen3TTSTalkerCodePredictor model according to the specified arguments, defining the model architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 151936):
+ Vocabulary size of the Qwen3TTSTalkerCodePredictor model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`Qwen3TTSTalkerCodePredictorModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 22016):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 32):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details, check out [this
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
+ head_dim (`int`, *optional*, defaults to 128):
+ The attention head dimension.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 32768):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
+ and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
+ accordingly.
+ Expected contents:
+ `rope_type` (`str`):
+ The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
+ 'llama3'], with 'default' being the original RoPE implementation.
+ `factor` (`float`, *optional*):
+ Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
+ most scaling types, a `factor` of x will enable the model to handle sequences of length x *
+ original maximum pre-trained length.
+ `original_max_position_embeddings` (`int`, *optional*):
+ Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
+ pretraining.
+ `attention_factor` (`float`, *optional*):
+ Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
+ computation. If unspecified, it defaults to value recommended by the implementation, using the
+ `factor` field to infer the suggested value.
+ `beta_fast` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
+ ramp function. If unspecified, it defaults to 32.
+ `beta_slow` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
+ ramp function. If unspecified, it defaults to 1.
+ `short_factor` (`list[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to short contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `long_factor` (`list[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to long contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `low_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
+ `high_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
+ attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ use_sliding_window (`bool`, *optional*, defaults to `False`):
+ Whether to use sliding window attention.
+ sliding_window (`int`, *optional*, defaults to 4096):
+ Sliding window attention (SWA) window size. If not specified, will default to `4096`.
+ max_window_layers (`int`, *optional*, defaults to 28):
+ The number of layers using full attention. The first `max_window_layers` layers will use full attention, while any
+ additional layer afterwards will use SWA (Sliding Window Attention).
+ layer_types (`list`, *optional*):
+ Attention pattern for each layer.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+
+ """
+
+ model_type = "qwen3_tts_talker_code_predictor"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ # Default tensor parallel plan for base model `Qwen3TTSTalkerCodePredictor`
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+
+ def __init__(
+ self,
+ vocab_size=2048,
+ hidden_size=1024,
+ intermediate_size=3072,
+ num_hidden_layers=5,
+ num_attention_heads=16,
+ num_key_value_heads=8,
+ head_dim=128,
+ hidden_act="silu",
+ max_position_embeddings=32768,
+ initializer_range=0.02,
+ rms_norm_eps=0.000001,
+ use_cache=True,
+ tie_word_embeddings=False,
+ rope_theta=10000,
+ rope_scaling=None,
+ attention_bias=False,
+ use_sliding_window=False,
+ sliding_window=4096,
+ max_window_layers=28,
+ layer_types=None,
+ attention_dropout=0,
+ num_code_groups=32,
+ **kwargs,
+ ):
+ super().__init__(
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window if self.use_sliding_window else None
+ self.max_window_layers = max_window_layers
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.head_dim = head_dim
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ # Validate the correctness of rotary position embeddings parameters
+ # BC: if there is a 'type' field, move it to 'rope_type'.
+ if self.rope_scaling is not None and "type" in self.rope_scaling:
+ self.rope_scaling["rope_type"] = self.rope_scaling["type"]
+ rope_config_validation(self)
+
+ self.layer_types = layer_types
+ if self.layer_types is None:
+ self.layer_types = [
+ "sliding_attention"
+ if self.sliding_window is not None and i >= self.max_window_layers
+ else "full_attention"
+ for i in range(self.num_hidden_layers)
+ ]
+ layer_type_validation(self.layer_types)
+ self.num_code_groups = num_code_groups
+
+
+class Qwen3TTSTalkerConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen3TTSTalkerModel`]. It is used to instantiate a
+ Qwen3TTSTalker model according to the specified arguments, defining the model architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 151936):
+ Vocabulary size of the Qwen3TTSTalker model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`Qwen3TTSTalkerModel`]
+ hidden_size (`int`, *optional*, defaults to 2048):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 6144):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 4):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details, check out [this
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
+
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 32768):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
+ and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
+ accordingly.
+ Expected contents:
+ `rope_type` (`str`):
+ The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
+ 'llama3'], with 'default' being the original RoPE implementation.
+ `factor` (`float`, *optional*):
+ Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
+ most scaling types, a `factor` of x will enable the model to handle sequences of length x *
+ original maximum pre-trained length.
+ `original_max_position_embeddings` (`int`, *optional*):
+ Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
+ pretraining.
+ `attention_factor` (`float`, *optional*):
+ Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
+ computation. If unspecified, it defaults to value recommended by the implementation, using the
+ `factor` field to infer the suggested value.
+ `beta_fast` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
+ ramp function. If unspecified, it defaults to 32.
+ `beta_slow` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
+ ramp function. If unspecified, it defaults to 1.
+ `short_factor` (`list[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to short contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `long_factor` (`list[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to long contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `low_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
+ `high_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
+ attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ use_sliding_window (`bool`, *optional*, defaults to `False`):
+ Whether to use sliding window attention.
+ sliding_window (`int`, *optional*, defaults to 4096):
+ Sliding window attention (SWA) window size. If not specified, will default to `4096`.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ """
+
+ model_type = "qwen3_tts_talker"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ # Default tensor parallel plan for base model `Qwen3TTSTalker`
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+ sub_configs = {"code_predictor_config": Qwen3TTSTalkerCodePredictorConfig}
+
+ def __init__(
+ self,
+ code_predictor_config=None,
+ vocab_size=3072,
+ hidden_size=1024,
+ intermediate_size=2048,
+ num_hidden_layers=20,
+ num_attention_heads=16,
+ num_key_value_heads=2,
+ hidden_act="silu",
+ max_position_embeddings=32768,
+ initializer_range=0.02,
+ rms_norm_eps=0.000001,
+ use_cache=True,
+ tie_word_embeddings=False,
+ rope_theta=10000,
+ rope_scaling=None,
+ attention_bias=False,
+ use_sliding_window=False,
+ sliding_window=4096,
+ attention_dropout=0,
+ num_code_groups=32,
+ text_hidden_size=2048,
+ codec_eos_token_id=4198,
+ codec_think_id=4202,
+ codec_nothink_id=4203,
+ codec_think_bos_id=4204,
+ codec_think_eos_id=4205,
+ codec_pad_id=4196,
+ codec_bos_id=4197,
+ spk_id=None,
+ spk_is_dialect=None,
+ codec_language_id=None,
+ **kwargs,
+ ):
+ super().__init__(
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window if use_sliding_window else None
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ # Validate the correctness of rotary position embeddings parameters
+ # BC: if there is a 'type' field, move it to 'rope_type'.
+ if self.rope_scaling is not None and "type" in self.rope_scaling:
+ self.rope_scaling["rope_type"] = self.rope_scaling["type"]
+
+ if code_predictor_config is None:
+ code_predictor_config = {}
+ self.code_predictor_config = Qwen3TTSTalkerCodePredictorConfig()
+ logger.info("code_predictor_config is None. Initializing code_predictor model with default values")
+ elif isinstance(code_predictor_config, Qwen3TTSTalkerCodePredictorConfig):
+ self.code_predictor_config = code_predictor_config
+ else:
+ self.code_predictor_config = Qwen3TTSTalkerCodePredictorConfig(**code_predictor_config)
+ self.num_code_groups = num_code_groups
+ self.text_hidden_size = text_hidden_size
+ self.codec_eos_token_id = codec_eos_token_id
+ self.codec_think_id = codec_think_id
+ self.codec_language_id = codec_language_id
+ self.codec_nothink_id = codec_nothink_id
+ self.codec_think_bos_id = codec_think_bos_id
+ self.codec_think_eos_id = codec_think_eos_id
+ self.codec_pad_id = codec_pad_id
+ self.codec_bos_id = codec_bos_id
+ self.spk_id = spk_id
+ self.spk_is_dialect = spk_is_dialect
+
+
+class Qwen3TTSConfig(PretrainedConfig):
+ """
+ This is the configuration class to store the configuration of a [`Qwen3TTSForConditionalGeneration`].
+ """
+
+ model_type = "qwen3_tts"
+ sub_configs = {
+ "talker_config": Qwen3TTSTalkerConfig,
+ "speaker_encoder_config": Qwen3TTSSpeakerEncoderConfig,
+ }
+
+ def __init__(
+ self,
+ talker_config=None,
+ speaker_encoder_config=None,
+ tokenizer_type=None,
+ tts_model_size=None,
+ tts_model_type=None,
+ im_start_token_id=151644,
+ im_end_token_id=151645,
+ tts_pad_token_id=151671,
+ tts_bos_token_id=151672,
+ tts_eos_token_id=151673,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if talker_config is None:
+ talker_config = {}
+ logger.info("talker_config is None. Initializing talker model with default values")
+ if speaker_encoder_config is None:
+ speaker_encoder_config = {}
+ logger.info("speaker_encoder_config is None. Initializing talker model with default values")
+
+ self.talker_config = Qwen3TTSTalkerConfig(**talker_config)
+ self.speaker_encoder_config = Qwen3TTSSpeakerEncoderConfig(**speaker_encoder_config)
+
+ self.tokenizer_type = tokenizer_type
+ self.tts_model_size = tts_model_size
+ self.tts_model_type = tts_model_type
+
+ self.im_start_token_id = im_start_token_id
+ self.im_end_token_id = im_end_token_id
+ self.tts_pad_token_id = tts_pad_token_id
+ self.tts_bos_token_id = tts_bos_token_id
+ self.tts_eos_token_id = tts_eos_token_id
+
+
+__all__ = ["Qwen3TTSConfig", "Qwen3TTSTalkerConfig", "Qwen3TTSSpeakerEncoderConfig"]
diff --git a/models/Qwen3-TTS/qwen_tts/core/models/modeling_qwen3_tts.py b/models/Qwen3-TTS/qwen_tts/core/models/modeling_qwen3_tts.py
new file mode 100644
index 0000000..a3eb30a
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/models/modeling_qwen3_tts.py
@@ -0,0 +1,2299 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Qwen3TTS model."""
+
+import json
+import os
+from dataclasses import dataclass
+from typing import Callable, Optional
+
+import huggingface_hub
+import torch
+from huggingface_hub import snapshot_download
+from librosa.filters import mel as librosa_mel_fn
+from torch import nn
+from torch.nn import functional as F
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.generation import GenerationMixin
+from transformers.integrations import use_kernel_forward_from_hub
+from transformers.masking_utils import (create_causal_mask,
+ create_sliding_window_causal_mask)
+from transformers.modeling_flash_attention_utils import FlashAttentionKwargs
+from transformers.modeling_layers import GradientCheckpointingLayer
+from transformers.modeling_outputs import (BaseModelOutputWithPast,
+ CausalLMOutputWithPast, ModelOutput)
+from transformers.modeling_rope_utils import (ROPE_INIT_FUNCTIONS,
+ dynamic_rope_update)
+from transformers.modeling_utils import (ALL_ATTENTION_FUNCTIONS,
+ PreTrainedModel)
+from transformers.processing_utils import Unpack
+from transformers.utils import can_return_tuple, logging
+from transformers.utils.hub import cached_file
+
+from ...inference.qwen3_tts_tokenizer import Qwen3TTSTokenizer
+from .configuration_qwen3_tts import (Qwen3TTSConfig,
+ Qwen3TTSSpeakerEncoderConfig,
+ Qwen3TTSTalkerCodePredictorConfig,
+ Qwen3TTSTalkerConfig)
+
+logger = logging.get_logger(__name__)
+
+
+def download_weights_from_hf_specific(
+ model_name_or_path: str,
+ cache_dir: str | None,
+ allow_patterns: list[str],
+ revision: str | None = None,
+ ignore_patterns: str | list[str] | None = None,
+) -> str:
+ """Download model weights from Hugging Face Hub. Users can specify the
+ allow_patterns to download only the necessary weights.
+
+ Args:
+ model_name_or_path (str): The model name or path.
+ cache_dir (Optional[str]): The cache directory to store the model
+ weights. If None, will use HF defaults.
+ allow_patterns (list[str]): The allowed patterns for the
+ weight files. Files matched by any of the patterns will be
+ downloaded.
+ revision (Optional[str]): The revision of the model.
+ ignore_patterns (Optional[Union[str, list[str]]]): The patterns to
+ filter out the weight files. Files matched by any of the patterns
+ will be ignored.
+
+ Returns:
+ str: The path to the downloaded model weights.
+ """
+ assert len(allow_patterns) > 0
+ local_only = huggingface_hub.constants.HF_HUB_OFFLINE
+
+ for allow_pattern in allow_patterns:
+ hf_folder = snapshot_download(
+ model_name_or_path,
+ allow_patterns=allow_pattern,
+ ignore_patterns=ignore_patterns,
+ cache_dir=cache_dir,
+ revision=revision,
+ local_files_only=local_only,
+ )
+ return hf_folder
+
+
+class Res2NetBlock(torch.nn.Module):
+ def __init__(self, in_channels, out_channels, scale=8, kernel_size=3, dilation=1):
+ super().__init__()
+
+ in_channel = in_channels // scale
+ hidden_channel = out_channels // scale
+
+ self.blocks = nn.ModuleList(
+ [
+ TimeDelayNetBlock(
+ in_channel,
+ hidden_channel,
+ kernel_size=kernel_size,
+ dilation=dilation,
+ )
+ for i in range(scale - 1)
+ ]
+ )
+ self.scale = scale
+
+ def forward(self, hidden_states):
+ outputs = []
+ for i, hidden_part in enumerate(torch.chunk(hidden_states, self.scale, dim=1)):
+ if i == 0:
+ output_part = hidden_part
+ elif i == 1:
+ output_part = self.blocks[i - 1](hidden_part)
+ else:
+ output_part = self.blocks[i - 1](hidden_part + output_part)
+ outputs.append(output_part)
+ output = torch.cat(outputs, dim=1)
+ return output
+
+
+class SqueezeExcitationBlock(nn.Module):
+ def __init__(self, in_channels, se_channels, out_channels):
+ super().__init__()
+
+ self.conv1 = nn.Conv1d(
+ in_channels=in_channels,
+ out_channels=se_channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.relu = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv1d(
+ in_channels=se_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.sigmoid = nn.Sigmoid()
+
+ def forward(self, hidden_states):
+ hidden_states_mean = hidden_states.mean(dim=2, keepdim=True)
+
+ hidden_states_mean = self.relu(self.conv1(hidden_states_mean))
+ hidden_states_mean = self.sigmoid(self.conv2(hidden_states_mean))
+
+ return hidden_states * hidden_states_mean
+
+
+class AttentiveStatisticsPooling(nn.Module):
+ """This class implements an attentive statistic pooling layer for each channel.
+ It returns the concatenated mean and std of the input tensor.
+ """
+
+ def __init__(self, channels, attention_channels=128):
+ super().__init__()
+
+ self.eps = 1e-12
+ self.tdnn = TimeDelayNetBlock(channels * 3, attention_channels, 1, 1)
+ self.tanh = nn.Tanh()
+ self.conv = nn.Conv1d(
+ in_channels=attention_channels,
+ out_channels=channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+
+ def _length_to_mask(self, length, max_len=None, dtype=None, device=None):
+ """Creates a binary mask for each sequence.
+
+ Reference: https://discuss.pytorch.org/t/how-to-generate-variable-length-mask/23397/3
+
+ Arguments
+ ---------
+ length : torch.LongTensor
+ Containing the length of each sequence in the batch. Must be 1D.
+ max_len : int
+ Max length for the mask, also the size of the second dimension.
+ dtype : torch.dtype, default: None
+ The dtype of the generated mask.
+ device: torch.device, default: None
+ The device to put the mask variable.
+
+ Returns
+ -------
+ mask : tensor
+ The binary mask.
+ """
+
+ if max_len is None:
+ max_len = length.max().long().item() # using arange to generate mask
+ mask = torch.arange(max_len, device=length.device, dtype=length.dtype).expand(
+ len(length), max_len
+ ) < length.unsqueeze(1)
+
+ mask = torch.as_tensor(mask, dtype=dtype, device=device)
+ return mask
+
+ def _compute_statistics(self, x, m, dim=2):
+ mean = (m * x).sum(dim)
+ std = torch.sqrt((m * (x - mean.unsqueeze(dim)).pow(2)).sum(dim).clamp(self.eps))
+ return mean, std
+
+ def forward(self, hidden_states):
+ seq_length = hidden_states.shape[-1]
+ lengths = torch.ones(hidden_states.shape[0], device=hidden_states.device)
+
+ # Make binary mask of shape [N, 1, L]
+ mask = self._length_to_mask(
+ lengths * seq_length, max_len=seq_length, dtype=hidden_states.dtype, device=hidden_states.device
+ )
+ mask = mask.unsqueeze(1)
+
+ # Expand the temporal context of the pooling layer by allowing the
+ # self-attention to look at global properties of the utterance.
+ total = mask.sum(dim=2, keepdim=True)
+
+ mean, std = self._compute_statistics(hidden_states, mask / total)
+ mean = mean.unsqueeze(2).repeat(1, 1, seq_length)
+ std = std.unsqueeze(2).repeat(1, 1, seq_length)
+ attention = torch.cat([hidden_states, mean, std], dim=1)
+
+ # Apply layers
+ attention = self.conv(self.tanh(self.tdnn(attention)))
+
+ # Filter out zero-paddings
+ attention = attention.masked_fill(mask == 0, float("-inf"))
+
+ attention = F.softmax(attention, dim=2)
+ mean, std = self._compute_statistics(hidden_states, attention)
+ # Append mean and std of the batch
+ pooled_stats = torch.cat((mean, std), dim=1)
+ pooled_stats = pooled_stats.unsqueeze(2)
+
+ return pooled_stats
+
+class TimeDelayNetBlock(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ dilation,
+ ):
+ super().__init__()
+ self.conv = nn.Conv1d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.activation = nn.ReLU()
+
+ def forward(self, hidden_states: torch.Tensor):
+ return self.activation(self.conv(hidden_states))
+
+class SqueezeExcitationRes2NetBlock(nn.Module):
+ """An implementation of building block in ECAPA-TDNN, i.e.,
+ TDNN-Res2Net-TDNN-SqueezeExcitationBlock.
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ res2net_scale=8,
+ se_channels=128,
+ kernel_size=1,
+ dilation=1,
+ ):
+ super().__init__()
+ self.out_channels = out_channels
+ self.tdnn1 = TimeDelayNetBlock(
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ dilation=1,
+ )
+ self.res2net_block = Res2NetBlock(out_channels, out_channels, res2net_scale, kernel_size, dilation)
+ self.tdnn2 = TimeDelayNetBlock(
+ out_channels,
+ out_channels,
+ kernel_size=1,
+ dilation=1,
+ )
+ self.se_block = SqueezeExcitationBlock(out_channels, se_channels, out_channels)
+
+ def forward(self, hidden_state):
+ residual = hidden_state
+
+ hidden_state = self.tdnn1(hidden_state)
+ hidden_state = self.res2net_block(hidden_state)
+ hidden_state = self.tdnn2(hidden_state)
+ hidden_state = self.se_block(hidden_state)
+
+ return hidden_state + residual
+
+
+class Qwen3TTSSpeakerEncoder(torch.nn.Module):
+ """An implementation of the speaker embedding model in a paper.
+ "ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in
+ TDNN Based Speaker Verification" (https://huggingface.co/papers/2005.07143).
+ Use for Qwen3TTS extract speaker embedding.
+ """
+
+ def __init__(self, config: Qwen3TTSSpeakerEncoderConfig):
+ super().__init__()
+ if len(config.enc_channels) != len(config.enc_kernel_sizes) or len(config.enc_channels) != len(
+ config.enc_dilations
+ ):
+ raise ValueError("enc_channels, enc_kernel_sizes and enc_dilations should have same length")
+ self.channels = config.enc_channels
+ self.blocks = nn.ModuleList()
+
+ # The initial TDNN layer
+ self.blocks.append(
+ TimeDelayNetBlock(
+ config.mel_dim,
+ config.enc_channels[0],
+ config.enc_kernel_sizes[0],
+ config.enc_dilations[0],
+ )
+ )
+
+ # SE-Res2Net layers
+ for i in range(1, len(config.enc_channels) - 1):
+ self.blocks.append(
+ SqueezeExcitationRes2NetBlock(
+ config.enc_channels[i - 1],
+ config.enc_channels[i],
+ res2net_scale=config.enc_res2net_scale,
+ se_channels=config.enc_se_channels,
+ kernel_size=config.enc_kernel_sizes[i],
+ dilation=config.enc_dilations[i],
+ )
+ )
+
+ # Multi-layer feature aggregation
+ self.mfa = TimeDelayNetBlock(
+ config.enc_channels[-1],
+ config.enc_channels[-1],
+ config.enc_kernel_sizes[-1],
+ config.enc_dilations[-1],
+ )
+
+ # Attentive Statistical Pooling
+ self.asp = AttentiveStatisticsPooling(
+ config.enc_channels[-1],
+ attention_channels=config.enc_attention_channels,
+ )
+
+ # Final linear transformation
+ self.fc = nn.Conv1d(
+ in_channels=config.enc_channels[-1] * 2,
+ out_channels=config.enc_dim,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+
+ def forward(self, hidden_states):
+ # Minimize transpose for efficiency
+ hidden_states = hidden_states.transpose(1, 2)
+
+ hidden_states_list = []
+ for layer in self.blocks:
+ hidden_states = layer(hidden_states)
+ hidden_states_list.append(hidden_states)
+
+ # Multi-layer feature aggregation
+ hidden_states = torch.cat(hidden_states_list[1:], dim=1)
+ hidden_states = self.mfa(hidden_states)
+
+ # Attentive Statistical Pooling
+ hidden_states = self.asp(hidden_states)
+
+ # Final linear transformation
+ hidden_states = self.fc(hidden_states)
+
+ hidden_states = hidden_states.squeeze(-1)
+ return hidden_states
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+def mel_spectrogram(
+ y: torch.Tensor,
+ n_fft: int,
+ num_mels: int,
+ sampling_rate: int,
+ hop_size: int,
+ win_size: int,
+ fmin: int,
+ fmax: int = None,
+ center: bool = False,
+) -> torch.Tensor:
+ """
+ Calculate the mel spectrogram of an input signal.
+ This function uses slaney norm for the librosa mel filterbank (using librosa.filters.mel) and uses Hann window for STFT (using torch.stft).
+
+ Args:
+ y (torch.Tensor): Input signal.
+ n_fft (int): FFT size.
+ num_mels (int): Number of mel bins.
+ sampling_rate (int): Sampling rate of the input signal.
+ hop_size (int): Hop size for STFT.
+ win_size (int): Window size for STFT.
+ fmin (int): Minimum frequency for mel filterbank.
+ fmax (int): Maximum frequency for mel filterbank. If None, defaults to half the sampling rate (fmax = sr / 2.0) inside librosa_mel_fn
+ center (bool): Whether to pad the input to center the frames. Default is False.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ if torch.min(y) < -1.0:
+ print(f"[WARNING] Min value of input waveform signal is {torch.min(y)}")
+ if torch.max(y) > 1.0:
+ print(f"[WARNING] Max value of input waveform signal is {torch.max(y)}")
+
+ device = y.device
+
+ mel = librosa_mel_fn(
+ sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax
+ )
+
+ mel_basis = torch.from_numpy(mel).float().to(device)
+ hann_window = torch.hann_window(win_size).to(device)
+
+ padding = (n_fft - hop_size) // 2
+ y = torch.nn.functional.pad(
+ y.unsqueeze(1), (padding, padding), mode="reflect"
+ ).squeeze(1)
+
+ spec = torch.stft(
+ y,
+ n_fft,
+ hop_length=hop_size,
+ win_length=win_size,
+ window=hann_window,
+ center=center,
+ pad_mode="reflect",
+ normalized=False,
+ onesided=True,
+ return_complex=True,
+ )
+ spec = torch.sqrt(torch.view_as_real(spec).pow(2).sum(-1) + 1e-9)
+
+ mel_spec = torch.matmul(mel_basis, spec)
+ mel_spec = dynamic_range_compression_torch(mel_spec)
+
+ return mel_spec
+
+
+class Qwen3TTSPreTrainedModel(PreTrainedModel):
+ config_class = Qwen3TTSConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["Qwen3TTSDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+ _supports_static_cache = False
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ # important: this ported version of Qwen2.5OmniThinker isn't meant for training from scratch - only
+ # inference and fine-tuning - so the proper init weights code has been removed
+ std = self.config.initializer_range if hasattr(self.config, "initializer_range") else 0.02
+
+ if isinstance(module, (nn.Linear, nn.Conv1d, nn.Conv3d, nn.ConvTranspose1d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ if module.weight is not None:
+ module.weight.data.fill_(1.0)
+ if module.bias is not None:
+ module.bias.data.zero_()
+
+
+class Qwen3TTSTalkerTextPreTrainedModel(PreTrainedModel):
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = []
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = False
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, Qwen3TTSRMSNorm):
+ module.weight.data.fill_(1.0)
+
+
+class Qwen3TTSTalkerRotaryEmbedding(nn.Module):
+ def __init__(self, config: Qwen3TTSTalkerConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ @torch.no_grad()
+ @dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
+ def forward(self, x, position_ids):
+ # In contrast to other models, Qwen3TTSThinkerText has different position ids for the grids
+ # So we expand the inv_freq to shape (3, ...)
+ inv_freq_expanded = self.inv_freq[None, None, :, None].float().expand(3, position_ids.shape[1], -1, 1)
+ position_ids_expanded = position_ids[:, :, None, :].float() # shape (3, bs, 1, positions)
+
+ device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False): # Force float32
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos() * self.attention_scaling
+ sin = emb.sin() * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+class Qwen3TTSRotaryEmbedding(nn.Module):
+ def __init__(self, config: Qwen3TTSConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ @torch.no_grad()
+ @dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
+ def forward(self, x, position_ids):
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
+ position_ids_expanded = position_ids[:, None, :].float()
+
+ device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False): # Force float32
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos() * self.attention_scaling
+ sin = emb.sin() * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+@use_kernel_forward_from_hub("RMSNorm")
+class Qwen3TTSRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Qwen3TTSRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+def apply_multimodal_rotary_pos_emb(q, k, cos, sin, mrope_section, mrope_interleaved=False, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding with Multimodal Sections to the query and key tensors (https://qwenlm.github.io/blog/qwen2-vl/).
+
+ Explanation:
+ Multimodal 3D rotary position embedding is an extension to 1D rotary position embedding. The input embedding
+ sequence contains vision (images / videos) embedding and text embedding or just contains text embedding. For
+ vision embedding part, we apply rotary position embedding on temporal, height and width dimension separately.
+ Here we split the channel dimension to 3 chunks for the temporal, height and width rotary position embedding.
+ For text embedding part, we just apply 1D rotary position embedding. The three rotary position index (temporal,
+ height and width) of text embedding is always the same, so the text embedding rotary position embedding has no
+ difference with modern LLMs.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ mrope_section(`List(int)`):
+ Multimodal rope section is for channel dimension of temporal, height and width in rope calculation.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ if mrope_interleaved:
+
+ def apply_interleaved_rope(x, modality_num):
+ x_t = x[0].clone()
+ index_ranges = []
+ for i, n in enumerate(mrope_section[1:], 1):
+ beg_idx = i
+ end_idx = n * modality_num
+ index_ranges.append((beg_idx, end_idx))
+ for beg_idx, end_idx in index_ranges:
+ x_t[..., beg_idx:end_idx:modality_num] = x[beg_idx, ..., beg_idx:end_idx:modality_num]
+ return x_t
+
+ dim = cos.shape[-1]
+ modality_num = len(mrope_section)
+ cos = torch.cat([apply_interleaved_rope(cos[..., : dim // 2], modality_num)] * 2, dim=-1).unsqueeze(
+ unsqueeze_dim
+ )
+ sin = torch.cat([apply_interleaved_rope(sin[..., : dim // 2], modality_num)] * 2, dim=-1).unsqueeze(
+ unsqueeze_dim
+ )
+ else:
+ mrope_section = mrope_section * 2
+ cos = torch.cat([m[i % 3] for i, m in enumerate(cos.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
+ unsqueeze_dim
+ )
+ sin = torch.cat([m[i % 3] for i, m in enumerate(sin.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
+ unsqueeze_dim
+ )
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class Qwen3TTSTalkerAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config, layer_idx):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+ self.q_norm = Qwen3TTSRMSNorm(
+ self.head_dim, eps=config.rms_norm_eps
+ ) # unlike olmo, only on the head dim!
+ self.k_norm = Qwen3TTSRMSNorm(
+ self.head_dim, eps=config.rms_norm_eps
+ ) # thus post q_norm does not need reshape
+ self.sliding_window = getattr(config, "sliding_window", None)
+ self.rope_scaling = config.rope_scaling
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_values: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_multimodal_rotary_pos_emb(
+ query_states, key_states, cos, sin, self.rope_scaling["mrope_section"], self.rope_scaling["interleaved"]
+ )
+
+ if past_key_values is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ sliding_window=self.sliding_window, # diff with Llama
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class Qwen3TTSTalkerResizeMLP(nn.Module):
+ def __init__(self, input_size: int, intermediate_size: int, output_size: int, act: str, bias=False):
+ super().__init__()
+ self.linear_fc1 = nn.Linear(input_size, intermediate_size, bias=bias)
+ self.linear_fc2 = nn.Linear(intermediate_size, output_size, bias=bias)
+ self.act_fn = ACT2FN[act]
+
+ def forward(self, hidden_state):
+ return self.linear_fc2(self.act_fn(self.linear_fc1(hidden_state)))
+
+
+@dataclass
+class Qwen3TTSTalkerCodePredictorOutputWithPast(ModelOutput):
+ r"""
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ past_key_values: Optional[list[torch.FloatTensor]] = None
+ hidden_states: Optional[tuple[torch.FloatTensor]] = None
+ attentions: Optional[tuple[torch.FloatTensor]] = None
+ generation_steps: Optional[int] = None
+
+
+class Qwen3TTSTalkerTextMLP(nn.Module):
+ def __init__(self, config, intermediate_size=None):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = intermediate_size if intermediate_size is not None else config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class Qwen3TTSAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: Qwen3TTSConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+ self.q_norm = Qwen3TTSRMSNorm(self.head_dim, eps=config.rms_norm_eps) # unlike olmo, only on the head dim!
+ self.k_norm = Qwen3TTSRMSNorm(
+ self.head_dim, eps=config.rms_norm_eps
+ ) # thus post q_norm does not need reshape
+ self.sliding_window = config.sliding_window if config.layer_types[layer_idx] == "sliding_attention" else None
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_values: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_values is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ sliding_window=self.sliding_window, # diff with Llama
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class Qwen3TTSDecoderLayer(GradientCheckpointingLayer):
+ def __init__(self, config: Qwen3TTSConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = Qwen3TTSAttention(config=config, layer_idx=layer_idx)
+
+ self.mlp = Qwen3TTSTalkerTextMLP(config)
+ self.input_layernorm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.attention_type = config.layer_types[layer_idx]
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+class Qwen3TTSTalkerCodePredictorModel(Qwen3TTSPreTrainedModel):
+ config_class = Qwen3TTSTalkerCodePredictorConfig
+ base_model_prefix = "talker.code_predictor.model"
+
+ def __init__(self, config: Qwen3TTSTalkerCodePredictorConfig, embedding_dim: int):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.layers = nn.ModuleList(
+ [Qwen3TTSDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = Qwen3TTSRotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+ self.has_sliding_layers = "sliding_attention" in self.config.layer_types
+ self.codec_embedding = nn.ModuleList(
+ [nn.Embedding(config.vocab_size, embedding_dim) for _ in range(config.num_code_groups - 1)]
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.codec_embedding
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @can_return_tuple
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ cache_position=None,
+ generation_steps=None,
+ **flash_attn_kwargs,
+ ) -> BaseModelOutputWithPast:
+ if input_ids is not None:
+ raise ValueError("`input_ids` is expected to be `None`")
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ # TODO (joao): remove this exception in v4.56 -- it exists for users that try to pass a legacy cache
+ if not isinstance(past_key_values, (type(None), Cache)):
+ raise ValueError("The `past_key_values` should be either a `Cache` object or `None`.")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ # It may already have been prepared by e.g. `generate`
+ if not isinstance(causal_mask_mapping := attention_mask, dict):
+ # Prepare mask arguments
+ mask_kwargs = {
+ "config": self.config,
+ "input_embeds": inputs_embeds,
+ "attention_mask": attention_mask,
+ "cache_position": cache_position,
+ "past_key_values": past_key_values,
+ }
+ # Create the masks
+ causal_mask_mapping = {
+ "full_attention": create_causal_mask(**mask_kwargs),
+ }
+ # The sliding window alternating layers are not always activated depending on the config
+ if self.has_sliding_layers:
+ causal_mask_mapping["sliding_attention"] = create_sliding_window_causal_mask(**mask_kwargs)
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask_mapping[decoder_layer.attention_type],
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **flash_attn_kwargs,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class Qwen3TTSTalkerCodePredictorModelForConditionalGeneration(Qwen3TTSPreTrainedModel, GenerationMixin):
+ _tied_weights_keys = ["lm_head.weight"]
+ _tp_plan = {"lm_head": "colwise_rep"}
+ _pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
+ config_class = Qwen3TTSTalkerCodePredictorConfig
+ base_model_prefix = "talker.code_predictor"
+
+ def __init__(self, config: Qwen3TTSTalkerCodePredictorConfig, talker_config: Qwen3TTSTalkerConfig):
+ super().__init__(config)
+ self.model = Qwen3TTSTalkerCodePredictorModel(config, talker_config.hidden_size)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.ModuleList(
+ [nn.Linear(config.hidden_size, config.vocab_size, bias=False) for _ in range(config.num_code_groups - 1)]
+ )
+
+ if config.hidden_size != talker_config.hidden_size:
+ self.small_to_mtp_projection = torch.nn.Linear(talker_config.hidden_size, config.hidden_size, bias=True)
+ else:
+ self.small_to_mtp_projection = torch.nn.Identity()
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ def forward_finetune(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ cache_position=None,
+ generation_steps=None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ inputs_embeds = self.small_to_mtp_projection(inputs_embeds)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs: BaseModelOutputWithPast = self.model(
+ input_ids=None,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+ hidden_states = outputs.last_hidden_state
+
+ logits = []
+ for i in range(1, self.config.num_code_groups):
+ logits.append(self.lm_head[i-1](hidden_states[:, i]))
+ logits = torch.stack(logits, dim=1)
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)
+
+ return Qwen3TTSTalkerCodePredictorOutputWithPast(
+ loss=loss,
+ logits=logits
+ )
+
+ @can_return_tuple
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ cache_position=None,
+ generation_steps=None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ # Prefill stage
+ if inputs_embeds is not None and inputs_embeds.shape[1] > 1:
+ generation_steps = inputs_embeds.shape[1] - 2 # hidden & layer 0
+ # Generation stage
+ else:
+ inputs_embeds = self.model.get_input_embeddings()[generation_steps - 1](input_ids)
+ inputs_embeds = self.small_to_mtp_projection(inputs_embeds)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs: BaseModelOutputWithPast = self.model(
+ input_ids=None,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+ hidden_states = outputs.last_hidden_state
+ logits = self.lm_head[generation_steps](hidden_states)
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)
+
+ return Qwen3TTSTalkerCodePredictorOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ generation_steps=generation_steps + 1,
+ )
+
+ def _update_model_kwargs_for_generation(self, outputs, model_kwargs, is_encoder_decoder=False, num_new_tokens=1):
+ model_kwargs = super()._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder, num_new_tokens
+ )
+ model_kwargs["generation_steps"] = outputs.generation_steps
+ return model_kwargs
+
+
+@dataclass
+class Qwen3TTSTalkerOutputWithPast(ModelOutput):
+ r"""
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[list[torch.FloatTensor]] = None
+ hidden_states: Optional[tuple[torch.FloatTensor]] = None
+ attentions: Optional[tuple[torch.FloatTensor]] = None
+ past_hidden: Optional[torch.FloatTensor] = None
+ generation_step: Optional[int] = None
+ trailing_text_hidden: Optional[torch.FloatTensor] = None
+ tts_pad_embed: Optional[torch.FloatTensor] = None
+
+
+class Qwen3TTSTalkerDecoderLayer(GradientCheckpointingLayer):
+ def __init__(self, config, layer_idx):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = Qwen3TTSTalkerAttention(config, layer_idx)
+
+ self.mlp = Qwen3TTSTalkerTextMLP(config, intermediate_size=config.intermediate_size)
+
+ self.input_layernorm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ position_embeddings (`tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
+ Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
+ with `head_dim` being the embedding dimension of each attention head.
+ kwargs (`dict`, *optional*):
+ Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
+ into the model
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+
+ hidden_states = self.mlp(hidden_states)
+
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+class Qwen3TTSTalkerModel(Qwen3TTSTalkerTextPreTrainedModel):
+ config_class = Qwen3TTSTalkerConfig
+ base_model_prefix = "talker.model"
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.layers = nn.ModuleList(
+ [Qwen3TTSTalkerDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = Qwen3TTSRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = Qwen3TTSTalkerRotaryEmbedding(config)
+ self.gradient_checkpointing = False
+ self.codec_embedding = nn.Embedding(config.vocab_size, config.hidden_size)
+ self.text_embedding = nn.Embedding(config.text_vocab_size, config.text_hidden_size)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.codec_embedding
+
+ def get_text_embeddings(self):
+ return self.text_embedding
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @can_return_tuple
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **flash_attn_kwargs: Unpack[FlashAttentionKwargs],
+ ) -> BaseModelOutputWithPast:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ # the hard coded `3` is for temporal, height and width.
+ if position_ids is None:
+ position_ids = cache_position.view(1, 1, -1).expand(3, inputs_embeds.shape[0], -1)
+ elif position_ids.ndim == 2:
+ position_ids = position_ids[None, ...].expand(3, position_ids.shape[0], -1)
+
+ if position_ids.ndim == 3 and position_ids.shape[0] == 4:
+ text_position_ids = position_ids[0]
+ position_ids = position_ids[1:]
+ else:
+ text_position_ids = position_ids[0]
+
+ mask_function = create_causal_mask if self.config.sliding_window is None else create_sliding_window_causal_mask
+ causal_mask = mask_function(
+ config=self.config,
+ input_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ past_key_values=past_key_values,
+ position_ids=text_position_ids,
+ )
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=text_position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **flash_attn_kwargs,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class Qwen3TTSTalkerForConditionalGeneration(Qwen3TTSTalkerTextPreTrainedModel, GenerationMixin):
+ _tied_weights_keys = ["lm_head.weight"]
+ _tp_plan = {"lm_head": "colwise_rep"}
+ _pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
+ config_class = Qwen3TTSTalkerConfig
+ base_model_prefix = "talker"
+
+ def __init__(self, config: Qwen3TTSTalkerConfig):
+ super().__init__(config)
+ self.model = Qwen3TTSTalkerModel(config)
+ self.vocab_size = config.vocab_size
+ self.text_projection = Qwen3TTSTalkerResizeMLP(
+ config.text_hidden_size, config.text_hidden_size, config.hidden_size, config.hidden_act, bias=True
+ )
+
+ self.codec_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+ self.code_predictor = Qwen3TTSTalkerCodePredictorModelForConditionalGeneration(
+ config=config.code_predictor_config,
+ talker_config=config
+ )
+ self.rope_deltas = None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # TODO: hack, modular cannot inherit multiple classes
+
+ def get_input_embeddings(self):
+ return self.model.get_input_embeddings()
+
+ def get_text_embeddings(self):
+ return self.model.get_text_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ def forward_sub_talker_finetune(self, codec_ids, talker_hidden_states):
+ assert len(codec_ids.shape) == 2
+ assert len(talker_hidden_states.shape) == 2
+ assert codec_ids.shape[0] == talker_hidden_states.shape[0]
+ assert talker_hidden_states.shape[1] == self.config.hidden_size
+ assert codec_ids.shape[1] == self.config.num_code_groups
+
+ sub_talker_inputs_embeds = [talker_hidden_states.unsqueeze(1)]
+
+ for i in range(self.config.num_code_groups - 1):
+ if i == 0:
+ sub_talker_inputs_embeds.append(self.get_input_embeddings()(codec_ids[:, :1]))
+ else:
+ sub_talker_inputs_embeds.append(self.code_predictor.get_input_embeddings()[i-1](codec_ids[:, i:i+1]))
+ sub_talker_inputs_embeds = torch.cat(sub_talker_inputs_embeds, dim=1)
+
+ sub_talker_outputs = self.code_predictor.forward_finetune(inputs_embeds=sub_talker_inputs_embeds,
+ labels=codec_ids[:, 1:])
+
+ sub_talker_logits = sub_talker_outputs.logits
+ sub_talker_loss = sub_talker_outputs.loss
+ return sub_talker_logits, sub_talker_loss
+
+ @can_return_tuple
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ labels=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ cache_position=None,
+ past_hidden=None,
+ trailing_text_hidden=None,
+ tts_pad_embed=None,
+ generation_step=None,
+ subtalker_dosample=None,
+ subtalker_top_p=None,
+ subtalker_top_k=None,
+ subtalker_temperature=None,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ ```"""
+ # Prefill
+ if inputs_embeds is not None and inputs_embeds.shape[1] > 1:
+ generation_step = -1
+ codec_ids = None
+ # Generate
+ else:
+ last_id_hidden = self.get_input_embeddings()(input_ids)
+ predictor_result = self.code_predictor.generate(
+ inputs_embeds=torch.cat((past_hidden, last_id_hidden), dim=1),
+ max_new_tokens=self.config.num_code_groups - 1,
+ do_sample=subtalker_dosample,
+ top_p=subtalker_top_p,
+ top_k=subtalker_top_k,
+ temperature=subtalker_temperature,
+ output_hidden_states=True,
+ return_dict_in_generate=True,
+ )
+ codec_ids = torch.cat((input_ids, predictor_result.sequences), dim=-1)
+ codec_hiddens = torch.cat(
+ [last_id_hidden]
+ + [self.code_predictor.get_input_embeddings()[i](predictor_result.sequences[..., i:i+1]) for i in range(self.config.num_code_groups - 1)],
+ dim=1,
+ )
+ inputs_embeds = codec_hiddens.sum(1, keepdim=True)
+
+ if generation_step < trailing_text_hidden.shape[1]:
+ inputs_embeds = inputs_embeds + trailing_text_hidden[:, generation_step].unsqueeze(1)
+ else:
+ inputs_embeds = inputs_embeds + tts_pad_embed
+ if attention_mask is not None:
+ if (
+ cache_position is None
+ or (cache_position is not None and cache_position[0] == 0)
+ or self.rope_deltas is None
+ ):
+ delta0 = (1 - attention_mask).sum(dim=-1).unsqueeze(1)
+ position_ids, rope_deltas = self.get_rope_index(
+ attention_mask,
+ )
+ rope_deltas = rope_deltas - delta0
+ self.rope_deltas = rope_deltas
+ else:
+ batch_size, seq_length = input_ids.shape
+ delta = cache_position[0] + self.rope_deltas if cache_position is not None else 0
+ position_ids = torch.arange(seq_length, device=input_ids.device)
+ position_ids = position_ids.view(1, -1).expand(batch_size, -1)
+ position_ids = position_ids.add(delta)
+ position_ids = position_ids.unsqueeze(0).expand(3, -1, -1)
+
+ outputs: BaseModelOutputWithPast = self.model(
+ input_ids=None,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+ hidden_states = outputs.last_hidden_state
+ logits = self.codec_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)
+
+
+ return Qwen3TTSTalkerOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=(outputs.hidden_states, codec_ids),
+ attentions=outputs.attentions,
+ past_hidden=hidden_states[:, -1:, :],
+ generation_step=generation_step + 1,
+ trailing_text_hidden=trailing_text_hidden,
+ tts_pad_embed=tts_pad_embed,
+ )
+
+ def get_rope_index(
+ self,
+ attention_mask: Optional[torch.Tensor] = None,
+ ) -> tuple[torch.Tensor, torch.Tensor]:
+ """
+ Calculate the 3D rope index based on image and video's temporal, height and width in LLM.
+
+ Explanation:
+ Each embedding sequence contains vision embedding and text embedding or just contains text embedding.
+
+ For pure text embedding sequence, the rotary position embedding has no difference with modern LLMs.
+ Examples:
+ input_ids: [T T T T T], here T is for text.
+ temporal position_ids: [0, 1, 2, 3, 4]
+ height position_ids: [0, 1, 2, 3, 4]
+ width position_ids: [0, 1, 2, 3, 4]
+
+ For vision and text embedding sequence, we calculate 3D rotary position embedding for vision part
+ and 1D rotary position embedding for text part.
+ Examples:
+ Temporal (Time): 3 patches, representing different segments of the video in time.
+ Height: 2 patches, dividing each frame vertically.
+ Width: 2 patches, dividing each frame horizontally.
+ We also have some important parameters:
+ fps (Frames Per Second): The video's frame rate, set to 1. This means one frame is processed each second.
+ interval: The step size for the temporal position IDs, calculated as tokens_per_second * temporal_patch_size / fps. In this case, 25 * 2 / 1 = 50. This means that each temporal patch will be have a difference of 50 in the temporal position IDs.
+ input_ids: [V V V V V V V V V V V V T T T T T], here V is for vision.
+ text temporal position_ids: [101, 102, 103, 104, 105]
+ text height position_ids: [101, 102, 103, 104, 105]
+ text width position_ids: [101, 102, 103, 104, 105]
+ Here we calculate the text start position_ids as the max vision position_ids plus 1.
+
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ Returns:
+ position_ids (`torch.LongTensor` of shape `(3, batch_size, sequence_length)`)
+ mrope_position_deltas (`torch.Tensor` of shape `(batch_size)`)
+ """
+ mrope_position_deltas = []
+
+ position_ids = attention_mask.float().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ position_ids = position_ids.unsqueeze(0).expand(3, -1, -1).to(attention_mask.device)
+ max_position_ids = position_ids.max(0, keepdim=False)[0].max(-1, keepdim=True)[0]
+ mrope_position_deltas = max_position_ids + 1 - torch.sum(attention_mask, dim=-1, keepdim=True)
+
+ return position_ids, mrope_position_deltas
+
+ def _update_model_kwargs_for_generation(self, outputs, model_kwargs, is_encoder_decoder=False, num_new_tokens=1):
+ model_kwargs = super()._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder, num_new_tokens
+ )
+ model_kwargs["past_hidden"] = outputs.past_hidden
+ model_kwargs["generation_step"] = outputs.generation_step
+ model_kwargs["trailing_text_hidden"] = outputs.trailing_text_hidden
+ model_kwargs["tts_pad_embed"] = outputs.tts_pad_embed
+ return model_kwargs
+
+
+class Qwen3TTSForConditionalGeneration(Qwen3TTSPreTrainedModel, GenerationMixin):
+ config_class = Qwen3TTSConfig
+
+ def __init__(self, config: Qwen3TTSConfig):
+ super().__init__(config)
+ self.config = config
+
+ self.talker = Qwen3TTSTalkerForConditionalGeneration(self.config.talker_config)
+
+ if config.tts_model_type == "base":
+ self.speaker_encoder = Qwen3TTSSpeakerEncoder(self.config.speaker_encoder_config)
+ else:
+ self.speaker_encoder = None
+
+ self.speech_tokenizer = None
+ self.generate_config = None
+
+ self.supported_speakers = self.config.talker_config.spk_id.keys()
+ self.supported_languages = ["auto"]
+ for language_id in self.config.talker_config.codec_language_id.keys():
+ if "dialect" not in language_id:
+ self.supported_languages.append(language_id)
+
+ self.speaker_encoder_sample_rate = self.config.speaker_encoder_config.sample_rate
+ self.tokenizer_type = self.config.tokenizer_type
+ self.tts_model_size = self.config.tts_model_size
+ self.tts_model_type = self.config.tts_model_type
+
+ self.post_init()
+
+ def load_speech_tokenizer(self, speech_tokenizer):
+ self.speech_tokenizer = speech_tokenizer
+
+ def load_generate_config(self, generate_config):
+ self.generate_config = generate_config
+
+ def get_supported_speakers(self):
+ return self.supported_speakers
+
+ def get_supported_languages(self):
+ return self.supported_languages
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *model_args,
+ config=None,
+ cache_dir=None,
+ ignore_mismatched_sizes=False,
+ force_download=False,
+ local_files_only=False,
+ token=None,
+ revision="main",
+ use_safetensors=None,
+ weights_only=True,
+ **kwargs,
+ ):
+ # Hotfix to enable passing the correct attn implementation which is stored in the config but not in kwargs
+ requested_attn_implementation = kwargs.pop("attn_implementation", None)
+ if requested_attn_implementation is None and config and config._attn_implementation:
+ requested_attn_implementation = config._attn_implementation
+
+ model = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *model_args,
+ config=config,
+ cache_dir=cache_dir,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ force_download=force_download,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ use_safetensors=use_safetensors,
+ weights_only=weights_only,
+ attn_implementation=requested_attn_implementation,
+ **kwargs,
+ )
+ if not local_files_only and not os.path.isdir(pretrained_model_name_or_path):
+ download_cache_dir = kwargs.get("cache_dir", cache_dir)
+ download_revision = kwargs.get("revision", revision)
+ download_weights_from_hf_specific(
+ pretrained_model_name_or_path,
+ cache_dir=download_cache_dir,
+ allow_patterns=["speech_tokenizer/*"],
+ revision=download_revision,
+ )
+ speech_tokenizer_path = cached_file(
+ pretrained_model_name_or_path,
+ "speech_tokenizer/config.json",
+ subfolder=kwargs.pop("subfolder", None),
+ cache_dir=kwargs.pop("cache_dir", None),
+ force_download=kwargs.pop("force_download", False),
+ proxies=kwargs.pop("proxies", None),
+ resume_download=kwargs.pop("resume_download", None),
+ local_files_only=kwargs.pop("local_files_only", False),
+ token=kwargs.pop("use_auth_token", None),
+ revision=kwargs.pop("revision", None),
+ )
+ if speech_tokenizer_path is None:
+ raise ValueError(f"""{pretrained_model_name_or_path}/{speech_tokenizer_path} not exists""")
+ speech_tokenizer_dir = os.path.dirname(speech_tokenizer_path)
+ speech_tokenizer = Qwen3TTSTokenizer.from_pretrained(
+ speech_tokenizer_dir,
+ *model_args,
+ **kwargs,
+ )
+ model.load_speech_tokenizer(speech_tokenizer)
+
+ generate_config_path = cached_file(
+ pretrained_model_name_or_path,
+ "generation_config.json",
+ subfolder=kwargs.pop("subfolder", None),
+ cache_dir=kwargs.pop("cache_dir", None),
+ force_download=kwargs.pop("force_download", False),
+ proxies=kwargs.pop("proxies", None),
+ resume_download=kwargs.pop("resume_download", None),
+ local_files_only=kwargs.pop("local_files_only", False),
+ token=kwargs.pop("use_auth_token", None),
+ revision=kwargs.pop("revision", None),
+ )
+ with open(generate_config_path, "r", encoding="utf-8") as f:
+ generate_config = json.load(f)
+ model.load_generate_config(generate_config)
+
+ return model
+
+ @torch.inference_mode()
+ def extract_speaker_embedding(self, audio, sr):
+ assert sr == 24000, "Only support 24kHz audio"
+ mels = mel_spectrogram(
+ torch.from_numpy(audio).unsqueeze(0),
+ n_fft=1024,
+ num_mels=128,
+ sampling_rate=24000,
+ hop_size=256,
+ win_size=1024,
+ fmin=0,
+ fmax=12000
+ ).transpose(1, 2)
+ speaker_embedding = self.speaker_encoder(mels.to(self.device).to(self.dtype))[0]
+ return speaker_embedding
+
+ @torch.inference_mode()
+ def generate_speaker_prompt(
+ self,
+ voice_clone_prompt: list[dict]
+ ):
+ voice_clone_spk_embeds = []
+ for index in range(len(voice_clone_prompt['ref_spk_embedding'])):
+ ref_spk_embedding = voice_clone_prompt["ref_spk_embedding"][index].to(self.talker.device).to(self.talker.dtype)
+ voice_clone_spk_embeds.append(ref_spk_embedding)
+
+ return voice_clone_spk_embeds
+
+ def generate_icl_prompt(
+ self,
+ text_id: torch.Tensor,
+ ref_id: torch.Tensor,
+ ref_code: torch.Tensor,
+ tts_pad_embed: torch.Tensor,
+ tts_eos_embed: torch.Tensor,
+ non_streaming_mode: bool,
+ ):
+ # text embed (ref id + text id + eos) 1 T1 D
+ text_embed = self.talker.text_projection(
+ self.talker.get_text_embeddings()(torch.cat([ref_id, text_id],
+ dim=-1)))
+ text_embed = torch.cat([text_embed, tts_eos_embed], dim=1)
+ # codec embed (codec bos + codec) 1 T2 D
+ codec_embed = []
+ for i in range(self.talker.config.num_code_groups):
+ if i == 0:
+ codec_embed.append(self.talker.get_input_embeddings()(ref_code[:, :1]))
+ else:
+ codec_embed.append(self.talker.code_predictor.get_input_embeddings()[i-1](ref_code[:, i:i+1]))
+ codec_embed = torch.cat(codec_embed, dim=1).sum(1).unsqueeze(0)
+ codec_embed = torch.cat([self.talker.get_input_embeddings()(
+ torch.tensor(
+ [[
+ self.config.talker_config.codec_bos_id,
+ ]],
+ device=self.talker.device,
+ dtype=text_id.dtype,
+ )
+ ), codec_embed], dim=1)
+ # compute lens
+ text_lens = text_embed.shape[1]
+ codec_lens = codec_embed.shape[1]
+ if non_streaming_mode:
+ icl_input_embed = text_embed + self.talker.get_input_embeddings()(
+ torch.tensor(
+ [[
+ self.config.talker_config.codec_pad_id,
+ ] * text_lens],
+ device=self.talker.device,
+ dtype=text_id.dtype,
+ )
+ )
+ icl_input_embed = torch.cat([icl_input_embed, codec_embed + tts_pad_embed], dim=1)
+ return icl_input_embed, tts_pad_embed
+ else:
+ if text_lens > codec_lens:
+ return text_embed[:, :codec_lens] + codec_embed, text_embed[:, codec_lens:]
+ else:
+ text_embed = torch.cat([text_embed] + [tts_pad_embed] * (codec_lens - text_lens), dim=1)
+ return text_embed + codec_embed, tts_pad_embed
+
+ @torch.no_grad()
+ def generate(
+ self,
+ input_ids: Optional[list[torch.Tensor]] = None,
+ instruct_ids: Optional[list[torch.Tensor]] = None,
+ ref_ids: Optional[list[torch.Tensor]] = None,
+ voice_clone_prompt: list[dict] = None,
+ languages: list[str] = None,
+ speakers: list[str] = None,
+ non_streaming_mode = False,
+ max_new_tokens: int = 4096,
+ do_sample: bool = True,
+ top_k: int = 50,
+ top_p: float = 1.0,
+ temperature: float = 0.9,
+ subtalker_dosample: bool = True,
+ subtalker_top_k: int = 50,
+ subtalker_top_p: float = 1.0,
+ subtalker_temperature: float = 0.9,
+ eos_token_id: Optional[int] = None,
+ repetition_penalty: float = 1.05,
+ **kwargs,
+ ):
+ talker_kwargs = {
+ "max_new_tokens": max_new_tokens,
+ "min_new_tokens": 2,
+ "do_sample": do_sample,
+ "top_k": top_k,
+ "top_p": top_p,
+ "temperature": temperature,
+ "subtalker_dosample": subtalker_dosample,
+ "subtalker_top_k": subtalker_top_k,
+ "subtalker_top_p": subtalker_top_p,
+ "subtalker_temperature": subtalker_temperature,
+ "eos_token_id": eos_token_id
+ if eos_token_id is not None
+ else self.config.talker_config.codec_eos_token_id,
+ "repetition_penalty": repetition_penalty,
+ "suppress_tokens": [
+ i
+ for i in range(self.config.talker_config.vocab_size - 1024, self.config.talker_config.vocab_size)
+ if i not in (self.config.talker_config.codec_eos_token_id,)
+ ],
+ "output_hidden_states": getattr(kwargs, "output_hidden_states", True),
+ "return_dict_in_generate": getattr(kwargs, "return_dict_in_generate", True)
+ }
+
+ talker_input_embeds = [[] for _ in range(len(input_ids))]
+
+ voice_clone_spk_embeds = None
+ # voice clone speaker prompt generate
+ if voice_clone_prompt is not None:
+ voice_clone_spk_embeds = self.generate_speaker_prompt(voice_clone_prompt)
+
+ # instruct text prompt generate
+ if instruct_ids is not None:
+ for index, instruct_id in enumerate(instruct_ids):
+ if instruct_id is not None:
+ talker_input_embeds[index].append(self.talker.text_projection(
+ self.talker.get_text_embeddings()(instruct_id)))
+
+ # tts text prompt generate
+ trailing_text_hiddens = []
+ if speakers is None:
+ speakers = [None] * len(input_ids)
+ for index, (input_id, language, speaker) in enumerate(zip(input_ids, languages, speakers)):
+ if voice_clone_spk_embeds is None:
+ if speaker == "" or speaker == None: # Instruct create speaker
+ speaker_embed = None
+ else:
+ if speaker.lower() not in self.config.talker_config.spk_id:
+ raise NotImplementedError(f"Speaker {speaker} not implemented")
+ else:
+ spk_id = self.config.talker_config.spk_id[speaker.lower()]
+ speaker_embed = self.talker.get_input_embeddings()(
+ torch.tensor(
+ spk_id,
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ )
+ else:
+ if voice_clone_prompt["x_vector_only_mode"][index] or voice_clone_prompt["icl_mode"][index]:
+ speaker_embed = voice_clone_spk_embeds[index]
+ else:
+ speaker_embed = None
+
+ assert language is not None
+
+ if language.lower() == "auto":
+ language_id = None
+ else:
+ if language.lower() not in self.config.talker_config.codec_language_id:
+ raise NotImplementedError(f"Language {language} not implemented")
+ else:
+ language_id = self.config.talker_config.codec_language_id[language.lower()]
+
+ if (language.lower() in ["chinese", "auto"] and \
+ speaker != "" and speaker is not None and \
+ self.config.talker_config.spk_is_dialect[speaker.lower()] != False):
+ dialect = self.config.talker_config.spk_is_dialect[speaker.lower()]
+ language_id = self.config.talker_config.codec_language_id[dialect]
+
+ tts_bos_embed, tts_eos_embed, tts_pad_embed = self.talker.text_projection(
+ self.talker.get_text_embeddings()(
+ torch.tensor(
+ [[self.config.tts_bos_token_id, self.config.tts_eos_token_id, self.config.tts_pad_token_id]],
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ )
+ ).chunk(3, dim=1) # 3 * [1 1 d]
+
+ # codec: tag and speaker
+ if language_id is None:
+ codec_prefill_list = [[
+ self.config.talker_config.codec_nothink_id,
+ self.config.talker_config.codec_think_bos_id,
+ self.config.talker_config.codec_think_eos_id,
+ ]]
+ else:
+ codec_prefill_list = [[
+ self.config.talker_config.codec_think_id,
+ self.config.talker_config.codec_think_bos_id,
+ language_id,
+ self.config.talker_config.codec_think_eos_id,
+ ]]
+
+ codec_input_emebdding_0 = self.talker.get_input_embeddings()(
+ torch.tensor(
+ codec_prefill_list,
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ )
+ codec_input_emebdding_1 = self.talker.get_input_embeddings()(
+ torch.tensor(
+ [[
+ self.config.talker_config.codec_pad_id,
+ self.config.talker_config.codec_bos_id,
+ ]],
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ )
+ if speaker_embed is None:
+ codec_input_emebdding = torch.cat([codec_input_emebdding_0,
+ codec_input_emebdding_1], dim=1)
+ else:
+ codec_input_emebdding = torch.cat([codec_input_emebdding_0,
+ speaker_embed.view(1, 1, -1),
+ codec_input_emebdding_1], dim=1)
+
+ # '<|im_start|>assistant\n我叫通义千问,是阿里云的开源大模型。<|im_end|>\n<|im_start|>assistant\n'
+
+ # <|im_start|>assistant\n
+ _talker_input_embed_role = self.talker.text_projection(
+ self.talker.get_text_embeddings()(input_id[:, :3])
+ )
+
+ # tts_pad * 4 + tts_bos
+ _talker_input_embed = torch.cat((tts_pad_embed.expand(-1, codec_input_emebdding.shape[1] - 2, -1),
+ tts_bos_embed,
+ ), dim=1) + codec_input_emebdding[:, :-1]
+
+ talker_input_embed = torch.cat((_talker_input_embed_role, _talker_input_embed), dim=1)
+
+ if voice_clone_prompt is not None and voice_clone_prompt["ref_code"] is not None and voice_clone_prompt["icl_mode"][index]:
+ icl_input_embed, trailing_text_hidden = self.generate_icl_prompt(
+ text_id=input_id[:, 3:-5],
+ ref_id=ref_ids[index][:, 3:-2],
+ ref_code=voice_clone_prompt["ref_code"][index].to(self.talker.device),
+ tts_pad_embed=tts_pad_embed,
+ tts_eos_embed=tts_eos_embed,
+ non_streaming_mode=non_streaming_mode,
+ )
+ talker_input_embed = torch.cat([talker_input_embed, icl_input_embed], dim=1)
+ else:
+ # tts_text_first_token
+ talker_input_embed = torch.cat([talker_input_embed,
+ self.talker.text_projection(self.talker.get_text_embeddings()(input_id[:, 3:4])) + codec_input_emebdding[:, -1:]],
+ dim=1)
+ if non_streaming_mode:
+ talker_input_embed = talker_input_embed[:, :-1] # 去掉原本放进去的text
+ talker_input_embed = torch.cat([talker_input_embed,
+ torch.cat((self.talker.text_projection(
+ self.talker.get_text_embeddings()(input_id[:, 3:-5])
+ ), tts_eos_embed), dim=1) + self.talker.get_input_embeddings()(
+ torch.tensor(
+ [[
+ self.config.talker_config.codec_pad_id,
+ ] * (input_id[:, 3:-5].shape[1] + 1)],
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ ),
+ tts_pad_embed + self.talker.get_input_embeddings()(
+ torch.tensor(
+ [[
+ self.config.talker_config.codec_bos_id,
+ ]],
+ device=self.talker.device,
+ dtype=input_id.dtype,
+ )
+ )
+ ], dim=1)
+ trailing_text_hidden = tts_pad_embed
+ else:
+ # 叫通义千问,是阿里云的开源大模型。
+ trailing_text_hidden = torch.cat((self.talker.text_projection(
+ self.talker.get_text_embeddings()(input_id[:, 4:-5])
+ ), tts_eos_embed), dim=1)
+ talker_input_embeds[index].append(talker_input_embed)
+ trailing_text_hiddens.append(trailing_text_hidden)
+
+ for index, talker_input_embed in enumerate(talker_input_embeds):
+ talker_input_embeds[index] = torch.cat([item for item in talker_input_embed if item is not None], dim=1)
+
+ # for batch inferquence
+ original_lengths = torch.tensor([t.shape[1] for t in talker_input_embeds])
+ # left padding for talker input embeds
+ sequences = [t.squeeze(0) for t in talker_input_embeds]
+ sequences_reversed = [t.flip(dims=[0]) for t in sequences]
+ padded_reversed = torch.nn.utils.rnn.pad_sequence(
+ sequences_reversed,
+ batch_first=True,
+ padding_value=0.0
+ )
+ talker_input_embeds = padded_reversed.flip(dims=[1])
+ # generate mask
+ batch_size, max_len = talker_input_embeds.shape[0], talker_input_embeds.shape[1]
+ indices = torch.arange(max_len).expand(batch_size, -1)
+ num_pads = max_len - original_lengths
+ talker_attention_mask = (indices >= num_pads.unsqueeze(1)).long().to(talker_input_embeds.device)
+ # padding trailing text hiddens
+ pad_embedding_vector = tts_pad_embed.squeeze()
+ sequences_to_pad = [t.squeeze(0) for t in trailing_text_hiddens]
+ trailing_text_original_lengths = [s.shape[0] for s in sequences_to_pad]
+ padded_hiddens = torch.nn.utils.rnn.pad_sequence(
+ sequences_to_pad,
+ batch_first=True,
+ padding_value=0.0
+ )
+ arange_tensor = torch.arange(max(trailing_text_original_lengths),
+ device=padded_hiddens.device).expand(len(trailing_text_original_lengths), -1)
+ lengths_tensor = torch.tensor(trailing_text_original_lengths, device=padded_hiddens.device).unsqueeze(1)
+ padding_mask = arange_tensor >= lengths_tensor
+ padded_hiddens[padding_mask] = pad_embedding_vector
+ trailing_text_hiddens = padded_hiddens
+
+ # forward
+ talker_result = self.talker.generate(
+ inputs_embeds=talker_input_embeds,
+ attention_mask=talker_attention_mask,
+ trailing_text_hidden=trailing_text_hiddens,
+ tts_pad_embed=tts_pad_embed,
+ **talker_kwargs,
+ )
+
+ talker_codes = torch.stack([hid[-1] for hid in talker_result.hidden_states if hid[-1] is not None], dim=1)
+ talker_hidden_states = torch.cat([hid[0][-1][:, -1:] for hid in talker_result.hidden_states], dim=1)[:, :-1]
+
+ first_codebook = talker_codes[:, :, 0]
+ is_stop_token = (first_codebook == self.config.talker_config.codec_eos_token_id)
+ stop_indices = torch.argmax(is_stop_token.int(), dim=1)
+ has_stop_token = is_stop_token.any(dim=1)
+ effective_lengths = torch.where(has_stop_token, stop_indices, talker_codes.shape[1])
+
+ talker_codes_list = [talker_codes[i, :length, ] for i, length in enumerate(effective_lengths)]
+ talker_hidden_states_list = [talker_hidden_states[i, :length, :] for i, length in enumerate(effective_lengths)]
+
+ return talker_codes_list, talker_hidden_states_list
+
+__all__ = [
+ "Qwen3TTSForConditionalGeneration",
+ "Qwen3TTSTalkerForConditionalGeneration",
+ "Qwen3TTSPreTrainedModel",
+ "Qwen3TTSTalkerModel",
+]
diff --git a/models/Qwen3-TTS/qwen_tts/core/models/processing_qwen3_tts.py b/models/Qwen3-TTS/qwen_tts/core/models/processing_qwen3_tts.py
new file mode 100644
index 0000000..bed9bff
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/models/processing_qwen3_tts.py
@@ -0,0 +1,106 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.processing_utils import ProcessingKwargs, ProcessorMixin
+
+
+class Qwen3TTSProcessorKwargs(ProcessingKwargs, total=False):
+ _defaults = {
+ "text_kwargs": {
+ "padding": False,
+ "padding_side": "left",
+ }
+ }
+
+class Qwen3TTSProcessor(ProcessorMixin):
+ r"""
+ Constructs a Qwen3TTS processor.
+
+ Args:
+ tokenizer ([`Qwen2TokenizerFast`], *optional*):
+ The text tokenizer.
+ chat_template (`Optional[str]`, *optional*):
+ The Jinja template to use for formatting the conversation. If not provided, the default chat template is used.
+ """
+
+ attributes = ["tokenizer"]
+ tokenizer_class = ("Qwen2Tokenizer", "Qwen2TokenizerFast")
+
+ def __init__(
+ self, tokenizer=None, chat_template=None
+ ):
+ super().__init__(tokenizer, chat_template=chat_template)
+
+ def __call__(self, text=None, **kwargs) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and audio(s). This method forwards the `text`
+ and `kwargs` arguments to Qwen2TokenizerFast's [`~Qwen2TokenizerFast.__call__`] if `text` is not `None` to encode
+ the text.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ """
+
+ if text is None:
+ raise ValueError("You need to specify either a `text` input to process.")
+
+ output_kwargs = self._merge_kwargs(
+ Qwen3TTSProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+ if not isinstance(text, list):
+ text = [text]
+
+ texts_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
+
+ return BatchFeature(
+ data={**texts_inputs},
+ tensor_type=kwargs.get("return_tensors"),
+ )
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to Qwen2TokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to Qwen2TokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ def apply_chat_template(self, conversations, chat_template=None, **kwargs):
+ if isinstance(conversations[0], dict):
+ conversations = [conversations]
+ return super().apply_chat_template(conversations, chat_template, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ return list(
+ dict.fromkeys(
+ tokenizer_input_names
+ )
+ )
+
+
+__all__ = ["Qwen3TTSProcessor"]
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/configuration_qwen3_tts_tokenizer_v2.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/configuration_qwen3_tts_tokenizer_v2.py
new file mode 100644
index 0000000..82658a5
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/configuration_qwen3_tts_tokenizer_v2.py
@@ -0,0 +1,172 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Qwen3TTSTokenizerV2 model configuration"""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+from transformers import MimiConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class Qwen3TTSTokenizerV2DecoderConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen3TTSTokenizerV2DecoderConfig`].
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ codebook_size (`int`, *optional*, defaults to 2048):
+ Number of entries in each residual codebook used for acoustic token quantization.
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the hidden states and embeddings in the autoregressive transformer decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 8000):
+ Maximum sequence length that the autoregressive decoder can handle. Determines positional embedding size.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period for rotary position embeddings (RoPE) applied to attention layers.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the decoder.
+ num_key_value_heads (`int`, *optional*, defaults to 16):
+ Number of key and value attention heads used in grouped-query attention (if applicable).
+ attention_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use bias in the attention projection layers.
+ sliding_window (`int`, *optional*, defaults to 72):
+ Window size for local attention mechanism, limiting attention context to improve efficiency.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the feed-forward (intermediate) layer in each transformer block.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function used in the feed-forward layers. Supports `"silu"`, `"relu"`, `"gelu"`, etc.
+ layer_scale_initial_scale (`float`, *optional*, defaults to 0.01):
+ Initial value for LayerScale applied in transformer blocks, helping stabilize training.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-5):
+ Epsilon value for RMS normalization layers to prevent division by zero.
+ num_hidden_layers (`int`, *optional*, defaults to 8):
+ Number of transformer blocks in the autoregressive decoder.
+ num_quantizers (`int`, *optional*, defaults to 16):
+ Number of residual vector quantizers used in the vocoder for fine-grained audio reconstruction.
+ upsample_rates (`Tuple[int]`, *optional*, defaults to `(8, 5, 4, 3)`):
+ Rate at which features are upsampled in the final waveform synthesis stage.
+ upsampling_ratios (`Tuple[int]`, *optional*, defaults to `(2, 2)`):
+ Ratios used in transposed convolutional layers to progressively upsample feature maps to waveform.
+ decoder_dim (`int`, *optional*, defaults to 1536):
+ Final dimensionality of the decoder's output before waveform generation.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ Dropout probability applied to attention weights in the decoder.
+ """
+
+ def __init__(
+ self,
+ codebook_size=2048,
+ hidden_size=1024,
+ latent_dim=1024,
+ max_position_embeddings=8000,
+ rope_theta=10000,
+ num_attention_heads=16,
+ num_key_value_heads=16,
+ attention_bias=False,
+ sliding_window=72,
+ intermediate_size=3072,
+ hidden_act="silu",
+ layer_scale_initial_scale=0.01,
+ rms_norm_eps=1e-5,
+ num_hidden_layers=8,
+ num_quantizers=16,
+ upsample_rates=(8, 5, 4, 3),
+ upsampling_ratios=(2, 2),
+ decoder_dim=1536,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ self.codebook_size = codebook_size
+ self.hidden_size = hidden_size
+ self.latent_dim = latent_dim
+ self.max_position_embeddings = max_position_embeddings
+ self.rope_theta = rope_theta
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.attention_bias = attention_bias
+ self.sliding_window = sliding_window
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.layer_scale_initial_scale = layer_scale_initial_scale
+ self.rms_norm_eps = rms_norm_eps
+ self.num_hidden_layers = num_hidden_layers
+ self.num_quantizers = num_quantizers
+ self.upsample_rates = upsample_rates
+ self.upsampling_ratios = upsampling_ratios
+ self.decoder_dim = decoder_dim
+ self.attention_dropout = attention_dropout
+
+ @property
+ def layer_types(self):
+ """
+ All layer in code2wav should be sliding attention
+ """
+ return ["sliding_attention"] * self.num_hidden_layers
+
+
+class Qwen3TTSTokenizerV2Config(PretrainedConfig):
+ """
+ This is the configuration class to store the configuration of a [`Qwen3TTSTokenizerV2Config`]. It is used to instantiate a Qwen3TTSTokenizerV2Model
+ model according to the specified sub-models configurations, defining the model architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ encoder_config (`dict`, *optional*): Configuration of the underlying encoder sub-model.
+ decoder_config (`dict`, *optional*): Configuration of the underlying decoder sub-model.
+ """
+
+ model_type = "qwen3_tts_tokenizer_12hz"
+ sub_configs = {
+ "encoder_config": MimiConfig,
+ "decoder_config": Qwen3TTSTokenizerV2DecoderConfig,
+ }
+
+ def __init__(
+ self,
+ encoder_config=None,
+ decoder_config=None,
+ encoder_valid_num_quantizers=16,
+ input_sample_rate=24000,
+ output_sample_rate=24000,
+ decode_upsample_rate=1920,
+ encode_downsample_rate=1920,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ if encoder_config is None:
+ encoder_config = {}
+ logger.info("encoder_config is None. Initializing encoder with default values")
+ if decoder_config is None:
+ decoder_config = {}
+ logger.info("decoder_config is None. Initializing decoder with default values")
+
+ self.encoder_config = MimiConfig(**encoder_config)
+ self.decoder_config = Qwen3TTSTokenizerV2DecoderConfig(**decoder_config)
+
+ self.encoder_valid_num_quantizers = encoder_valid_num_quantizers
+ self.input_sample_rate = input_sample_rate
+ self.output_sample_rate = output_sample_rate
+ self.decode_upsample_rate = decode_upsample_rate
+ self.encode_downsample_rate = encode_downsample_rate
+
+
+__all__ = ["Qwen3TTSTokenizerV2Config", "Qwen3TTSTokenizerV2DecoderConfig"]
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/modeling_qwen3_tts_tokenizer_v2.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/modeling_qwen3_tts_tokenizer_v2.py
new file mode 100644
index 0000000..594febc
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_12hz/modeling_qwen3_tts_tokenizer_v2.py
@@ -0,0 +1,1025 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Qwen3TTSTokenizerV2 model."""
+
+import math
+from dataclasses import dataclass
+from typing import Callable, Optional, Union, List
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import Parameter
+from torch.nn import functional as F
+from transformers import MimiConfig, MimiModel
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.integrations import use_kernel_forward_from_hub
+from transformers.masking_utils import (
+ create_causal_mask,
+ create_sliding_window_causal_mask,
+)
+from transformers.modeling_flash_attention_utils import FlashAttentionKwargs
+from transformers.modeling_layers import GradientCheckpointingLayer
+from transformers.modeling_outputs import BaseModelOutputWithPast
+from transformers.modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
+from transformers.modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from transformers.processing_utils import Unpack
+from transformers.utils import ModelOutput, auto_docstring, logging
+from transformers.utils.deprecation import deprecate_kwarg
+from transformers.utils.generic import check_model_inputs
+
+from .configuration_qwen3_tts_tokenizer_v2 import (
+ Qwen3TTSTokenizerV2Config,
+ Qwen3TTSTokenizerV2DecoderConfig,
+)
+
+logger = logging.get_logger(__name__)
+
+
+@dataclass
+@auto_docstring
+class Qwen3TTSTokenizerV2EncoderOutput(ModelOutput):
+ r"""
+ audio_codes (`List[torch.LongTensor]`):
+ Discret code embeddings computed using `model.encode`, each tensor has shape (codes_length_i, num_quantizers).
+ """
+
+ audio_codes: List[torch.LongTensor] = None
+
+
+@dataclass
+@auto_docstring
+class Qwen3TTSTokenizerV2DecoderOutput(ModelOutput):
+ r"""
+ audio_values (`List[torch.FloatTensor]`):
+ Decoded audio values, obtained using the decoder part of Qwen3TTSTokenizerV1.
+ Each tensor has shape (segment_length_i).
+ """
+
+ audio_values: List[torch.FloatTensor] = None
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV2DecoderPreTrainedModel(PreTrainedModel):
+ config: Qwen3TTSTokenizerV2DecoderConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _can_compile_fullgraph = False
+ _supports_attention_backend = True
+
+
+class Qwen3TTSTokenizerV2CausalConvNet(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ dilation=1,
+ stride=1,
+ groups=1,
+ ):
+ super().__init__()
+ self.conv = nn.Conv1d(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=stride,
+ dilation=dilation,
+ groups=groups,
+ )
+ self.stride = stride
+ self.kernel_size = (kernel_size - 1) * dilation + 1
+ self.dilation = dilation
+ self.padding = self.kernel_size - self.stride
+
+ def _get_extra_padding_for_conv1d(self, hidden_state: torch.Tensor) -> int:
+ length = hidden_state.shape[-1]
+ n_frames = (length - self.kernel_size + self.padding) / self.stride + 1
+ ideal_length = (math.ceil(n_frames) - 1) * self.stride + (self.kernel_size - self.padding)
+ return ideal_length - length
+
+ def forward(self, hidden_state):
+ extra_padding = self._get_extra_padding_for_conv1d(hidden_state)
+ hidden_state = F.pad(hidden_state, (self.padding, extra_padding), mode="constant", value=0)
+ return self.conv(hidden_state).contiguous()
+
+
+class Qwen3TTSTokenizerV2CausalTransConvNet(nn.Module):
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1):
+ super().__init__()
+ self.conv = nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride=stride)
+
+ pad = kernel_size - stride
+ self.left_pad = math.ceil(pad)
+ self.right_pad = pad = self.left_pad
+
+ def forward(self, hidden_state):
+ hidden_state = self.conv(hidden_state)
+ hidden_state = hidden_state[..., self.left_pad : hidden_state.shape[-1] - self.right_pad]
+ return hidden_state.contiguous()
+
+
+class Qwen3TTSTokenizerV2ConvNeXtBlock(nn.Module):
+ def __init__(self, dim: int):
+ super().__init__()
+ self.dwconv = Qwen3TTSTokenizerV2CausalConvNet(
+ dim,
+ dim,
+ kernel_size=7,
+ groups=dim,
+ dilation=1,
+ )
+ self.norm = nn.LayerNorm(dim, eps=1e-6)
+ self.pwconv1 = nn.Linear(dim, 4 * dim)
+ self.act = nn.GELU()
+ self.pwconv2 = nn.Linear(4 * dim, dim)
+ self.gamma = nn.Parameter(1e-6 * torch.ones(dim))
+
+ def forward(self, hidden_states):
+ input = hidden_states
+
+ hidden_states = self.dwconv(hidden_states)
+ hidden_states = hidden_states.permute(0, 2, 1)
+ hidden_states = self.norm(hidden_states)
+ hidden_states = self.pwconv1(hidden_states)
+ hidden_states = self.act(hidden_states)
+ hidden_states = self.pwconv2(hidden_states)
+
+ hidden_states = self.gamma * hidden_states
+
+ hidden_states = hidden_states.permute(0, 2, 1)
+
+ hidden_states = input + hidden_states
+
+ return hidden_states
+
+
+class Qwen3TTSTokenizerV2DecoderRotatoryEmbedding(nn.Module):
+ inv_freq: torch.Tensor # fix linting for `register_buffer`
+
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and isinstance(config.rope_scaling, dict):
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ @torch.no_grad()
+ @dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
+ def forward(self, x, position_ids):
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
+ position_ids_expanded = position_ids[:, None, :].float()
+
+ device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False): # Force float32
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos() * self.attention_scaling
+ sin = emb.sin() * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+class Qwen3TTSTokenizerV2DecoderAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig, layer_idx):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+ self.q_norm = nn.Identity()
+ self.k_norm = nn.Identity()
+ self.sliding_window = config.sliding_window
+
+ @deprecate_kwarg("past_key_value", new_name="past_key_values", version="4.58")
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_values: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_values is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ sliding_window=self.sliding_window, # diff with Llama
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class Qwen3TTSTokenizerV2DecoderMlp(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+@use_kernel_forward_from_hub("RMSNorm")
+class Qwen3TTSTokenizerV2DecoderRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps: float = 1e-6) -> None:
+ """
+ Qwen3TTSTokenizerV2DecoderRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class Qwen3TTSTokenizerV2DecoderLayerScale(nn.Module):
+ """Layer scale from [Touvron et al 2021] (https://huggingface.co/papers/2103.17239).
+ This rescales diagonally the residual outputs close to 0, with a learnt scale.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ channels = config.hidden_size
+ initial_scale = config.layer_scale_initial_scale
+ self.scale = nn.Parameter(torch.full((channels,), initial_scale, requires_grad=True))
+
+ def forward(self, x: torch.Tensor):
+ return self.scale * x
+
+
+class Qwen3TTSTokenizerV2DecoderTransformerLayer(GradientCheckpointingLayer):
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig, layer_idx):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = Qwen3TTSTokenizerV2DecoderAttention(config, layer_idx)
+ self.mlp = Qwen3TTSTokenizerV2DecoderMlp(config)
+ self.input_layernorm = Qwen3TTSTokenizerV2DecoderRMSNorm(config.hidden_size, config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen3TTSTokenizerV2DecoderRMSNorm(config.hidden_size, config.rms_norm_eps)
+ self.self_attn_layer_scale = Qwen3TTSTokenizerV2DecoderLayerScale(config)
+ self.mlp_layer_scale = Qwen3TTSTokenizerV2DecoderLayerScale(config)
+ self.attention_type = "sliding_attention"
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_values (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence
+ kwargs (`dict`, *optional*):
+ Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
+ into the model
+ """
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ **kwargs,
+ )
+ hidden_states = residual + self.self_attn_layer_scale(hidden_states)
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + self.mlp_layer_scale(hidden_states)
+
+ return hidden_states
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV2DecoderTransformerModel(Qwen3TTSTokenizerV2DecoderPreTrainedModel):
+ _can_record_outputs = {
+ "hidden_states": Qwen3TTSTokenizerV2DecoderTransformerLayer,
+ "attentions": Qwen3TTSTokenizerV2DecoderAttention,
+ }
+
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig):
+ super().__init__(config)
+ self.layers = nn.ModuleList(
+ [Qwen3TTSTokenizerV2DecoderTransformerLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = Qwen3TTSTokenizerV2DecoderRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = Qwen3TTSTokenizerV2DecoderRotatoryEmbedding(config=config)
+ self.gradient_checkpointing = False
+ self.has_sliding_layers = "sliding_attention" in self.config.layer_types
+ self.window_size = config.sliding_window
+
+ self.input_proj = nn.Linear(config.latent_dim, config.hidden_size)
+ self.output_proj = nn.Linear(config.hidden_size, config.latent_dim)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @check_model_inputs()
+ @auto_docstring
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ past_key_values=None,
+ inputs_embeds=None,
+ use_cache=None,
+ cache_position=None,
+ **kwargs,
+ ) -> BaseModelOutputWithPast:
+ if input_ids is not None:
+ raise ValueError("input_ids is not expected")
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ inputs_embeds = self.input_proj(inputs_embeds)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache(config=self.config)
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ # It may already have been prepared by e.g. `generate`
+ if not isinstance(causal_mask_mapping := attention_mask, dict):
+ # Prepare mask arguments
+ mask_kwargs = {
+ "config": self.config,
+ "input_embeds": inputs_embeds,
+ "attention_mask": attention_mask,
+ "cache_position": cache_position,
+ "past_key_values": past_key_values,
+ "position_ids": position_ids,
+ }
+ # Create the masks
+ causal_mask_mapping = {
+ "full_attention": create_causal_mask(**mask_kwargs),
+ }
+ # The sliding window alternating layers are not always activated depending on the config
+ if self.has_sliding_layers:
+ causal_mask_mapping["sliding_attention"] = create_sliding_window_causal_mask(**mask_kwargs)
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ hidden_states = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask_mapping[decoder_layer.attention_type],
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = self.output_proj(hidden_states)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ )
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://huggingface.co/papers/2006.08195
+ """
+
+ def __init__(self, in_features, alpha=1.0):
+ super().__init__()
+ self.in_features = in_features
+
+ # initialize alpha
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, hidden_states):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ hidden_states = hidden_states + (1.0 / (beta + self.no_div_by_zero)) * torch.pow(
+ torch.sin(hidden_states * alpha), 2
+ )
+
+ return hidden_states
+
+
+class Qwen3TTSTokenizerV2DecoderDecoderResidualUnit(nn.Module):
+ def __init__(self, dim: int = 16, dilation: int = 1):
+ super().__init__()
+
+ self.act1 = SnakeBeta(dim)
+ self.conv1 = Qwen3TTSTokenizerV2CausalConvNet(dim, dim, kernel_size=7, dilation=dilation)
+ self.act2 = SnakeBeta(dim)
+ self.conv2 = Qwen3TTSTokenizerV2CausalConvNet(dim, dim, kernel_size=1)
+
+ def forward(self, hidden_state):
+ residual = hidden_state
+
+ hidden_state = self.act1(hidden_state)
+ hidden_state = self.conv1(hidden_state)
+ hidden_state = self.act2(hidden_state)
+ hidden_state = self.conv2(hidden_state)
+ return hidden_state + residual
+
+
+class Qwen3TTSTokenizerV2DecoderDecoderBlock(Qwen3TTSTokenizerV2DecoderPreTrainedModel):
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig, layer_idx):
+ super().__init__(config)
+ in_dim = config.decoder_dim // 2**layer_idx
+ out_dim = config.decoder_dim // 2 ** (layer_idx + 1)
+ upsample_rate = config.upsample_rates[layer_idx]
+
+ block = [
+ SnakeBeta(in_dim),
+ Qwen3TTSTokenizerV2CausalTransConvNet(in_dim, out_dim, 2 * upsample_rate, upsample_rate),
+ ]
+
+ for dilation in (1, 3, 9):
+ block.append(Qwen3TTSTokenizerV2DecoderDecoderResidualUnit(out_dim, dilation))
+
+ self.block = nn.ModuleList(block)
+
+ def forward(self, hidden):
+ for block in self.block:
+ hidden = block(hidden)
+ return hidden
+
+
+class EuclideanCodebook(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ codebook_size: int,
+ epsilon: float = 1e-5,
+ ):
+ super().__init__()
+ self.dim = dim
+ self.codebook_size = codebook_size
+ self.epsilon = epsilon
+
+ self.cluster_usage = nn.Parameter(torch.ones(codebook_size))
+ self.embedding_sum = nn.Parameter(torch.zeros(codebook_size, dim))
+
+ def decode(self, codes: torch.Tensor) -> torch.Tensor:
+ embedding = self.embedding_sum / self.cluster_usage.clamp(min=self.epsilon)[:, None]
+ quantized = F.embedding(codes, embedding)
+ return quantized
+
+
+class VectorQuantization(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ codebook_size: int,
+ codebook_dim: Optional[int] = None,
+ epsilon: float = 1e-5,
+ ):
+ super().__init__()
+ if codebook_dim is None:
+ codebook_dim = dim
+
+ requires_projection = codebook_dim != dim
+
+ self.project_out = (
+ nn.Linear(codebook_dim, dim) if requires_projection else nn.Identity()
+ )
+ self.epsilon = epsilon
+ self._codebook = EuclideanCodebook(
+ dim=codebook_dim,
+ codebook_size=codebook_size,
+ epsilon=epsilon
+ )
+ self.codebook_size = codebook_size
+
+ def decode(self, codes: torch.Tensor) -> torch.Tensor:
+ quantized = self._codebook.decode(codes)
+ quantized = self.project_out(quantized)
+ quantized = quantized.transpose(1, 2)
+ return quantized
+
+
+class ResidualVectorQuantization(nn.Module):
+ def __init__(self, *, num_quantizers: int, **kwargs):
+ super().__init__()
+ self.layers = nn.ModuleList(
+ [VectorQuantization(**kwargs) for _ in range(num_quantizers)]
+ )
+
+ def decode(self, codes: torch.Tensor) -> torch.Tensor:
+ quantized = torch.zeros([1], device=codes.device)[0]
+ for idx, layer_codes in enumerate(codes):
+ layer = self.layers[idx]
+ assert isinstance(layer, VectorQuantization)
+ quantized = quantized + layer.decode(layer_codes)
+ return quantized
+
+
+class ResidualVectorQuantizer(nn.Module):
+ def __init__(
+ self,
+ dimension: int = 128,
+ input_dimension: Optional[int] = None,
+ output_dimension: Optional[int] = None,
+ n_q: int = 8,
+ q_dropout: bool = False,
+ no_quantization_rate: float = 0.0,
+ bins: int = 1024,
+ decay: float = 0.99,
+ force_projection: bool = False,
+ ):
+ super().__init__()
+ self.max_n_q = n_q
+ self.n_q = n_q
+ self.q_dropout = q_dropout
+ self.no_quantization_rate = no_quantization_rate
+ self.dimension = dimension
+ self.input_dimension = input_dimension or dimension
+ self.output_dimension = output_dimension or dimension
+ self.bins = bins
+ self.decay = decay
+ self.input_proj: torch.nn.Module
+ self.output_proj: torch.nn.Module
+ if self.input_dimension == self.dimension and not force_projection:
+ self.input_proj = torch.nn.Identity()
+ else:
+ self.input_proj = torch.nn.Conv1d(
+ self.input_dimension, self.dimension, 1, bias=False
+ )
+ if self.output_dimension == self.dimension and not force_projection:
+ self.output_proj = torch.nn.Identity()
+ else:
+ self.output_proj = torch.nn.Conv1d(
+ self.dimension, self.output_dimension, 1, bias=False
+ )
+ self.vq = ResidualVectorQuantization(
+ dim=self.dimension,
+ codebook_size=self.bins,
+ num_quantizers=self.n_q
+ )
+
+ def decode(self, codes: torch.Tensor) -> torch.Tensor:
+ codes = codes.transpose(0, 1)
+ quantized = self.vq.decode(codes)
+ quantized = self.output_proj(quantized)
+ return quantized
+
+
+class SplitResidualVectorQuantizer(nn.Module):
+ """Residual Vector Quantizer with separate projections for the first quantizer and the rest.
+
+ Args:
+ n_q (int): Number of residual vector quantizers used.
+ n_semantic_q (int): Number of residual vector quantizers used for the semantic quantizer.
+ **kwargs: Arguments to the constructor of `ResidualVectorQuantizer` that are shared between both.
+ """
+
+ def __init__(
+ self,
+ *,
+ n_q: int = 8,
+ n_q_semantic: int = 1,
+ **kwargs,
+ ):
+ super().__init__()
+ assert n_q > n_q_semantic, (
+ f"Number of quantizers {n_q} must be larger "
+ f"than the number of semantic quantizers {n_q_semantic}."
+ )
+ self.max_n_q = n_q
+ self.n_q_semantic = n_q_semantic
+ self.n_q_acoustic = n_q - n_q_semantic
+ q_dropout = kwargs.pop("q_dropout", False)
+ self.rvq_first = ResidualVectorQuantizer(
+ n_q=n_q_semantic, force_projection=True, q_dropout=False, **kwargs
+ )
+ self.rvq_rest = ResidualVectorQuantizer(
+ n_q=n_q - n_q_semantic,
+ force_projection=True,
+ q_dropout=q_dropout,
+ **kwargs,
+ )
+
+ def decode(self, codes: torch.Tensor) -> torch.Tensor:
+ """Decode the given codes to the quantized representation."""
+ # codes is [B, K, T], with T frames, K nb of codebooks.
+ quantized = self.rvq_first.decode(codes[:, : self.n_q_semantic])
+ if codes.shape[1] > self.n_q_semantic:
+ quantized += self.rvq_rest.decode(codes[:, self.n_q_semantic :])
+ return quantized
+
+
+class Qwen3TTSTokenizerV2Decoder(Qwen3TTSTokenizerV2DecoderPreTrainedModel):
+ def __init__(self, config: Qwen3TTSTokenizerV2DecoderConfig):
+ super().__init__(config)
+ self.total_upsample = np.prod(config.upsample_rates + config.upsampling_ratios)
+ self.pre_transformer = Qwen3TTSTokenizerV2DecoderTransformerModel._from_config(config)
+
+ self.quantizer = SplitResidualVectorQuantizer(
+ dimension=config.codebook_dim // 2,
+ n_q=config.num_quantizers,
+ n_q_semantic=1,
+ bins=config.codebook_size,
+ input_dimension=config.codebook_dim,
+ output_dimension=config.codebook_dim,
+ )
+
+ self.pre_conv = Qwen3TTSTokenizerV2CausalConvNet(
+ config.codebook_dim,
+ config.latent_dim,
+ kernel_size=3,
+ )
+
+ upsample = []
+ for factor in config.upsampling_ratios:
+ upsample.append(
+ nn.ModuleList(
+ [
+ Qwen3TTSTokenizerV2CausalTransConvNet(config.latent_dim, config.latent_dim, factor, factor),
+ Qwen3TTSTokenizerV2ConvNeXtBlock(config.latent_dim),
+ ]
+ )
+ )
+ self.upsample = nn.ModuleList(upsample)
+
+ decoder = [Qwen3TTSTokenizerV2CausalConvNet(config.latent_dim, config.decoder_dim, 7)]
+ for i in range(len(config.upsample_rates)):
+ decoder.append(Qwen3TTSTokenizerV2DecoderDecoderBlock(config, i))
+ output_dim = config.decoder_dim // 2 ** len(config.upsample_rates)
+ decoder += [
+ SnakeBeta(output_dim),
+ Qwen3TTSTokenizerV2CausalConvNet(output_dim, 1, 7),
+ ]
+ self.decoder = nn.ModuleList(decoder)
+
+ self.post_init()
+
+ def forward(self, codes):
+ if codes.shape[1] != self.config.num_quantizers:
+ raise ValueError(f"Expected {self.config.num_quantizers} layer of codes, got {codes.shape[1]}")
+
+ hidden = self.quantizer.decode(codes)
+ hidden = self.pre_conv(hidden).transpose(1, 2)
+
+ hidden = self.pre_transformer(inputs_embeds=hidden).last_hidden_state
+ hidden = hidden.permute(0, 2, 1)
+ for blocks in self.upsample:
+ for block in blocks:
+ hidden = block(hidden)
+ wav = hidden
+ for block in self.decoder:
+ wav = block(wav)
+ return wav.clamp(min=-1, max=1)
+
+ def chunked_decode(self, codes, chunk_size=300, left_context_size=25):
+ wavs = []
+ start_index = 0
+ while start_index < codes.shape[-1]:
+ end_index = min(start_index + chunk_size, codes.shape[-1])
+ context_size = left_context_size if start_index - left_context_size > 0 else start_index
+ codes_chunk = codes[..., start_index - context_size : end_index]
+ wav_chunk = self(codes_chunk)
+ wavs.append(wav_chunk[..., context_size * self.total_upsample :])
+ start_index = end_index
+ return torch.cat(wavs, dim=-1)
+
+
+class Qwen3TTSTokenizerV2Encoder(MimiModel):
+ def __init__(self, config: MimiConfig):
+ super().__init__(config)
+ self.config = config
+
+ self.upsample = None
+ self.decoder_transformer = None
+ self.decoder = None
+
+ self.post_init()
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV2PreTrainedModel(PreTrainedModel):
+ config: Qwen3TTSTokenizerV2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _can_compile_fullgraph = False
+ _supports_attention_backend = True
+
+
+@auto_docstring(
+ custom_intro="""
+ The Qwen3TTSTokenizerV2 model.
+ """
+)
+class Qwen3TTSTokenizerV2Model(Qwen3TTSTokenizerV2PreTrainedModel):
+ def __init__(self, config: Qwen3TTSTokenizerV2Config):
+ super().__init__(config)
+ self.config = config
+
+ self.encoder_valid_num_quantizers = config.encoder_valid_num_quantizers
+
+ self.input_sample_rate = config.input_sample_rate
+ self.output_sample_rate = config.output_sample_rate
+
+ self.decode_upsample_rate = config.decode_upsample_rate
+ self.encode_downsample_rate = config.encode_downsample_rate
+
+ self.encoder = Qwen3TTSTokenizerV2Encoder._from_config(self.config.encoder_config)
+ self.decoder = Qwen3TTSTokenizerV2Decoder._from_config(self.config.decoder_config)
+
+ self.post_init()
+
+ def get_model_type(self):
+ return self.config.model_type
+
+ def get_input_sample_rate(self):
+ return self.input_sample_rate
+
+ def get_output_sample_rate(self):
+ return self.output_sample_rate
+
+ def get_encode_downsample_rate(self):
+ return self.encode_downsample_rate
+
+ def get_decode_upsample_rate(self):
+ return self.decode_upsample_rate
+
+ def encode(
+ self,
+ input_values: torch.Tensor,
+ padding_mask: Optional[torch.Tensor] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor, Optional[torch.Tensor]], Qwen3TTSTokenizerV2EncoderOutput]:
+ """
+ Encodes the input audio waveform into discrete codes.
+
+ Args:
+ input_values (`torch.Tensor` of shape `(batch_size, sequence_length)`):
+ Float values of the input audio waveform.
+ padding_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`):
+ Indicates which inputs are to be ignored due to padding, where elements are either 1 for *not masked* or 0
+ for *masked*.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.return_dict
+
+ encoded_frames = self.encoder.encode(input_values=input_values.unsqueeze(1),
+ return_dict=True)
+ audio_codes = encoded_frames.audio_codes[:, :self.encoder_valid_num_quantizers]
+ audio_codes = [code[..., :-(-mask.sum() // self.encode_downsample_rate)].transpose(0, 1) for code, mask in zip(audio_codes, padding_mask)]
+
+ if not return_dict:
+ return (
+ audio_codes,
+ )
+
+ return Qwen3TTSTokenizerV2EncoderOutput(audio_codes)
+
+ def decode(
+ self,
+ audio_codes: torch.Tensor,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor, torch.Tensor], Qwen3TTSTokenizerV2DecoderOutput]:
+ """
+ Decodes the given frames into an output audio waveform.
+
+ Note that the output might be a bit bigger than the input. In that case, any extra steps at the end can be
+ trimmed.
+
+ Args:
+ audio_codes (`torch.LongTensor` of shape `(batch_size, codes_length, num_quantizers)`, *optional*):
+ Discret code embeddings computed using `model.encode`.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+ """
+ return_dict = return_dict if return_dict is not None else self.config.return_dict
+
+ audio_values = self.decoder.chunked_decode(audio_codes.transpose(1, 2)).squeeze(1)
+
+ audio_lengths = (audio_codes[..., 0] > 0).sum(1) * self.decode_upsample_rate
+ audio_values = [a[:l] for a, l in zip(audio_values, audio_lengths)]
+
+ if not return_dict:
+ return (
+ audio_values,
+ )
+
+ return Qwen3TTSTokenizerV2DecoderOutput(audio_values)
+
+
+__all__ = ["Qwen3TTSTokenizerV2Model", "Qwen3TTSTokenizerV2PreTrainedModel"]
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/configuration_qwen3_tts_tokenizer_v1.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/configuration_qwen3_tts_tokenizer_v1.py
new file mode 100644
index 0000000..50751db
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/configuration_qwen3_tts_tokenizer_v1.py
@@ -0,0 +1,332 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Qwen3TTSTokenizerV1 model configuration"""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class Qwen3TTSTokenizerV1DecoderDiTConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of the Qwen3TTSTokenizerV1DecoderToken2WavDiT.
+ It defines the architecture of the DiT model, which is used for generating mel-spectrograms from tokens.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 1024):
+ The dimension of the model.
+ num_hidden_layers (`int`, *optional*, defaults to 22):
+ The number of transformer blocks in the DiT model.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ The number of attention heads in each transformer block.
+ ff_mult (`int`, *optional*, defaults to 2):
+ The multiplier for the feedforward layer in each transformer block.
+ emb_dim (`int`, *optional*, defaults to 512):
+ The dimension of the embedding layer.
+ head_dim (`int`, *optional*, defaults to 64):
+ The dimension of each attention head.
+ repeats (`int`, *optional*, defaults to 2):
+ The number of times the codec embeddings are repeated.
+ num_embeds (`int`, *optional*, defaults to 8193):
+ The number of unique embeddings in the codec.
+ mel_dim (`int`, *optional*, defaults to 80):
+ The dimension of the mel-spectrogram.
+ dropout (`float`, *optional*, defaults to 0.1):
+ The dropout rate for the transformer blocks.
+
+ enc_emb_dim (`int`, *optional*, defaults to 192):
+ The dimension of the pre-trained speaker embedding.
+ enc_dim (`int`, *optional*, defaults to 128):
+ The dimension of the encoder output.
+ enc_channels (`list[int]`, *optional*, defaults to `[256, 256, 256, 256, 768]`):
+ A list of output channels for each TDNN/SERes2Net layer in the encoder.
+ enc_kernel_sizes (`list[int]`, *optional*, defaults to `[5, 3, 3, 3, 1]`):
+ A list of kernel sizes for each layer in the encoder.
+ enc_dilations (`list[int]`, *optional*, defaults to `[1, 2, 3, 4, 1]`):
+ A list of dilations for each layer in the encoder.
+ enc_attention_channels (`int`, *optional*, defaults to 64):
+ The number of attention channels in the SqueezeExcitationBlock.
+ enc_res2net_scale (`int`, *optional*, defaults to 2):
+ The scale of the Res2Net block in the encoder.
+ enc_se_channels (`int`, *optional*, defaults to 64):
+ The number of output channels after squeeze in the SqueezeExcitationBlock.
+ """
+
+ model_type = "qwen3_tts_tokenizer_v1_decoder_dit"
+
+ def __init__(
+ self,
+ hidden_size=1024,
+ num_hidden_layers=22,
+ num_attention_heads=16,
+ ff_mult=2,
+ emb_dim=512,
+ head_dim=64,
+ rope_theta=10000.0,
+ max_position_embeddings=32768,
+ block_size=24,
+ look_ahead_layers=[10],
+ look_backward_layers=[0, 20],
+ repeats=2,
+ num_embeds=8193,
+ mel_dim=80,
+ dropout=0.1,
+ enc_emb_dim=192,
+ enc_dim=128,
+ enc_channels=[256, 256, 256, 256, 768],
+ enc_kernel_sizes=[5, 3, 3, 3, 1],
+ enc_dilations=[1, 2, 3, 4, 1],
+ enc_attention_channels=64,
+ enc_res2net_scale=2,
+ enc_se_channels=64,
+ **kwargs,
+ ):
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.ff_mult = ff_mult
+ self.emb_dim = emb_dim
+ self.head_dim = head_dim
+ self.rope_theta = rope_theta
+ self.max_position_embeddings = max_position_embeddings
+ self.block_size = block_size
+ self.look_ahead_layers = look_ahead_layers
+ self.look_backward_layers = look_backward_layers
+ self.repeats = repeats
+ self.num_embeds = num_embeds
+ self.mel_dim = mel_dim
+ self.dropout = dropout
+ self.enc_emb_dim = enc_emb_dim
+ self.enc_dim = enc_dim
+ self.enc_channels = enc_channels
+ self.enc_kernel_sizes = enc_kernel_sizes
+ self.enc_dilations = enc_dilations
+ self.enc_attention_channels = enc_attention_channels
+ self.enc_res2net_scale = enc_res2net_scale
+ self.enc_se_channels = enc_se_channels
+ super().__init__(**kwargs)
+
+
+class Qwen3TTSTokenizerV1DecoderBigVGANConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of the Qwen3TTSTokenizerV1DecoderToken2WavBigVGAN module.
+ It defines the architecture of the BigVGAN model, which is used for converting mel-spectrograms to waveforms.
+
+ Args:
+ mel_dim (`int`, *optional*, defaults to 80):
+ The dimension of the mel-spectrogram.
+ upsample_initial_channel (`int`, *optional*, defaults to 1536):
+ The number of channels in the initial upsampling layer.
+ resblock_kernel_sizes (`list[int]`, *optional*, defaults to `[3, 7, 11]`):
+ A list of kernel sizes for each residual block.
+ resblock_dilation_sizes (`list[list[int]]`, *optional*, defaults to `[[1, 3, 5], [1, 3, 5], [1, 3, 5]]`):
+ A list of dilation sizes for each residual block.
+ upsample_rates (`list[int]`, *optional*, defaults to `[5, 3, 2, 2, 2, 2]`):
+ A list of upsampling rates for each upsampling layer.
+ upsample_kernel_sizes (`list[int]`, *optional*, defaults to `[11, 7, 4, 4, 4, 4]`):
+ A list of kernel sizes for each upsampling layer.
+ """
+
+ model_type = "qwen3_tts_tokenizer_v1_decoder_bigvgan"
+
+ def __init__(
+ self,
+ mel_dim=80,
+ upsample_initial_channel=1536,
+ resblock_kernel_sizes=[3, 7, 11],
+ resblock_dilation_sizes=[[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ upsample_rates=[5, 3, 2, 2, 2, 2],
+ upsample_kernel_sizes=[11, 7, 4, 4, 4, 4],
+ **kwargs,
+ ):
+ self.mel_dim = mel_dim
+ self.upsample_initial_channel = upsample_initial_channel
+ self.resblock_kernel_sizes = resblock_kernel_sizes
+ self.resblock_dilation_sizes = resblock_dilation_sizes
+ self.upsample_rates = upsample_rates
+ self.upsample_kernel_sizes = upsample_kernel_sizes
+ super().__init__(**kwargs)
+
+
+class Qwen3TTSTokenizerV1DecoderConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen3TTSTokenizerV1DecoderConfig`].
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ dit_config ([`DiT_Args`], *optional*):
+ Configuration class for the Diffusion Transformer (DiT) module responsible for generating mel-spectrograms.
+ bigvgan_config ([`BigVGAN_Args`], *optional*):
+ Configuration class for the BigVGAN module responsible for converting mel-spectrograms to waveforms.
+ """
+
+ model_type = "qwen3_tts_tokenizer_v1_decoder"
+ sub_configs = {
+ "dit_config": Qwen3TTSTokenizerV1DecoderDiTConfig,
+ "bigvgan_config": Qwen3TTSTokenizerV1DecoderBigVGANConfig,
+ }
+
+ def __init__(self, dit_config=None, bigvgan_config=None, **kwargs):
+ if dit_config is None:
+ dit_config = {}
+ if bigvgan_config is None:
+ bigvgan_config = {}
+ self.dit_config = Qwen3TTSTokenizerV1DecoderDiTConfig(**dit_config)
+ self.bigvgan_config = Qwen3TTSTokenizerV1DecoderBigVGANConfig(**bigvgan_config)
+ super().__init__(**kwargs)
+
+
+class Qwen3TTSTokenizerV1EncoderConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of the Qwen3TTSTokenizerV1 Encoder.
+
+ The encoder typically takes mel-spectrogram features and produces high-level audio representations, then (optionally)
+ applies an Audio-VQ module (e.g., GRVQ) to discretize continuous representations into codes.
+
+ Args:
+ n_mels (`int`, *optional*, defaults to 128):
+ Number of mel bins in the input mel-spectrogram.
+ n_ctx (`int`, *optional*, defaults to 1500):
+ Maximum input sequence length (in frames/tokens) for the encoder.
+ n_state (`int`, *optional*, defaults to 1280):
+ Hidden size (model dimension) of the encoder transformer.
+ n_head (`int`, *optional*, defaults to 20):
+ Number of attention heads in each transformer layer.
+ n_layer (`int`, *optional*, defaults to 32):
+ Number of transformer layers.
+ n_window (`int`, *optional*, defaults to 100):
+ Window size used by the model for local attention / chunking (implementation-dependent).
+ output_dim (`int`, *optional*, defaults to 3584):
+ Output feature dimension produced by the encoder head (before/after projection, implementation-dependent).
+
+ grad_checkpointing (`bool`, *optional*, defaults to `False`):
+ Whether to enable gradient checkpointing to reduce memory usage during training.
+ enable_mp (`bool`, *optional*, defaults to `False`):
+ Whether to enable model parallel features (implementation-dependent).
+ audio_sequence_parallel (`bool`, *optional*, defaults to `False`):
+ Whether to enable sequence parallelism for audio branch (implementation-dependent).
+
+ audio_vq_type (`str`, *optional*, defaults to `"GRVQ"`):
+ Type of audio vector-quantization module. Common choices: `"GRVQ"`, `"RVQ"`, etc.
+ audio_vq_layers (`int`, *optional*, defaults to 6):
+ Number of VQ layers / quantizers (e.g., number of residual quantizers for RVQ/GRVQ-like designs).
+ audio_vq_codebook_size (`int`, *optional*, defaults to 32768):
+ Size of each codebook (number of entries).
+ audio_vq_codebook_dim (`int`, *optional*, defaults to 1280):
+ Dimension of codebook vectors (often equals encoder hidden size).
+ audio_vq_pe (`bool`, *optional*, defaults to `True`):
+ Whether to use positional encoding (or position embeddings) inside the VQ module.
+ audio_vq_ds_rate (`int`, *optional*, defaults to 2):
+ Downsampling rate applied before VQ (e.g., temporal downsample factor).
+ """
+
+ model_type = "qwen3_tts_tokenizer_v1_encoder"
+
+ def __init__(
+ self,
+ n_mels=128,
+ n_ctx=1500,
+ n_state=1280,
+ n_head=20,
+ n_layer=32,
+ n_window=100,
+ output_dim=3584,
+ grad_checkpointing=False,
+ enable_mp=False,
+ audio_sequence_parallel=False,
+ audio_vq_type="GRVQ",
+ audio_vq_layers=6,
+ audio_vq_codebook_size=32768,
+ audio_vq_codebook_dim=1280,
+ audio_vq_pe=True,
+ audio_vq_ds_rate=2,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ self.n_mels = n_mels
+ self.n_ctx = n_ctx
+ self.n_state = n_state
+ self.n_head = n_head
+ self.n_layer = n_layer
+ self.n_window = n_window
+ self.output_dim = output_dim
+ self.grad_checkpointing = grad_checkpointing
+ self.enable_mp = enable_mp
+ self.audio_sequence_parallel = audio_sequence_parallel
+ self.audio_vq_type = audio_vq_type
+ self.audio_vq_layers = audio_vq_layers
+ self.audio_vq_codebook_size = audio_vq_codebook_size
+ self.audio_vq_codebook_dim = audio_vq_codebook_dim
+ self.audio_vq_pe = audio_vq_pe
+ self.audio_vq_ds_rate = audio_vq_ds_rate
+
+
+class Qwen3TTSTokenizerV1Config(PretrainedConfig):
+ """
+ This is the configuration class to store the configuration of a [`Qwen3TTSTokenizerV1Config`]. It is used to instantiate a Qwen3TTSTokenizerV1Model
+ model according to the specified sub-models configurations, defining the model architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ encoder_config (`dict`, *optional*): Configuration of the underlying encoder sub-model.
+ decoder_config (`dict`, *optional*): Configuration of the underlying decoder sub-model.
+ """
+
+ model_type = "qwen3_tts_tokenizer_25hz"
+ sub_configs = {
+ "encoder_config": Qwen3TTSTokenizerV1EncoderConfig,
+ "decoder_config": Qwen3TTSTokenizerV1DecoderConfig,
+ }
+
+ def __init__(
+ self,
+ encoder_config=None,
+ decoder_config=None,
+ input_sample_rate=24000,
+ output_sample_rate=24000,
+ decode_upsample_rate=1920,
+ encode_downsample_rate=1920,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ if encoder_config is None:
+ encoder_config = {}
+ logger.info("encoder_config is None. Initializing encoder with default values")
+ if decoder_config is None:
+ decoder_config = {}
+ logger.info("decoder_config is None. Initializing decoder with default values")
+
+ self.encoder_config = Qwen3TTSTokenizerV1EncoderConfig(**encoder_config)
+ self.decoder_config = Qwen3TTSTokenizerV1DecoderConfig(**decoder_config)
+
+ self.input_sample_rate = input_sample_rate
+ self.output_sample_rate = output_sample_rate
+ self.decode_upsample_rate = decode_upsample_rate
+ self.encode_downsample_rate = encode_downsample_rate
+
+
+__all__ = [
+ "Qwen3TTSTokenizerV1Config",
+ "Qwen3TTSTokenizerV1EncoderConfig",
+ "Qwen3TTSTokenizerV1DecoderConfig",
+ "Qwen3TTSTokenizerV1DecoderBigVGANConfig",
+ "Qwen3TTSTokenizerV1DecoderDiTConfig"
+]
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/modeling_qwen3_tts_tokenizer_v1.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/modeling_qwen3_tts_tokenizer_v1.py
new file mode 100644
index 0000000..8a38d92
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/modeling_qwen3_tts_tokenizer_v1.py
@@ -0,0 +1,1528 @@
+# coding=utf-8
+# Copyright 2026 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Qwen3TTSTokenizerV1 model."""
+
+import math
+from dataclasses import dataclass
+from typing import Optional, Union, List
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import Parameter
+from torch.nn import functional as F
+from transformers.modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from transformers.utils import ModelOutput, auto_docstring, logging
+from transformers.utils.hub import cached_file
+
+from torch.nn.utils.rnn import pad_sequence
+
+from .vq.whisper_encoder import get_mel_audio, get_T_after_cnn
+from .vq.speech_vq import WhisperEncoderVQ, XVectorExtractor
+
+from .configuration_qwen3_tts_tokenizer_v1 import (
+ Qwen3TTSTokenizerV1Config,
+ Qwen3TTSTokenizerV1EncoderConfig,
+ Qwen3TTSTokenizerV1DecoderConfig,
+ Qwen3TTSTokenizerV1DecoderBigVGANConfig,
+ Qwen3TTSTokenizerV1DecoderDiTConfig
+)
+
+logger = logging.get_logger(__name__)
+
+
+@dataclass
+@auto_docstring
+class Qwen3TTSTokenizerV1EncoderOutput(ModelOutput):
+ r"""
+ audio_codes (`List[torch.LongTensor]`):
+ Discret code embeddings computed using `model.encode`, each tensor has shape (codes_length_i,).
+ xvectors (`List[torch.FloatTensor]`):
+ X-vector embeddings computed using `model.encode`, each tensor has shape (xvector_dim,).
+ ref_mels (`List[torch.FloatTensor]`):
+ Reference mel spectrogram computed using `model.encode`, each tensor has shape (mel_length_i, mel_dim,).
+ """
+
+ audio_codes: List[torch.LongTensor] = None
+ xvectors: List[torch.FloatTensor] = None
+ ref_mels: List[torch.FloatTensor] = None
+
+
+@dataclass
+@auto_docstring
+class Qwen3TTSTokenizerV1DecoderOutput(ModelOutput):
+ r"""
+ audio_values (`List[torch.FloatTensor]`):
+ Decoded audio values, obtained using the decoder part of Qwen3TTSTokenizerV1.
+ Each tensor has shape (segment_length_i).
+ """
+
+ audio_values: List[torch.FloatTensor] = None
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1DecoderPreTrainedModel(PreTrainedModel):
+ config: Qwen3TTSTokenizerV1DecoderConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _can_compile_fullgraph = False
+ _supports_attention_backend = True
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1EncoderPreTrainedModel(PreTrainedModel):
+ config: Qwen3TTSTokenizerV1EncoderConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _can_compile_fullgraph = False
+ _supports_attention_backend = True
+
+
+class Qwen3TTSTokenizerV1DecoderDiTRotaryEmbedding(nn.Module):
+ inv_freq: torch.Tensor # fix linting for `register_buffer`
+
+ def __init__(self, dim, base=10000):
+ super().__init__()
+
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
+ self.register_buffer("inv_freq", inv_freq)
+
+ def forward(self, x):
+ batch_size, seq_len = x.shape[0], x.shape[1]
+ t = torch.arange(seq_len, device=x.device)
+ device_type = x.device.type
+ device_type = device_type if device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = t.unsqueeze(1).float() @ self.inv_freq.unsqueeze(0).float()
+ freqs = torch.stack((freqs, freqs), dim=-1)
+ freqs = freqs.reshape(*freqs.shape[:-2], -1)
+ freqs = freqs.repeat(batch_size, *([1] * freqs.dim()))
+ cos = freqs.cos()
+ sin = freqs.sin()
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+class TimeDelayNetBlock(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ dilation,
+ ):
+ super().__init__()
+ self.conv = nn.Conv1d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.activation = nn.ReLU()
+
+ def forward(self, hidden_states: torch.Tensor):
+ return self.activation(self.conv(hidden_states))
+
+
+class Res2NetBlock(torch.nn.Module):
+ def __init__(self, in_channels, out_channels, scale=8, kernel_size=3, dilation=1):
+ super().__init__()
+
+ in_channel = in_channels // scale
+ hidden_channel = out_channels // scale
+
+ self.blocks = nn.ModuleList(
+ [
+ TimeDelayNetBlock(
+ in_channel,
+ hidden_channel,
+ kernel_size=kernel_size,
+ dilation=dilation,
+ )
+ for i in range(scale - 1)
+ ]
+ )
+ self.scale = scale
+
+ def forward(self, hidden_states):
+ outputs = []
+ for i, hidden_part in enumerate(torch.chunk(hidden_states, self.scale, dim=1)):
+ if i == 0:
+ output_part = hidden_part
+ elif i == 1:
+ output_part = self.blocks[i - 1](hidden_part)
+ else:
+ output_part = self.blocks[i - 1](hidden_part + output_part)
+ outputs.append(output_part)
+ output = torch.cat(outputs, dim=1)
+ return output
+
+
+class SqueezeExcitationBlock(nn.Module):
+ def __init__(self, in_channels, se_channels, out_channels):
+ super().__init__()
+
+ self.conv1 = nn.Conv1d(
+ in_channels=in_channels,
+ out_channels=se_channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.relu = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv1d(
+ in_channels=se_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+ self.sigmoid = nn.Sigmoid()
+
+ def forward(self, hidden_states):
+ hidden_states_mean = hidden_states.mean(dim=2, keepdim=True)
+
+ hidden_states_mean = self.relu(self.conv1(hidden_states_mean))
+ hidden_states_mean = self.sigmoid(self.conv2(hidden_states_mean))
+
+ return hidden_states * hidden_states_mean
+
+
+class AttentiveStatisticsPooling(nn.Module):
+ """This class implements an attentive statistic pooling layer for each channel.
+ It returns the concatenated mean and std of the input tensor.
+ """
+
+ def __init__(self, channels, attention_channels=128):
+ super().__init__()
+
+ self.eps = 1e-12
+ self.tdnn = TimeDelayNetBlock(channels * 3, attention_channels, 1, 1)
+ self.tanh = nn.Tanh()
+ self.conv = nn.Conv1d(
+ in_channels=attention_channels,
+ out_channels=channels,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+
+ def _length_to_mask(self, length, max_len=None, dtype=None, device=None):
+ """Creates a binary mask for each sequence.
+
+ Reference: https://discuss.pytorch.org/t/how-to-generate-variable-length-mask/23397/3
+
+ Arguments
+ ---------
+ length : torch.LongTensor
+ Containing the length of each sequence in the batch. Must be 1D.
+ max_len : int
+ Max length for the mask, also the size of the second dimension.
+ dtype : torch.dtype, default: None
+ The dtype of the generated mask.
+ device: torch.device, default: None
+ The device to put the mask variable.
+
+ Returns
+ -------
+ mask : tensor
+ The binary mask.
+ """
+
+ if max_len is None:
+ max_len = length.max().long().item() # using arange to generate mask
+ mask = torch.arange(max_len, device=length.device, dtype=length.dtype).expand(
+ len(length), max_len
+ ) < length.unsqueeze(1)
+
+ mask = torch.as_tensor(mask, dtype=dtype, device=device)
+ return mask
+
+ def _compute_statistics(self, x, m, dim=2):
+ mean = (m * x).sum(dim)
+ std = torch.sqrt((m * (x - mean.unsqueeze(dim)).pow(2)).sum(dim).clamp(self.eps))
+ return mean, std
+
+ def forward(self, hidden_states):
+ seq_length = hidden_states.shape[-1]
+ lengths = torch.ones(hidden_states.shape[0], device=hidden_states.device)
+
+ # Make binary mask of shape [N, 1, L]
+ mask = self._length_to_mask(
+ lengths * seq_length, max_len=seq_length, dtype=hidden_states.dtype, device=hidden_states.device
+ )
+ mask = mask.unsqueeze(1)
+
+ # Expand the temporal context of the pooling layer by allowing the
+ # self-attention to look at global properties of the utterance.
+ total = mask.sum(dim=2, keepdim=True)
+
+ mean, std = self._compute_statistics(hidden_states, mask / total)
+ mean = mean.unsqueeze(2).repeat(1, 1, seq_length)
+ std = std.unsqueeze(2).repeat(1, 1, seq_length)
+ attention = torch.cat([hidden_states, mean, std], dim=1)
+
+ # Apply layers
+ attention = self.conv(self.tanh(self.tdnn(attention)))
+
+ # Filter out zero-paddings
+ attention = attention.masked_fill(mask == 0, float("-inf"))
+
+ attention = F.softmax(attention, dim=2)
+ mean, std = self._compute_statistics(hidden_states, attention)
+ # Append mean and std of the batch
+ pooled_stats = torch.cat((mean, std), dim=1)
+ pooled_stats = pooled_stats.unsqueeze(2)
+
+ return pooled_stats
+
+
+class SqueezeExcitationRes2NetBlock(nn.Module):
+ """An implementation of building block in ECAPA-TDNN, i.e.,
+ TDNN-Res2Net-TDNN-SqueezeExcitationBlock.
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ res2net_scale=8,
+ se_channels=128,
+ kernel_size=1,
+ dilation=1,
+ ):
+ super().__init__()
+ self.out_channels = out_channels
+ self.tdnn1 = TimeDelayNetBlock(
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ dilation=1,
+ )
+ self.res2net_block = Res2NetBlock(out_channels, out_channels, res2net_scale, kernel_size, dilation)
+ self.tdnn2 = TimeDelayNetBlock(
+ out_channels,
+ out_channels,
+ kernel_size=1,
+ dilation=1,
+ )
+ self.se_block = SqueezeExcitationBlock(out_channels, se_channels, out_channels)
+
+ def forward(self, hidden_state):
+ residual = hidden_state
+
+ hidden_state = self.tdnn1(hidden_state)
+ hidden_state = self.res2net_block(hidden_state)
+ hidden_state = self.tdnn2(hidden_state)
+ hidden_state = self.se_block(hidden_state)
+
+ return hidden_state + residual
+
+
+class ECAPA_TimeDelayNet(torch.nn.Module):
+ """An implementation of the speaker embedding model in a paper.
+ "ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in
+ TDNN Based Speaker Verification" (https://huggingface.co/papers/2005.07143).
+ """
+
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderBigVGANConfig):
+ super().__init__()
+ if len(config.enc_channels) != len(config.enc_kernel_sizes) or len(config.enc_channels) != len(
+ config.enc_dilations
+ ):
+ raise ValueError("enc_channels, enc_kernel_sizes and enc_dilations should have same length")
+ self.channels = config.enc_channels
+ self.blocks = nn.ModuleList()
+
+ # The initial TDNN layer
+ self.blocks.append(
+ TimeDelayNetBlock(
+ config.mel_dim,
+ config.enc_channels[0],
+ config.enc_kernel_sizes[0],
+ config.enc_dilations[0],
+ )
+ )
+
+ # SE-Res2Net layers
+ for i in range(1, len(config.enc_channels) - 1):
+ self.blocks.append(
+ SqueezeExcitationRes2NetBlock(
+ config.enc_channels[i - 1],
+ config.enc_channels[i],
+ res2net_scale=config.enc_res2net_scale,
+ se_channels=config.enc_se_channels,
+ kernel_size=config.enc_kernel_sizes[i],
+ dilation=config.enc_dilations[i],
+ )
+ )
+
+ # Multi-layer feature aggregation
+ self.mfa = TimeDelayNetBlock(
+ config.enc_channels[-1],
+ config.enc_channels[-1],
+ config.enc_kernel_sizes[-1],
+ config.enc_dilations[-1],
+ )
+
+ # Attentive Statistical Pooling
+ self.asp = AttentiveStatisticsPooling(
+ config.enc_channels[-1],
+ attention_channels=config.enc_attention_channels,
+ )
+
+ # Final linear transformation
+ self.fc = nn.Conv1d(
+ in_channels=config.enc_channels[-1] * 2,
+ out_channels=config.enc_dim,
+ kernel_size=1,
+ padding="same",
+ padding_mode="reflect",
+ )
+
+ def forward(self, hidden_states):
+ # Minimize transpose for efficiency
+ hidden_states = hidden_states.transpose(1, 2)
+
+ hidden_states_list = []
+ for layer in self.blocks:
+ hidden_states = layer(hidden_states)
+ hidden_states_list.append(hidden_states)
+
+ # Multi-layer feature aggregation
+ hidden_states = torch.cat(hidden_states_list[1:], dim=1)
+ hidden_states = self.mfa(hidden_states)
+
+ # Attentive Statistical Pooling
+ hidden_states = self.asp(hidden_states)
+
+ # Final linear transformation
+ hidden_states = self.fc(hidden_states)
+
+ hidden_states = hidden_states.squeeze(-1)
+ return hidden_states
+
+
+class DiTInputEmbedding(nn.Module):
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderBigVGANConfig):
+ super().__init__()
+ self.proj = nn.Linear(
+ config.mel_dim + config.enc_dim + config.enc_emb_dim + config.emb_dim,
+ config.hidden_size,
+ )
+ self.spk_encoder = ECAPA_TimeDelayNet(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ speaker_embedding: torch.Tensor,
+ condition_vector: torch.Tensor,
+ code_embed: torch.Tensor,
+ drop_audio_cond: Optional[bool] = False,
+ code_embed_uncond: Optional[bool] = None,
+ apply_cfg: Optional[bool] = True,
+ ):
+ if apply_cfg:
+ hidden_states = torch.cat([hidden_states, hidden_states], dim=0)
+ speaker_embedding = torch.cat([speaker_embedding, torch.zeros_like(speaker_embedding)], dim=0)
+ condition_vector = torch.cat([condition_vector, torch.zeros_like(condition_vector)], dim=0)
+ code_embed = torch.cat([code_embed, code_embed_uncond], dim=0)
+ elif drop_audio_cond: # cfg for cond audio
+ condition_vector = torch.zeros_like(condition_vector)
+ speaker_embedding = torch.zeros_like(speaker_embedding)
+ condition_vector = self.spk_encoder(condition_vector).unsqueeze(1).repeat(1, hidden_states.size(1), 1)
+ hidden_states = self.proj(torch.cat((hidden_states, condition_vector, code_embed, speaker_embedding), dim=-1))
+
+ return hidden_states
+
+
+# Transformer backbone using DiT blocks
+class DiTCodecEmbedding(nn.Module):
+ def __init__(self, codec_num_embeds, codec_dim, repeats):
+ super().__init__()
+ self.repeats = repeats
+ self.codec_embed = nn.Embedding(codec_num_embeds + 1, codec_dim)
+
+ def forward(self, code, drop_code=False):
+ if drop_code:
+ code = torch.zeros_like(code)
+ code_embed = self.codec_embed(code)
+
+ code_embed = torch.repeat_interleave(code_embed, repeats=self.repeats, dim=1)
+ return code_embed
+
+
+# AdaLayerNormZero
+# return with modulated x for attn input, and params for later mlp modulation
+class AdaLayerNormZero(nn.Module):
+ def __init__(self, dim):
+ super().__init__()
+
+ self.silu = nn.SiLU()
+ self.linear = nn.Linear(dim, dim * 6)
+
+ self.norm = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
+
+ def forward(self, hidden_states, emb=None):
+ emb = self.linear(self.silu(emb))
+ shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = torch.chunk(emb, 6, dim=1)
+
+ hidden_states = self.norm(hidden_states) * (1 + scale_msa[:, None]) + shift_msa[:, None]
+ return hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp
+
+
+# AdaLayerNormZero for final layer
+# return only with modulated x for attn input, cuz no more mlp modulation
+class AdaLayerNormZero_Final(nn.Module):
+ def __init__(self, dim):
+ super().__init__()
+
+ self.silu = nn.SiLU()
+ self.linear = nn.Linear(dim, dim * 2)
+
+ self.norm = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
+
+ def forward(self, hidden_states, emb):
+ emb = self.linear(self.silu(emb))
+ scale, shift = torch.chunk(emb, 2, dim=1)
+
+ hidden_states = self.norm(hidden_states) * (1 + scale)[:, None, :] + shift[:, None, :]
+ return hidden_states
+
+
+# FeedForward
+class DiTMLP(nn.Module):
+ def __init__(self, dim, mult=4, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+
+ self.ff = nn.ModuleList(
+ [
+ nn.Linear(dim, inner_dim),
+ nn.GELU(approximate="tanh"),
+ nn.Dropout(dropout),
+ nn.Linear(inner_dim, dim),
+ ]
+ )
+
+ def forward(self, hidden_states):
+ for layer in self.ff:
+ hidden_states = layer(hidden_states)
+ return hidden_states
+
+
+# Modified from Llama with a different rotate function, will fixed in next release
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+
+ def rotate_half_codec(x):
+ # x = rearrange(x, "... (d r) -> ... d r", r=2)
+ x = x.reshape(*x.shape[:-1], -1, 2)
+ x1, x2 = x.unbind(dim=-1)
+ x = torch.stack((-x2, x1), dim=-1)
+ return x.reshape(*x.shape[:-2], -1)
+
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half_codec(q) * sin)
+ k_embed = (k * cos) + (rotate_half_codec(k) * sin)
+ return q_embed, k_embed
+
+
+class DiTAttention(nn.Module):
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderBigVGANConfig):
+ super().__init__()
+
+ self.config = config
+ self.dim = config.hidden_size
+ self.heads = config.num_attention_heads
+ self.inner_dim = config.head_dim * config.num_attention_heads
+ self.dropout = config.dropout
+ self.is_causal = False
+
+ self.to_q = nn.Linear(config.hidden_size, self.inner_dim)
+ self.to_k = nn.Linear(config.hidden_size, self.inner_dim)
+ self.to_v = nn.Linear(config.hidden_size, self.inner_dim)
+
+ self.to_out = nn.ModuleList([nn.Linear(self.inner_dim, config.hidden_size), nn.Dropout(config.dropout)])
+
+ def forward(
+ self,
+ hidden_states, # noised input x
+ position_embeddings=None, # rotary position embedding for x
+ attention_mask=None,
+ ) -> torch.Tensor:
+ batch_size = hidden_states.shape[0]
+
+ # `sample` projections.
+ query = self.to_q(hidden_states)
+ key = self.to_k(hidden_states)
+ value = self.to_v(hidden_states)
+
+ # attention
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // self.heads
+ query = query.view(batch_size, -1, self.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, self.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, self.heads, head_dim).transpose(1, 2)
+
+ # apply rotary position embedding
+ # Due to training process, only first head is applied with RoPE, will be fixed at next release
+ cos, sin = position_embeddings
+ query, key = apply_rotary_pos_emb(query, key, cos, sin)
+
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+ attention_weights, _ = attention_interface(
+ self,
+ query,
+ key,
+ value,
+ attention_mask=attention_mask,
+ is_causal=False,
+ )
+
+ # mask. e.g. inference got a batch with different target durations, mask out the padding
+ attention_weights = attention_weights.reshape(batch_size, -1, self.heads * head_dim)
+ attention_weights = attention_weights.to(query.dtype)
+
+ # linear proj
+ attention_output = self.to_out[0](attention_weights)
+ attention_output = self.to_out[1](attention_output)
+
+ return attention_output
+
+
+# time step conditioning embedding
+class SinusPositionEmbedding(nn.Module):
+ def __init__(self, dim):
+ super().__init__()
+ self.dim = dim
+
+ def forward(self, hidden_states, scale=1000):
+ device = hidden_states.device
+ half_dim = self.dim // 2
+ emb = math.log(10000) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
+ emb = scale * hidden_states.unsqueeze(1) * emb.unsqueeze(0)
+ emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
+ return emb.type_as(hidden_states)
+
+
+class DiTTimestepEmbedding(nn.Module):
+ def __init__(self, dim, freq_embed_dim=256):
+ super().__init__()
+ self.time_embed = SinusPositionEmbedding(freq_embed_dim)
+ self.time_mlp = nn.ModuleList([nn.Linear(freq_embed_dim, dim), nn.SiLU(), nn.Linear(dim, dim)])
+
+ def forward(self, timestep):
+ time_hidden = self.time_embed(timestep)
+ time_hidden = time_hidden.to(timestep.dtype)
+ for layer in self.time_mlp:
+ time_hidden = layer(time_hidden) # b d
+ return time_hidden
+
+
+class DiTDecoderLayer(nn.Module):
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderBigVGANConfig, look_ahead_block=0, look_backward_block=0):
+ super().__init__()
+ self.attn_norm = AdaLayerNormZero(config.hidden_size)
+
+ self.attn = DiTAttention(config)
+ self.look_ahead_block = look_ahead_block
+ self.look_backward_block = look_backward_block
+ self.ff_norm = nn.LayerNorm(config.hidden_size, elementwise_affine=False, eps=1e-6)
+ self.ff = DiTMLP(dim=config.hidden_size, mult=config.ff_mult, dropout=config.dropout)
+
+ def forward(
+ self, hidden_states, timestep, position_embeddings=None, block_diff=None
+ ): # x: noised input, t: time embedding
+ # pre-norm & modulation for attention input
+ norm, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.attn_norm(hidden_states, emb=timestep)
+
+ # attention
+ attn_output = self.attn(
+ hidden_states=norm,
+ position_embeddings=position_embeddings,
+ attention_mask=(block_diff >= -float(self.look_backward_block))
+ & (block_diff <= float(self.look_ahead_block)),
+ )
+
+ # process attention output for input x
+ hidden_states = hidden_states + gate_msa.unsqueeze(1) * attn_output
+
+ norm = self.ff_norm(hidden_states) * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
+ ff_output = self.ff(norm)
+ hidden_states = hidden_states + gate_mlp.unsqueeze(1) * ff_output
+
+ return hidden_states
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://huggingface.co/papers/2006.08195
+ """
+
+ def __init__(self, in_features, alpha=1.0):
+ super().__init__()
+ self.in_features = in_features
+
+ # initialize alpha
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, hidden_states):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ hidden_states = hidden_states + (1.0 / (beta + self.no_div_by_zero)) * torch.pow(
+ torch.sin(hidden_states * alpha), 2
+ )
+
+ return hidden_states
+
+
+def kaiser_sinc_filter1d(cutoff, half_width, kernel_size):
+ """Generates a 1D Kaiser-windowed sinc filter.
+
+ Args:
+ cutoff (float): Normalized cutoff frequency (0 to 0.5).
+ half_width (float): Transition bandwidth.
+ kernel_size (int): Number of filter taps.
+
+ Returns:
+ torch.Tensor: A tensor of shape (1, 1, kernel_size) representing the filter.
+ """
+ is_even = kernel_size % 2 == 0
+ half_size = kernel_size // 2
+
+ # Compute Kaiser window parameters
+ delta_f = 4 * half_width
+ attenuation = 2.285 * (half_size - 1) * math.pi * delta_f + 7.95
+
+ if attenuation > 50.0:
+ beta = 0.1102 * (attenuation - 8.7)
+ elif attenuation >= 21.0:
+ beta = 0.5842 * (attenuation - 21) ** 0.4 + 0.07886 * (attenuation - 21.0)
+ else:
+ beta = 0.0
+
+ kaiser_window = torch.kaiser_window(kernel_size, beta=beta, periodic=False, dtype=torch.float32)
+
+ # Compute time indices
+ if is_even:
+ time_indices = torch.arange(-half_size, half_size) + 0.5
+ else:
+ time_indices = torch.arange(kernel_size) - half_size
+
+ # Compute sinc filter
+ if cutoff == 0:
+ return torch.zeros((1, 1, kernel_size), dtype=torch.float32) # Ensures correct shape
+
+ sinc_filter = torch.sinc(2 * cutoff * time_indices)
+ normalized_filter = 2 * cutoff * kaiser_window * sinc_filter
+
+ # Normalize to ensure sum = 1 (avoid leakage of constant component)
+ normalized_filter /= normalized_filter.sum()
+
+ return normalized_filter.view(1, 1, kernel_size)
+
+
+class UpSample1d(nn.Module):
+ def __init__(self, ratio=2, kernel_size=None):
+ super().__init__()
+ self.ratio = ratio
+ self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
+ self.stride = ratio
+ self.pad = self.kernel_size // ratio - 1
+ self.pad_left = self.pad * self.stride + (self.kernel_size - self.stride) // 2
+ self.pad_right = self.pad * self.stride + (self.kernel_size - self.stride + 1) // 2
+
+ filter = kaiser_sinc_filter1d(cutoff=0.5 / ratio, half_width=0.6 / ratio, kernel_size=self.kernel_size)
+ self.register_buffer("filter", filter, persistent=False)
+
+ def forward(self, hidden_states):
+ channels = hidden_states.shape[1]
+
+ hidden_states = F.pad(hidden_states, (self.pad, self.pad), mode="replicate")
+ hidden_states = self.ratio * F.conv_transpose1d(
+ hidden_states, self.filter.expand(channels, -1, -1), stride=self.stride, groups=channels
+ )
+ hidden_states = hidden_states[..., self.pad_left : -self.pad_right]
+
+ return hidden_states
+
+
+class DownSample1d(nn.Module):
+ def __init__(self, ratio=2, kernel_size=None):
+ super().__init__()
+ cutoff = 0.5 / ratio
+ half_width = 0.6 / ratio
+
+ if cutoff < 0.0:
+ raise ValueError("Minimum cutoff must be larger than zero.")
+ if cutoff > 0.5:
+ raise ValueError("A cutoff above 0.5 does not make sense.")
+
+ self.even = kernel_size % 2 == 0
+ self.pad_left = kernel_size // 2 - int(self.even)
+ self.pad_right = kernel_size // 2
+ self.stride = ratio
+ filter = kaiser_sinc_filter1d(cutoff, half_width, kernel_size)
+ self.register_buffer("filter", filter, persistent=False)
+
+ def forward(self, hidden_states):
+ channels = hidden_states.shape[1]
+ hidden_states = F.pad(hidden_states, (self.pad_left, self.pad_right), mode="replicate")
+ out = F.conv1d(hidden_states, self.filter.expand(channels, -1, -1), stride=self.stride, groups=channels)
+ return out
+
+
+class TorchActivation1d(nn.Module):
+ def __init__(
+ self,
+ activation,
+ up_ratio: int = 2,
+ down_ratio: int = 2,
+ up_kernel_size: int = 12,
+ down_kernel_size: int = 12,
+ ):
+ super().__init__()
+ if not callable(activation):
+ raise TypeError("Activation function must be callable")
+ self.act = activation
+ self.upsample = UpSample1d(up_ratio, up_kernel_size)
+ self.downsample = DownSample1d(down_ratio, down_kernel_size)
+
+ def forward(self, hidden_states):
+ hidden_states = self.upsample(hidden_states)
+ hidden_states = self.act(hidden_states)
+ hidden_states = self.downsample(hidden_states)
+
+ return hidden_states
+
+
+class CausalConv1d(nn.Conv1d):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.causal_padding = self.dilation[0] * (self.kernel_size[0] - 1)
+
+ def forward(self, x):
+ return self._conv_forward(F.pad(x, [self.causal_padding, 0]), self.weight, self.bias)
+
+
+class AMPBlock(torch.nn.Module):
+ def __init__(
+ self,
+ channels,
+ kernel_size=3,
+ dilation=(1, 3, 5),
+ causal_type='1',
+ ):
+ super().__init__()
+
+ self.convs1 = nn.ModuleList(
+ [
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[0],
+ ),
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[1],
+ ),
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[2],
+ ),
+ ]
+ )
+
+ if causal_type == '1':
+ self.convs2 = nn.ModuleList(
+ [
+ nn.Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=self._get_padding(kernel_size, 1),
+ ),
+ nn.Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=self._get_padding(kernel_size, 1),
+ ),
+ nn.Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=self._get_padding(kernel_size, 1),
+ ),
+ ]
+ )
+ else:
+ self.convs2 = nn.ModuleList(
+ [
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ ),
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ ),
+ CausalConv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ ),
+ ]
+ )
+
+ self.num_layers = len(self.convs1) + len(self.convs2) # total number of conv layers
+
+ self.activations = nn.ModuleList(
+ [TorchActivation1d(activation=SnakeBeta(channels)) for _ in range(self.num_layers)]
+ )
+
+ if causal_type == '2':
+ self.pre_conv = nn.Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ padding=self._get_padding(kernel_size, 1),
+ )
+ self.pre_act = TorchActivation1d(activation=SnakeBeta(channels))
+ else:
+ self.pre_conv = nn.Identity()
+ self.pre_act = nn.Identity()
+
+ def _get_padding(self, kernel_size, dilation=1):
+ return int((kernel_size * dilation - dilation) / 2)
+
+ def forward(self, x):
+ hidden_states = self.pre_conv(x)
+ hidden_states = self.pre_act(hidden_states)
+ acts1, acts2 = self.activations[::2], self.activations[1::2]
+ for conv1, conv2, act1, act2 in zip(self.convs1, self.convs2, acts1, acts2):
+ hidden_states = act1(hidden_states)
+ hidden_states = conv1(hidden_states)
+ hidden_states = act2(hidden_states)
+ hidden_states = conv2(hidden_states)
+ x = x + hidden_states
+ return x
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1DecoderBigVGANModel(Qwen3TTSTokenizerV1DecoderPreTrainedModel):
+ config: Qwen3TTSTokenizerV1DecoderBigVGANConfig
+
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderBigVGANConfig):
+ super().__init__(config)
+ self.num_residual_blocks = len(config.resblock_kernel_sizes)
+ self.num_upsample_layers = len(config.upsample_rates)
+
+ self.conv_pre = nn.Conv1d(config.mel_dim, config.upsample_initial_channel, 5, 1, padding=2)
+
+ # Removing extra ModuleList breaks official state dict
+ ups = [
+ nn.ModuleList(
+ [
+ nn.ConvTranspose1d(
+ config.upsample_initial_channel // (2**layer_idx),
+ config.upsample_initial_channel // (2 ** (layer_idx + 1)),
+ kernel_size,
+ stride,
+ padding=(kernel_size - stride) // 2,
+ )
+ ]
+ )
+ for layer_idx, (stride, kernel_size) in enumerate(zip(config.upsample_rates, config.upsample_kernel_sizes))
+ ]
+ self.ups = nn.ModuleList(ups)
+
+ self.resblocks = nn.ModuleList(
+ [
+ AMPBlock(config.upsample_initial_channel // (2 ** (layer_idx + 1)), kernel_size, dilation, '1' if layer_idx > 1 else '2')
+ for layer_idx in range(self.num_upsample_layers)
+ for kernel_size, dilation in zip(config.resblock_kernel_sizes, config.resblock_dilation_sizes)
+ ]
+ )
+
+ self.activation_post = TorchActivation1d(
+ activation=SnakeBeta(config.upsample_initial_channel // (2**self.num_upsample_layers))
+ )
+ self.conv_post = nn.Conv1d(
+ config.upsample_initial_channel // (2**self.num_upsample_layers), 1, 7, 1, padding=3, bias=False
+ )
+
+ def normalize_spectrogram(self, spectrogram, max_value, min_db):
+ return torch.clamp((2 * max_value) * ((spectrogram - min_db) / (-min_db)) - max_value, -max_value, max_value)
+
+ def amplitude_to_db(self, amplitude, min_db_level):
+ min_level = torch.exp(
+ torch.tensor(min_db_level / 20.0 * np.log(10), device=amplitude.device, dtype=amplitude.dtype)
+ )
+ return 20 * torch.log10(torch.clamp(amplitude, min=min_level))
+
+ def process_mel_spectrogram(self, mel_spectrogram):
+ amplitude_spectrum = torch.exp(mel_spectrogram)
+ decibel_spectrum = self.amplitude_to_db(amplitude_spectrum, -115) - 20
+ return self.normalize_spectrogram(decibel_spectrum, 1, -115)
+
+ def forward(self, mel_spectrogram):
+ processed_spectrogram = self.process_mel_spectrogram(mel_spectrogram)
+ hidden_representation = self.conv_pre(processed_spectrogram)
+
+ for layer_index in range(self.num_upsample_layers):
+ hidden_representation = self.ups[layer_index][0](hidden_representation)
+ residual_output = sum(
+ self.resblocks[layer_index * self.num_residual_blocks + block_index](hidden_representation)
+ for block_index in range(self.num_residual_blocks)
+ )
+ residual_output = residual_output / self.num_residual_blocks
+ hidden_representation = residual_output
+
+ hidden_representation = self.activation_post(hidden_representation)
+ output_waveform = self.conv_post(hidden_representation)
+ return torch.clamp(output_waveform, min=-1.0, max=1.0).squeeze(1)
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1DecoderDiTModel(Qwen3TTSTokenizerV1DecoderPreTrainedModel):
+ config: Qwen3TTSTokenizerV1DecoderDiTConfig
+ _no_split_modules = ["DiTDecoderLayer"]
+
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderDiTConfig):
+ super().__init__(config)
+ self.mel_dim = config.mel_dim
+ self.repeats = config.repeats
+ self.time_embed = DiTTimestepEmbedding(config.hidden_size)
+
+ self.text_embed = DiTCodecEmbedding(config.num_embeds, config.emb_dim, config.repeats)
+ self.input_embed = DiTInputEmbedding(config)
+
+ self.rotary_embed = Qwen3TTSTokenizerV1DecoderDiTRotaryEmbedding(config.head_dim)
+
+ self.hidden_size = config.hidden_size
+ self.layers = config.num_hidden_layers
+ self.block_size = config.block_size
+ self.num_attention_heads = config.num_attention_heads
+
+ self.transformer_blocks = nn.ModuleList()
+ for i in range(config.num_hidden_layers):
+ self.transformer_blocks.append(
+ DiTDecoderLayer(
+ config,
+ look_ahead_block=1 if i in config.look_ahead_layers else 0,
+ look_backward_block=1 if i in config.look_backward_layers else 0,
+ )
+ )
+
+ self.norm_out = AdaLayerNormZero_Final(config.hidden_size) # final modulation
+ self.proj_out = nn.Linear(config.hidden_size, config.mel_dim)
+
+ def _create_block_diff(self, hidden_states):
+ batch, seq_len = hidden_states.shape[0], hidden_states.shape[1]
+ block_indices = torch.arange(seq_len, device=hidden_states.device) // self.block_size # [seq_length]
+
+ block_i = block_indices.unsqueeze(1) # [seq_length, 1]
+ block_j = block_indices.unsqueeze(0) # [1, seq_length]
+ block_diff = block_j - block_i # (n, n)
+
+ return block_diff.expand(batch, self.num_attention_heads, seq_len, seq_len)
+
+ def forward(
+ self,
+ hidden_states,
+ condition_vector,
+ speaker_embedding,
+ quantized_code,
+ time_step,
+ drop_audio_conditioning=False,
+ drop_code=False,
+ apply_cfg=True,
+ ):
+ batch_size = hidden_states.shape[0] * 2
+ if time_step.ndim == 0:
+ time_step = time_step.repeat(batch_size)
+
+ # Compute embeddings
+ time_embedding = self.time_embed(time_step)
+ text_embedding = self.text_embed(quantized_code, drop_code=False if apply_cfg else drop_code)
+ text_embedding_unconditioned = self.text_embed(quantized_code, drop_code=True) if apply_cfg else None
+
+ hidden_states = self.input_embed(
+ hidden_states,
+ speaker_embedding,
+ condition_vector,
+ text_embedding,
+ drop_audio_cond=drop_audio_conditioning,
+ code_embed_uncond=text_embedding_unconditioned,
+ apply_cfg=apply_cfg,
+ )
+
+ # Compute positional encodings
+ position_embeddings = self.rotary_embed(hidden_states)
+ blockwise_difference = self._create_block_diff(hidden_states)
+
+ # Transformer blocks
+ for transformer_block in self.transformer_blocks:
+ hidden_states = transformer_block(
+ hidden_states,
+ time_embedding,
+ position_embeddings=position_embeddings,
+ block_diff=blockwise_difference,
+ )
+
+ hidden_states = self.norm_out(hidden_states, time_embedding)
+ output = self.proj_out(hidden_states)
+
+ return output
+
+ def optimized_scale(self, positive_flat, negative_flat):
+ # Calculate dot production
+ dot_product = torch.sum(positive_flat * negative_flat, dim=1, keepdim=True)
+ # Squared norm of uncondition
+ squared_norm = torch.sum(negative_flat ** 2, dim=1, keepdim=True) + 1e-8
+ # st_star = v_cond^T * v_uncond / ||v_uncond||^2
+ st_star = dot_product / squared_norm
+ return st_star
+
+ @torch.no_grad()
+ def sample(
+ self,
+ conditioning_vector,
+ reference_mel_spectrogram,
+ quantized_code,
+ num_steps=10,
+ guidance_scale=0.5,
+ sway_coefficient=-1.0,
+ ):
+ noise_initialization = torch.randn([quantized_code.shape[0], 30000, self.mel_dim], dtype=reference_mel_spectrogram.dtype)
+ maximum_duration = quantized_code.shape[1] * self.repeats
+ initial_state = noise_initialization[:, :maximum_duration].to(quantized_code.device)
+ conditioning_vector = conditioning_vector.unsqueeze(1).repeat(1, maximum_duration, 1)
+
+ def ode_function(time_step, hidden_states):
+ if guidance_scale < 1e-5:
+ prediction = self(
+ hidden_states=hidden_states,
+ speaker_embedding=conditioning_vector,
+ condition_vector=reference_mel_spectrogram,
+ quantized_code=quantized_code,
+ time_step=time_step,
+ drop_audio_conditioning=False,
+ drop_code=False,
+ )
+ return prediction
+
+ model_output = self(
+ hidden_states=hidden_states,
+ quantized_code=quantized_code,
+ speaker_embedding=conditioning_vector,
+ condition_vector=reference_mel_spectrogram,
+ time_step=time_step,
+ apply_cfg=True,
+ )
+ guided_prediction, null_prediction = torch.chunk(model_output, 2, dim=0)
+
+ return guided_prediction + (guided_prediction - null_prediction) * guidance_scale
+
+ initial_time = 0
+ time_embedding = torch.linspace(
+ initial_time, 1, num_steps, device=quantized_code.device, dtype=conditioning_vector.dtype
+ )
+
+ if sway_coefficient is not None:
+ time_embedding += sway_coefficient * (torch.cos(torch.pi / 2 * time_embedding) - 1 + time_embedding)
+
+ values = initial_state.clone()
+ for t0, t1 in zip(time_embedding[:-1], time_embedding[1:]):
+ dt = t1 - t0
+ vt = ode_function(t0, values)
+ values = values + vt * dt
+
+ generated_mel_spectrogram = values.permute(0, 2, 1)
+ return generated_mel_spectrogram
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1Decoder(Qwen3TTSTokenizerV1DecoderPreTrainedModel):
+ config: Qwen3TTSTokenizerV1DecoderConfig
+ base_model_prefix = "model"
+ _no_split_modules = ["Qwen3TTSTokenizerV1DecoderDiTModel", "Qwen3TTSTokenizerV1DecoderBigVGANModel"]
+
+ def __init__(self, config: Qwen3TTSTokenizerV1DecoderConfig):
+ super().__init__(config)
+ attn_impl = config._attn_implementation
+ if config._attn_implementation == "flash_attention_2":
+ logger.warning_once(
+ "Qwen3TTSTokenizerV1Decoder must inference with fp32, but flash_attention_2 only supports fp16 and bf16, "
+ "attention implementation of Qwen3TTSTokenizerV1Decoder will fallback to sdpa."
+ )
+ attn_impl = "sdpa"
+ elif config._attn_implementation == "eager":
+ logger.warning_once(
+ "Qwen3TTSTokenizerV1Decoder does not support eager attention implementation, fall back to sdpa"
+ )
+ attn_impl = "sdpa"
+ self.dit = Qwen3TTSTokenizerV1DecoderDiTModel._from_config(
+ config.dit_config, attn_implementation=attn_impl
+ )
+ self.bigvgan = Qwen3TTSTokenizerV1DecoderBigVGANModel._from_config(
+ config.bigvgan_config, attn_implementation=attn_impl
+ )
+
+ def forward(
+ self,
+ code,
+ conditioning,
+ reference_mel,
+ num_steps=10,
+ guidance_scale=0.5,
+ sway_coefficient=-1.0,
+ **kwargs,
+ ):
+ """Generates a waveform from input code and conditioning parameters."""
+
+ mel_spectrogram = self.dit.sample(
+ conditioning,
+ reference_mel,
+ code,
+ num_steps=num_steps,
+ guidance_scale=guidance_scale,
+ sway_coefficient=sway_coefficient,
+ )
+
+ waveform = self.bigvgan(mel_spectrogram)
+
+ return waveform
+
+
+class Qwen3TTSTokenizerV1Encoder(Qwen3TTSTokenizerV1EncoderPreTrainedModel):
+ config: Qwen3TTSTokenizerV1EncoderConfig
+ def __init__(self, config: Qwen3TTSTokenizerV1EncoderConfig):
+ super().__init__(config)
+
+ self.tokenizer = WhisperEncoderVQ(
+ n_mels=config.n_mels,
+ n_ctx=config.n_ctx,
+ n_state=config.n_state,
+ n_head=config.n_head,
+ n_layer=config.n_layer,
+ n_window=config.n_window,
+ output_dim=config.output_dim,
+ grad_checkpointing=config.grad_checkpointing,
+ enable_mp=config.enable_mp,
+ audio_sequence_parallel=config.audio_sequence_parallel,
+ audio_vq_type=config.audio_vq_type,
+ audio_vq_layers=config.audio_vq_layers,
+ audio_vq_codebook_size=config.audio_vq_codebook_size,
+ audio_vq_codebook_dim=config.audio_vq_codebook_dim,
+ audio_vq_pe=config.audio_vq_pe,
+ audio_vq_ds_rate=config.audio_vq_ds_rate,
+ )
+
+ self.padding = True
+ self.audio_vq_ds_rate = self.tokenizer.audio_vq_ds_rate
+
+ def speech2mel(self, speechs):
+ mels = [
+ get_mel_audio(
+ speech, padding = self.padding, audio_vq_ds_rate = self.audio_vq_ds_rate
+ ).to(speech.dtype).to(self.tokenizer.conv1.weight.device)
+ for speech in speechs
+ ]
+ return mels
+
+ def mel2code(self, mels):
+ audio_mellens = [mel.size(-1) for mel in mels]
+ audio_aftercnnlens = [get_T_after_cnn(T) for T in audio_mellens]
+ audio_seqlens = [T + 2 for T in audio_aftercnnlens]
+
+ with torch.no_grad():
+ _, indices = self.tokenizer(
+ x_list = mels,
+ audio_mellens = audio_mellens,
+ audio_aftercnnlens = audio_aftercnnlens,
+ audio_seqlens = audio_seqlens,
+ return_indices=True,
+ )
+
+ indice_lens = [T // self.tokenizer.audio_vq_ds_rate for T in audio_aftercnnlens]
+ indices = pad_sequence(torch.split(indices, indice_lens), batch_first=True, padding_value=0)
+
+ return indices, indice_lens
+
+ def quantize_speech(self, speechs):
+ mels = self.speech2mel(speechs)
+ indices, indice_lens = self.mel2code(mels)
+ return indices, indice_lens
+
+
+@auto_docstring
+class Qwen3TTSTokenizerV1PreTrainedModel(PreTrainedModel):
+ config: Qwen3TTSTokenizerV1Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn = True
+ _supports_sdpa = True
+ _can_compile_fullgraph = False
+ _supports_attention_backend = True
+
+
+@auto_docstring(
+ custom_intro="""
+ The Qwen3TTSTokenizerV1 model.
+ """
+)
+class Qwen3TTSTokenizerV1Model(Qwen3TTSTokenizerV1PreTrainedModel):
+ def __init__(self, config: Qwen3TTSTokenizerV1Config):
+ super().__init__(config)
+ self.config = config
+
+ self.input_sample_rate = config.input_sample_rate
+ self.output_sample_rate = config.output_sample_rate
+
+ self.decode_upsample_rate = config.decode_upsample_rate
+ self.encode_downsample_rate = config.encode_downsample_rate
+
+ self.encoder = Qwen3TTSTokenizerV1Encoder._from_config(self.config.encoder_config)
+ self.decoder = Qwen3TTSTokenizerV1Decoder._from_config(self.config.decoder_config)
+
+ self.encoder_xvector_extractor = None
+
+ self.post_init()
+
+ def load_encoder_xvector_extractor(self, model_path):
+ self.encoder_xvector_extractor = XVectorExtractor(model_path)
+
+ def get_model_type(self):
+ return self.config.model_type
+
+ def get_input_sample_rate(self):
+ return self.input_sample_rate
+
+ def get_output_sample_rate(self):
+ return self.output_sample_rate
+
+ def get_encode_downsample_rate(self):
+ return self.encode_downsample_rate
+
+ def get_decode_upsample_rate(self):
+ return self.decode_upsample_rate
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *model_args,
+ config=None,
+ cache_dir=None,
+ ignore_mismatched_sizes=False,
+ force_download=False,
+ local_files_only=False,
+ token=None,
+ revision="main",
+ use_safetensors=None,
+ weights_only=True,
+ **kwargs,
+ ):
+ model = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *model_args,
+ config=config,
+ cache_dir=cache_dir,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ force_download=force_download,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ use_safetensors=use_safetensors,
+ weights_only=weights_only,
+ **kwargs,
+ )
+ encoder_xvector_extractor_path = cached_file(
+ pretrained_model_name_or_path,
+ "campplus.onnx",
+ subfolder=kwargs.pop("subfolder", None),
+ cache_dir=kwargs.pop("cache_dir", None),
+ force_download=kwargs.pop("force_download", False),
+ proxies=kwargs.pop("proxies", None),
+ resume_download=kwargs.pop("resume_download", None),
+ local_files_only=kwargs.pop("local_files_only", False),
+ token=kwargs.pop("use_auth_token", None),
+ revision=kwargs.pop("revision", None),
+ )
+ if encoder_xvector_extractor_path is None:
+ raise ValueError(f"""{pretrained_model_name_or_path}/{encoder_xvector_extractor_path} not exists""")
+ model.load_encoder_xvector_extractor(encoder_xvector_extractor_path)
+
+ return model
+
+ def encode(
+ self,
+ input_values: torch.Tensor,
+ padding_mask: Optional[torch.Tensor] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor, Optional[torch.Tensor]], Qwen3TTSTokenizerV1EncoderOutput]:
+ """
+ Encodes the input audio waveform into discrete codes.
+
+ Args:
+ input_values (`torch.Tensor` of shape `(batch_size, sequence_length)`):
+ Float values of the input audio waveform.
+ padding_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`):
+ Indicates which inputs are to be ignored due to padding, where elements are either 1 for *not masked* or 0
+ for *masked*.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.return_dict
+
+ wavs = [value[:mask.sum()] for value, mask in zip(input_values, padding_mask)]
+
+ codes, codes_lens = self.encoder.quantize_speech(wavs)
+ codes = [c[:l] for c, l in zip(codes, codes_lens)]
+
+ xvectors = []
+ ref_mels = []
+ for wav in wavs:
+ xvector, ref_mel = self.encoder_xvector_extractor.extract_code(wav.cpu().numpy())
+ xvector = torch.tensor(xvector).to(wav.dtype).to(wav.device)
+ ref_mel = torch.tensor(ref_mel).to(wav.dtype).to(wav.device)
+ xvectors.append(xvector)
+ ref_mels.append(ref_mel)
+
+ if not return_dict:
+ return (
+ codes,
+ xvectors,
+ ref_mels
+ )
+
+ return Qwen3TTSTokenizerV1EncoderOutput(codes, xvectors, ref_mels)
+
+ def decode(
+ self,
+ audio_codes: torch.Tensor,
+ xvectors: torch.Tensor,
+ ref_mels: torch.Tensor,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor, torch.Tensor], Qwen3TTSTokenizerV1DecoderOutput]:
+ """
+ Decodes the given frames into an output audio waveform.
+
+ Note that the output might be a bit bigger than the input. In that case, any extra steps at the end can be
+ trimmed.
+
+ Args:
+ audio_codes (`torch.LongTensor` of shape `(batch_size, codes_length)`, *optional*):
+ Discret code embeddings computed using `model.encode`.
+ xvectors (`torch.FloatTensor` of shape `(batch_size, xvector_dim)`, *optional*):
+ X-vector embeddings computed using `model.encode`.
+ ref_mels (`torch.FloatTensor` of shape `(batch_size, mel_length, mel_dim)`, *optional*):
+ Reference mel spectrogram computed using `model.encode`.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+ """
+ return_dict = return_dict if return_dict is not None else self.config.return_dict
+
+ audio_values = self.decoder(code=audio_codes,
+ reference_mel=ref_mels,
+ conditioning=xvectors)
+
+ audio_lengths = (audio_codes > 0).sum(1) * self.decode_upsample_rate
+ audio_values = [a[:l] for a, l in zip(audio_values, audio_lengths)]
+
+ if not return_dict:
+ return (
+ audio_values,
+ )
+
+ return Qwen3TTSTokenizerV1DecoderOutput(audio_values)
+
+
+__all__ = ["Qwen3TTSTokenizerV1Model", "Qwen3TTSTokenizerV1PreTrainedModel"]
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/assets/mel_filters.npz b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/assets/mel_filters.npz
new file mode 100644
index 0000000..28ea269
Binary files /dev/null and b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/assets/mel_filters.npz differ
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/core_vq.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/core_vq.py
new file mode 100644
index 0000000..6a793c2
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/core_vq.py
@@ -0,0 +1,523 @@
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+# This implementation is inspired from
+# https://github.com/lucidrains/vector-quantize-pytorch
+# which is released under MIT License. Hereafter, the original license:
+# MIT License
+#
+# Copyright (c) 2020 Phil Wang
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+"""Core vector quantization implementation."""
+import random
+import typing as tp
+from random import randrange
+
+import numpy as np
+from einops import rearrange, repeat
+from math import ceil
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+
+def round_up_multiple(num, mult):
+ return ceil(num / mult) * mult
+
+def default(val: tp.Any, d: tp.Any) -> tp.Any:
+ return val if val is not None else d
+
+
+def ema_inplace(moving_avg, new, decay: float):
+ moving_avg.data.mul_(decay).add_(new, alpha=(1 - decay))
+
+
+def laplace_smoothing(x, n_categories: int, epsilon: float = 1e-5):
+ return (x + epsilon) / (x.sum() + n_categories * epsilon)
+
+
+def uniform_init(*shape: int):
+ t = torch.empty(shape)
+ nn.init.kaiming_uniform_(t)
+ return t
+
+
+def sample_vectors(samples, num: int):
+ num_samples, device = samples.shape[0], samples.device
+
+ if num_samples >= num:
+ indices = torch.randperm(num_samples, device=device)[:num]
+ else:
+ indices = torch.randint(0, num_samples, (num,), device=device)
+
+ return samples[indices]
+
+
+@torch.no_grad()
+def kmeans(samples, num_clusters: int, num_iters: int = 10):
+ dim, dtype = samples.shape[-1], samples.dtype
+
+ means = sample_vectors(samples, num_clusters)
+
+ for _ in range(num_iters):
+ dists = -(
+ samples.pow(2).sum(1, keepdim=True)
+ - 2 * torch.matmul(samples, means.t())
+ + means.t().pow(2).sum(0, keepdim=True)
+ )
+
+ buckets = dists.max(dim=-1).indices
+ del dists
+ bins = torch.bincount(buckets, minlength=num_clusters)
+ zero_mask = bins == 0
+ bins_min_clamped = bins.masked_fill(zero_mask, 1)
+
+ new_means = buckets.new_zeros(num_clusters, dim, dtype=dtype)
+ new_means.scatter_add_(0, repeat(buckets, "n -> n d", d=dim), samples)
+ new_means = new_means / bins_min_clamped[..., None]
+
+ means = torch.where(zero_mask[..., None], means, new_means)
+ return means, bins
+
+
+def preprocess(x):
+ x = rearrange(x, "... d -> (...) d")
+ return x
+
+
+def postprocess_emb(embed_ind, shape):
+ return embed_ind.view(*shape[:-1])
+
+
+class EuclideanCodebook(nn.Module):
+ """Codebook with Euclidean distance.
+ Args:
+ dim (int): Dimension.
+ codebook_size (int): Codebook size.
+ kmeans_init (bool): Whether to use k-means to initialize the codebooks.
+ If set to true, run the k-means algorithm on the first training batch and use
+ the learned centroids as initialization.
+ kmeans_iters (int): Number of iterations used for k-means algorithm at initialization.
+ decay (float): Decay for exponential moving average over the codebooks.
+ epsilon (float): Epsilon value for numerical stability.
+ threshold_ema_dead_code (int): Threshold for dead code expiration. Replace any codes
+ that have an exponential moving average cluster size less than the specified threshold with
+ randomly selected vector from the current batch.
+ """
+
+ def __init__(
+ self,
+ dim: int,
+ codebook_size: int,
+ kmeans_init: int = False,
+ kmeans_iters: int = 10,
+ decay: float = 0.99,
+ epsilon: float = 1e-5,
+ threshold_ema_dead_code: float = 2.0,
+ ):
+ super().__init__()
+ self.decay = decay
+ self.codebook_size = codebook_size
+ self.kmeans_iters = kmeans_iters
+ self.epsilon = epsilon
+ self.threshold_ema_dead_code = threshold_ema_dead_code
+
+ self.inited = None
+ self.cluster_size = None
+ self.embed = None
+ self.embed_avg = None
+ self.training = True
+
+ def init_embed_(self, data):
+ if self.inited:
+ return
+
+ embed, cluster_size = kmeans(data, self.codebook_size, self.kmeans_iters)
+ self.embed.data.copy_(embed)
+ self.embed_avg.data.copy_(embed.clone())
+ self.cluster_size.data.copy_(cluster_size)
+ self.inited.data.copy_(torch.Tensor([True]))
+ # Make sure all buffers across workers are in sync after initialization
+ # distrib.broadcast_tensors([self.embed, self.embed_avg, self.cluster_size, self.inited])
+
+ def replace_(self, samples, mask):
+ modified_codebook = torch.where(
+ mask[..., None], sample_vectors(samples, self.codebook_size), self.embed
+ )
+ self.embed.data.copy_(modified_codebook)
+
+ def expire_codes_(self, batch_samples):
+ if self.threshold_ema_dead_code == 0:
+ return
+
+ cluster_size = self.cluster_size / sum(self.cluster_size) * self.codebook_size
+ expired_codes = cluster_size < self.threshold_ema_dead_code
+ if not torch.any(expired_codes):
+ return
+ else:
+ print(f"VQ expire infos: num_expire={sum(expired_codes)}, cluster_size[:5]={cluster_size[:5]}")
+
+ batch_samples = rearrange(batch_samples, "... d -> (...) d")
+ self.replace_(batch_samples, mask=expired_codes)
+ # sync buffers outside for efficiency
+ # distrib.broadcast_tensors(self.buffers())
+
+ def quantize(self, x):
+ embed = self.embed.t()
+ dist = -(
+ x.pow(2).sum(1, keepdim=True)
+ - 2 * x @ embed
+ + embed.pow(2).sum(0, keepdim=True)
+ )
+ embed_ind = dist.max(dim=-1).indices
+ return embed_ind
+
+ def dequantize(self, embed_ind):
+ quantize = F.embedding(embed_ind, self.embed)
+ return quantize
+
+ def encode(self, x, buffers):
+ self.inited, self.cluster_size, self.embed, self.embed_avg = buffers
+
+ shape = x.shape
+ # pre-process
+ x = preprocess(x)
+ # quantize
+ embed_ind = self.quantize(x)
+ # post-process
+ embed_ind = postprocess_emb(embed_ind, shape)
+ return embed_ind
+
+ def decode(self, embed_ind, buffers):
+ self.inited, self.cluster_size, self.embed, self.embed_avg = buffers
+
+ quantize = self.dequantize(embed_ind)
+ return quantize
+
+ def forward(self, x, buffers):
+ self.inited, self.cluster_size, self.embed, self.embed_avg = buffers
+
+ shape, dtype = x.shape, x.dtype
+ x = preprocess(x)
+
+ self.init_embed_(x)
+ if self.training:
+ # We do the expiry of code at that point as buffers are in sync
+ # and all the workers will take the same decision.
+ self.expire_codes_(x)
+
+ embed_ind = self.quantize(x)
+ embed_onehot = F.one_hot(embed_ind, self.codebook_size).type(dtype)
+ embed_ind = postprocess_emb(embed_ind, shape)
+ quantize = self.dequantize(embed_ind)
+
+ if self.training:
+ ema_inplace(self.cluster_size, embed_onehot.sum(0), self.decay)
+ embed_sum = x.t() @ embed_onehot
+ ema_inplace(self.embed_avg, embed_sum.t(), self.decay)
+ cluster_size = (
+ laplace_smoothing(self.cluster_size, self.codebook_size, self.epsilon)
+ * self.cluster_size.sum()
+ )
+ embed_normalized = self.embed_avg / cluster_size.unsqueeze(1)
+ self.embed.data.copy_(embed_normalized)
+ # Note: after ema update, there is a very small difference between codebooks on GPUs.
+ # The impact can be very small, ignore it.
+
+ return quantize, embed_ind
+
+
+class VectorQuantization(nn.Module):
+ """Vector quantization implementation.
+ Currently, supports only euclidean distance.
+ Args:
+ dim (int): Dimension
+ codebook_size (int): Codebook size
+ codebook_dim (int): Codebook dimension. If not defined, uses the specified dimension in dim.
+ decay (float): Decay for exponential moving average over the codebooks.
+ epsilon (float): Epsilon value for numerical stability.
+ kmeans_init (bool): Whether to use kmeans to initialize the codebooks.
+ kmeans_iters (int): Number of iterations used for kmeans initialization.
+ threshold_ema_dead_code (int): Threshold for dead code expiration. Replace any codes
+ that have an exponential moving average cluster size less than the specified threshold with
+ randomly selected vector from the current batch.
+ commitment_weight (float): Weight for commitment loss.
+ """
+ def __init__(
+ self,
+ dim: int,
+ codebook_size: int,
+ codebook_dim: tp.Optional[int] = None,
+ decay: float = 0.99,
+ epsilon: float = 1e-5,
+ kmeans_init: bool = True,
+ kmeans_iters: int = 50,
+ threshold_ema_dead_code: float = 2.0,
+ commitment_weight: float = 1.,
+ ):
+ super().__init__()
+ _codebook_dim: int = default(codebook_dim, dim)
+
+ requires_projection = _codebook_dim != dim
+ self.project_in = (nn.Linear(dim, _codebook_dim)) if requires_projection else (nn.Identity())
+ self.project_out = (nn.Linear(_codebook_dim, dim)) if requires_projection else (nn.Identity())
+
+ self.epsilon = epsilon
+ self.commitment_weight = commitment_weight
+
+ self._codebook = EuclideanCodebook(dim=_codebook_dim, codebook_size=codebook_size,
+ kmeans_init=kmeans_init, kmeans_iters=kmeans_iters,
+ decay=decay, epsilon=epsilon,
+ threshold_ema_dead_code=threshold_ema_dead_code)
+ self.codebook_size = codebook_size
+ self.training = True
+
+ @property
+ def codebook(self):
+ return self._codebook.embed
+
+ def encode(self, x, buffers):
+ # x = rearrange(x, "b d n -> b n d")
+ x = self.project_in(x)
+ embed_in = self._codebook.encode(x, buffers)
+ return embed_in
+
+ def decode(self, embed_ind, buffers):
+ quantize = self._codebook.decode(embed_ind, buffers)
+ quantize = self.project_out(quantize)
+ # quantize = rearrange(quantize, "b n d -> b d n")
+ return quantize
+
+ def forward(self, x, buffers):
+ device = x.device
+ # x = rearrange(x, "b d n -> b n d")
+ x = self.project_in(x)
+
+ quantize, embed_ind = self._codebook(x, buffers)
+
+ if self.training:
+ quantize = x + (quantize - x).detach()
+
+ loss = torch.tensor([0.0], device=device, requires_grad=self.training)
+
+ if self.training:
+ if self.commitment_weight > 0:
+ commit_loss = F.mse_loss(quantize.detach(), x)
+ loss = loss + commit_loss * self.commitment_weight
+
+ quantize = self.project_out(quantize)
+ # quantize = rearrange(quantize, "b n d -> b d n")
+ return quantize, embed_ind, loss
+
+
+class DistributedResidualVectorQuantization(nn.Module):
+ """Efficient distributed residual vector quantization implementation.
+ Follows Algorithm 1. in https://arxiv.org/pdf/2107.03312.pdf
+ """
+ def __init__(self, *,
+ num_quantizers,
+ quantize_dropout: bool = False,
+ rand_num_quant: tp.Optional[tp.List] = None,
+ **kwargs):
+ super().__init__()
+ """
+ dim: int,
+ codebook_size: int,
+ codebook_dim: tp.Optional[int] = None,
+ """
+ codebook_size, codebook_dim = kwargs["codebook_size"], kwargs["codebook_dim"] if kwargs["codebook_dim"] else kwargs["dim"]
+ kmeans_init = kwargs["kmeans_init"]
+ if isinstance(kmeans_init, bool):
+ if not kwargs["kmeans_init"]:
+ # use uniform init
+ embed = uniform_init(num_quantizers, codebook_size, codebook_dim)
+ inited = True
+ else:
+ # to perform kmeans init on first batch
+ embed = torch.zeros(num_quantizers, codebook_size, codebook_dim)
+ inited = False
+ elif isinstance(kmeans_init, str):
+ # use prepared kmeans init
+ embed = np.load(kmeans_init)
+ embed = torch.from_numpy(embed)
+ if embed.dim() == 2:
+ embed = embed.unsqueeze(0)
+ inited = True
+ else:
+ raise TypeError("kmeans_init should be either a bool or string path to init weights.")
+
+ self.register_buffer("inited", torch.Tensor([[inited] for _ in range(num_quantizers)]))
+ self.register_buffer("cluster_size", torch.zeros(num_quantizers, codebook_size))
+ self.register_buffer("embed", embed)
+ self.register_buffer("embed_avg", embed.clone())
+
+ self.q0_ds_ratio = 1
+ if "q0_ds_ratio" in kwargs:
+ self.q0_ds_ratio = kwargs.pop("q0_ds_ratio")
+
+ self.layers = nn.ModuleList()
+ for i in range(num_quantizers):
+ vq_args = dict(**kwargs)
+ vq = VectorQuantization(**vq_args)
+ self.layers.append(vq)
+
+ self.quantize_dropout = quantize_dropout
+ self.rand_num_quant = rand_num_quant
+
+ def forward(self, x, n_q: tp.Optional[int] = None):
+ quantized_out = torch.zeros_like(x)
+ residual = x
+ bb, cc, tt = x.shape
+ device = x.device
+
+ all_losses = []
+ all_indices = []
+ all_sub_quants = []
+ n_q = n_q or len(self.layers)
+
+ should_quantize_dropout = self.training and self.quantize_dropout and self.rand_num_quant is not None
+ if should_quantize_dropout:
+ rand_quantize_dropout_index = random.choice(self.rand_num_quant)
+
+ null_indices_shape = (x.shape[0], x.shape[2])
+ null_indices = torch.full(null_indices_shape, -1., device=device, dtype=torch.long)
+ null_loss = torch.full((1,), 0., device=device, dtype=x.dtype)
+ null_sub_quant = torch.full(x.shape, -1, device=device, dtype=x.dtype)
+
+ for quantizer_index, layer in enumerate(self.layers[:n_q]):
+ # dropout except the first quantizer
+ if should_quantize_dropout and quantizer_index >= rand_quantize_dropout_index:
+ all_indices.append(null_indices)
+ all_losses.append(null_loss)
+ all_sub_quants.append(null_sub_quant)
+ continue
+
+ quant_in = residual
+ if self.q0_ds_ratio > 1 and quantizer_index == 0:
+ quant_in = F.interpolate(quant_in, size=[tt//2])
+ quantized, indices, loss = layer(quant_in, [
+ self.inited[quantizer_index],
+ self.cluster_size[quantizer_index],
+ self.embed[quantizer_index],
+ self.embed_avg[quantizer_index]
+ ])
+ if self.q0_ds_ratio > 1 and quantizer_index == 0:
+ quantized = F.interpolate(quantized, size=[tt])
+ indices = F.interpolate(indices.unsqueeze(1).float(), size=[tt]).squeeze(1).long()
+ residual = residual - quantized
+ quantized_out = quantized_out + quantized
+
+ all_indices.append(indices)
+ all_losses.append(loss)
+ all_sub_quants.append(quantized)
+
+ # sync buffers after one forward step
+ # distrib.broadcast_tensors(self.buffers())
+ out_losses, out_indices, out_sub_quants = map(torch.stack, (all_losses, all_indices, all_sub_quants))
+
+ return quantized_out, out_indices, out_losses
+
+ def encode(self, x: torch.Tensor, n_q: tp.Optional[int] = None) -> torch.Tensor:
+ residual = x
+ all_indices = []
+ n_q = n_q or len(self.layers)
+ for i, layer in enumerate(self.layers[:n_q]):
+ indices = layer.encode(residual, [
+ self.inited[i],
+ self.cluster_size[i],
+ self.embed[i],
+ self.embed_avg[i]
+ ])
+ quantized = layer.decode(indices, [
+ self.inited[i],
+ self.cluster_size[i],
+ self.embed[i],
+ self.embed_avg[i]
+ ])
+ residual = residual - quantized
+ all_indices.append(indices)
+ out_indices = torch.stack(all_indices)
+ return out_indices
+
+ def decode(self, q_indices: torch.Tensor) -> torch.Tensor:
+ quantized_out = torch.tensor(0.0, device=q_indices.device)
+ for i, indices in enumerate(q_indices):
+ layer = self.layers[i]
+ quantized = layer.decode(indices, [
+ self.inited[i],
+ self.cluster_size[i],
+ self.embed[i],
+ self.embed_avg[i]
+ ])
+ quantized_out = quantized_out + quantized
+ return quantized_out
+
+
+class DistributedGroupResidualVectorQuantization(nn.Module):
+ """Efficient distributed group residual vector quantization implementation.
+ Follows Algorithm 1. in https://arxiv.org/abs/2305.02765
+ Group Then rvq
+ """
+ def __init__(self, *,
+ num_groups,
+ num_quantizers,
+ quantize_dropout: bool = False,
+ rand_num_quant: tp.Optional[tp.List] = None,
+ **kwargs):
+ super().__init__()
+ self.rvqs = nn.ModuleList(
+ [
+ DistributedResidualVectorQuantization(
+ num_quantizers=num_quantizers,
+ quantize_dropout=quantize_dropout,
+ rand_num_quant=rand_num_quant,
+ **kwargs
+ )
+ for _ in range(num_groups)
+ ]
+ )
+ self.num_groups = num_groups
+
+ def forward(self, x, n_q: tp.Optional[int] = None):
+ x_lst = torch.chunk(x, chunks=self.num_groups, dim=1)
+ all_quantized_out = []
+ all_indices = []
+ all_losses = []
+ for mod, item in zip(self.rvqs, x_lst):
+ quantized_out, out_indices, out_losses = mod(item, n_q)
+ all_quantized_out.append(quantized_out)
+ all_indices.append(out_indices)
+ all_losses.append(out_losses)
+
+ out_losses = torch.stack(all_losses, dim=1).mean(dim=1)
+
+ return torch.cat(all_quantized_out, dim=1), torch.stack(all_indices, dim=1), out_losses
+
+ def encode(self, x: torch.Tensor, n_q: tp.Optional[int] = None) -> torch.Tensor:
+ x_lst = torch.chunk(x, chunks=self.num_groups, dim=1)
+ return torch.stack([mod.encode(item, n_q) for mod, item in zip(self.rvqs, x_lst)], dim=1)
+
+ def decode(self, q_indices: torch.Tensor) -> torch.Tensor:
+ q_indices_lst = torch.chunk(q_indices, chunks=self.num_groups, dim=1)
+ return torch.cat([mod.decode(item.squeeze(1)) for mod, item in zip(self.rvqs, q_indices_lst)], dim=1)
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/speech_vq.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/speech_vq.py
new file mode 100644
index 0000000..e206303
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/speech_vq.py
@@ -0,0 +1,357 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import sox
+import copy
+import torch
+import operator
+import onnxruntime
+
+import torch.nn as nn
+import torch.nn.functional as F
+import torchaudio.compliance.kaldi as kaldi
+
+from librosa.filters import mel as librosa_mel_fn
+from itertools import accumulate
+from typing import List
+from torch import Tensor
+
+from .core_vq import DistributedGroupResidualVectorQuantization
+from .whisper_encoder import WhisperEncoder, Conv1d, ConvTranspose1d
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+def spectral_normalize_torch(magnitudes):
+ output = dynamic_range_compression_torch(magnitudes)
+ return output
+
+class MelSpectrogramFeatures(nn.Module):
+ """
+ Calculate the BigVGAN style mel spectrogram of an input signal.
+ Args:
+ filter_length (int): The number of samples in the filter window, used for the Fourier Transform. Default is 1024.
+ hop_length (int): The number of samples between successive frames (stride of the STFT). Default is 160.
+ win_length (int): The length of the window function applied to each frame, usually less than or equal to the filter length. Default is 640.
+ n_mel_channels (int): The number of Mel-frequency channels to output from the Mel-scale spectrogram. Default is 80.
+ mel_fmin (int): The minimum frequency (in Hz) of the Mel-scale spectrogram. Default is 0.
+ mel_fmax (int): The maximum frequency (in Hz) of the Mel-scale spectrogram. Default is 8000.
+ sampling_rate (int): The sampling rate of the audio data (in Hz). Default is 16000.
+ sampling_rate_org (int, optional): The original sampling rate of the audio data before any resampling (in Hz), if applicable. Default is None.
+ padding (str): The padding mode for the input signal. 'center' pads the signal symmetrically around its center. Default is 'center'.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ def __init__(self,
+ filter_length=1024,
+ hop_length=160,
+ win_length=640,
+ n_mel_channels=80,
+ mel_fmin=0,
+ mel_fmax=8000,
+ sampling_rate=16000,
+ sampling_rate_org=None,
+ padding='center',
+ use_db = False,
+ ):
+ super().__init__()
+ if padding not in ["center", "same"]:
+ raise ValueError("Padding must be 'center' or 'same'.")
+ self.padding = padding
+
+ self.filter_length = filter_length
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.n_mel_channels = n_mel_channels
+ self.mel_fmin = mel_fmin
+ self.mel_fmax = mel_fmax
+ self.sampling_rate = sampling_rate
+ self.sampling_rate_org = sampling_rate_org if sampling_rate_org is not None else sampling_rate
+ self.mel_basis = {}
+ self.hann_window = {}
+
+ def forward(self, audio: torch.Tensor, **kwargs) -> torch.Tensor:
+ with torch.no_grad():
+ feats = self.extract(audio, **kwargs)
+ return feats
+
+ def extract(self, audio, **kwargs):
+
+ if len(audio.shape) == 3:
+ audio = audio.squeeze(1) if audio.shape[1] == 1 else audio.squeeze(2)
+ assert len(audio.shape) == 2
+
+ y = audio
+ if len(list(self.mel_basis.keys())) == 0:
+ mel = librosa_mel_fn(sr=self.sampling_rate, n_fft=self.filter_length, n_mels=self.n_mel_channels, fmin=self.mel_fmin, fmax=self.mel_fmax)
+ self.mel_basis[str(self.mel_fmax)+'_'+str(y.device)] = torch.from_numpy(mel).float().to(y.device)
+ self.hann_window[str(y.device)] = torch.hann_window(self.win_length).to(y.device)
+
+ y = torch.nn.functional.pad(y.unsqueeze(1), (int((self.filter_length-self.hop_length)/2), int((self.filter_length-self.hop_length)/2)), mode='reflect')
+ y = y.squeeze(1)
+
+ spec = torch.stft(y, self.filter_length, hop_length=self.hop_length, win_length=self.win_length, window=self.hann_window[str(y.device)],
+ center=False, pad_mode='reflect', normalized=False, onesided=True, return_complex=True)
+ spec = torch.view_as_real(spec)
+ spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
+
+ spec = torch.matmul(self.mel_basis[str(self.mel_fmax)+'_'+str(y.device)], spec)
+ spec = spectral_normalize_torch(spec)
+
+ return spec
+
+
+class XVectorExtractor(nn.Module):
+ def __init__(self, audio_codec_with_xvector):
+ super().__init__()
+ option = onnxruntime.SessionOptions()
+ option.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
+ option.intra_op_num_threads = 1
+ providers = ["CPUExecutionProvider"]
+ self.ort_session = onnxruntime.InferenceSession(audio_codec_with_xvector, sess_options=option, providers=providers)
+
+ self.tfm = sox.Transformer()
+ self.tfm.norm(db_level=-6)
+
+ self.mel_ext = MelSpectrogramFeatures(
+ filter_length=1024,
+ hop_length=160,
+ win_length=640,
+ n_mel_channels=80,
+ mel_fmin=0,
+ mel_fmax=8000,
+ sampling_rate=16000
+ )
+
+ def extract_code(self, audio):
+ with torch.no_grad():
+ norm_audio = self.sox_norm(audio)
+
+ norm_audio = torch.from_numpy(copy.deepcopy(norm_audio)).unsqueeze(0)
+ feat = kaldi.fbank(norm_audio,
+ num_mel_bins=80,
+ dither=0,
+ sample_frequency=16000)
+ feat = feat - feat.mean(dim=0, keepdim=True)
+ norm_embedding = self.ort_session.run(None, {self.ort_session.get_inputs()[0].name: feat.unsqueeze(dim=0).cpu().numpy()})[0].flatten()
+ norm_embedding = F.normalize(torch.from_numpy(norm_embedding), dim=0)
+
+ ref_mel = self.mel_ext.extract(audio=norm_audio)
+
+ return norm_embedding.numpy(), ref_mel.permute(0,2,1).squeeze(0).numpy()
+
+ def sox_norm(self, audio):
+ wav_norm = self.tfm.build_array(input_array=audio, sample_rate_in=16000)
+ return wav_norm
+
+
+class WhisperEncoderVQ(WhisperEncoder):
+ def __init__(
+ self,
+ n_mels: int,
+ n_ctx: int,
+ n_state: int,
+ n_head: int,
+ n_layer: int,
+ n_window: int = 1500,
+ output_dim: int = 512,
+ grad_checkpointing: bool = False,
+ enable_mp: bool = False,
+ audio_sequence_parallel: bool = False,
+ audio_vq_layers: int = -1,
+ audio_vq_type: str = "NULL",
+ audio_vq_codebook_size: int = 4096,
+ audio_vq_pe: bool = False,
+ audio_vq_commit_loss: float = 0.0,
+ audio_vq_out_commit_loss: float = 0.0,
+ audio_vq_no_quantize: bool = False,
+ audio_vq_ff_layer: int = 0,
+ audio_vq_threshold_ema_dead_code: float = 0.1,
+ audio_vq_codebook_dim: int = None,
+ audio_vq_ds_rate: int = None,
+ ):
+ super().__init__(n_mels, n_ctx, n_state, n_head, n_layer, n_window, output_dim, grad_checkpointing, enable_mp, audio_sequence_parallel)
+
+ self.audio_vq_layers = audio_vq_layers
+ self.audio_vq_type = audio_vq_type
+ self.audio_vq_codebook_size = audio_vq_codebook_size
+ self.audio_vq_pe = audio_vq_pe
+ self.audio_vq_commit_loss = audio_vq_commit_loss
+ self.audio_vq_out_commit_loss = audio_vq_out_commit_loss
+ self.audio_vq_no_quantize = audio_vq_no_quantize
+ self.audio_vq_ff_layer = audio_vq_ff_layer
+
+ if audio_vq_layers > 0:
+ self.vq_feature_dim = self.n_state
+ self.audio_vq_ds_rate = 1
+ else:
+ raise NotImplementedError(f"Unsupported audio_vq_layers: {audio_vq_layers}")
+
+ if self.audio_vq_ds_rate == audio_vq_ds_rate:
+ self.audio_vq_downsample = nn.Identity()
+ self.audio_vq_upsample = nn.Identity()
+ else:
+ assert audio_vq_ds_rate % self.audio_vq_ds_rate == 0
+ stride = audio_vq_ds_rate // self.audio_vq_ds_rate
+ self.audio_vq_downsample = Conv1d(self.vq_feature_dim, self.vq_feature_dim, kernel_size=stride, stride=stride)
+ self.audio_vq_upsample = ConvTranspose1d(self.vq_feature_dim, self.vq_feature_dim, kernel_size=stride, stride=stride)
+ self.audio_vq_ds_rate = audio_vq_ds_rate
+
+ if audio_vq_type == "GRVQ":
+ self.audio_quantizer = DistributedGroupResidualVectorQuantization(
+ codebook_size = audio_vq_codebook_size,
+ dim = self.vq_feature_dim,
+ codebook_dim = self.vq_codebook_dim if audio_vq_codebook_dim is None else audio_vq_codebook_dim,
+ num_groups=1,
+ num_quantizers=1,
+ kmeans_init=False,
+ threshold_ema_dead_code = audio_vq_threshold_ema_dead_code
+ )
+ else:
+ raise NotImplementedError(f"Unsupported audio_vq_type: {audio_vq_type}")
+
+ if self.audio_vq_pe:
+ self.project_after_vq_pe = nn.Linear(self.n_state, self.n_state)
+
+ def _calc_quantize_activities(self, indices):
+ indices_onehot = F.one_hot(indices.long().flatten(), self.audio_vq_codebook_size).sum(dim=0)
+ vq_num_activities = sum(indices_onehot>0)
+ vq_num_tokens = sum(indices_onehot)
+ return {
+ "vq_num_activities": vq_num_activities,
+ "vq_num_tokens": vq_num_tokens,
+ }
+
+ def _do_quantize(self, x, pe=None, y=None):
+ """
+ x: torch.Tensor, shape = (T, D)
+ q: torch.Tensor, shape = (T, D)
+ i: torch.Tensor, shape = (T)
+ """
+ if self.audio_vq_out_commit_loss > 0:
+ x_teacher = x.clone()
+ x = x.unsqueeze(0)
+
+ x = self.audio_vq_downsample(x.transpose(1, 2))
+ x = x.transpose(1, 2)
+
+ vq_stats = {}
+
+ if self.audio_vq_type == "GRVQ":
+ if self.training:
+ raise NotImplementedError
+ else:
+ indices = self.audio_quantizer.encode(x)
+ x = self.audio_quantizer.decode(indices)
+ indices = indices.squeeze(2).squeeze(1)
+
+ vq_stats.update(self._calc_quantize_activities(indices))
+
+ x, indices = x.squeeze(0), indices.squeeze(0)
+ if self.audio_vq_pe:
+ x = x + pe
+ x = self.project_after_vq_pe(x)
+
+ x = self.audio_vq_upsample(x.unsqueeze(0).transpose(1, 2))
+ x = x.transpose(1, 2).squeeze(0)
+
+ if self.audio_vq_out_commit_loss > 0:
+ vq_out_commit_loss = F.mse_loss(x_teacher.detach(), x)
+ vq_stats["vq_out_commit_loss"] = vq_out_commit_loss * self.audio_vq_out_commit_loss
+
+ return x, indices, vq_stats
+
+ def forward(self, x_list: List[Tensor], audio_mellens:List[int], audio_aftercnnlens:List[int], audio_seqlens:List[int], return_indices=False, audio_pitchs=None):
+ """
+ x : torch.Tensor, shape = (n_mels, n_ctx)
+ the mel spectrogram of the audio
+ """
+
+ aftercnn_x_list = []
+ pe_for_vq_list = []
+ for each_x in x_list:
+ each_x_split_list = each_x.split(self.n_window * 2, dim=1)
+ for each_x_split in each_x_split_list:
+ each_x_split = F.gelu(self.conv1(each_x_split))
+ each_x_split = F.gelu(self.conv2(each_x_split))
+ each_x_split = each_x_split.permute(1, 0) # L,D
+
+ each_positional_embedding_split = self.positional_embedding[:each_x_split.shape[0]]
+ aftercnn_x_list.append(each_x_split+each_positional_embedding_split.to(each_x_split.dtype))
+
+ pe_for_vq_split = self.positional_embedding[:each_x_split.shape[0] // self.audio_vq_ds_rate]
+ pe_for_vq_list.append(pe_for_vq_split.to(each_x_split.dtype))
+
+ pe_for_vq = torch.cat(pe_for_vq_list, dim=0)
+ x = torch.cat(aftercnn_x_list, dim=0)
+ src_len = x.size(0)
+
+ output_list = []
+ for item in audio_aftercnnlens:
+ while item > self.n_window:
+ output_list.append(self.n_window)
+ item -= self.n_window
+ output_list.append(item)
+
+ cu_seqlens = list(accumulate(output_list, func=operator.add,initial=0))
+ cu_seqlens = torch.Tensor(cu_seqlens).to(device=x.device, dtype=torch.int32)
+
+ layer_id = 0
+
+ for block in self.blocks:
+ layer_id+=1
+
+ x = block(x, cu_seqlens=cu_seqlens)
+
+ if self.audio_vq_layers == layer_id: # vq inside encoder
+ x, indices, vq_stats = self._do_quantize(x, pe_for_vq)
+ if return_indices:
+ return x, indices
+
+ if self.avg_pooler:
+ x_list = x.split(audio_aftercnnlens, dim=0)
+ token_x_list = []
+ for x in x_list:
+ x = x.permute(1, 0)
+ x = self.avg_pooler(x)
+ x = x.permute(1, 0)
+ token_x_list.append(x)
+ x = torch.cat(token_x_list, dim=0)
+
+ x = self.ln_post(x)
+
+ x = self.proj(x)
+
+ output = torch.zeros(
+ (x.size(0) + len(audio_seqlens) * 2, x.size(1)),
+ device=x.device, dtype=x.dtype
+ )
+
+ audio_seqlens_acc = list(accumulate(audio_seqlens, func=operator.add, initial=0))
+ start_ids = torch.tensor(audio_seqlens_acc[:-1], device=x.device, dtype=torch.int32)
+ end_ids = torch.tensor(audio_seqlens_acc[1:], device=x.device, dtype=torch.int32) - 1
+
+ audio_tokens_mask = torch.ones(output.size(0), device=x.device, dtype=torch.bool)
+ audio_tokens_mask[start_ids] = False
+ audio_tokens_mask[end_ids] = False
+ output[start_ids] = self.audio_bos_eos_token.weight[0].to(x.dtype)
+ output[end_ids] = self.audio_bos_eos_token.weight[1].to(x.dtype)
+ output[audio_tokens_mask] = x
+
+ if self.audio_vq_type != "NULL":
+ return output, vq_stats
+ return output
\ No newline at end of file
diff --git a/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/whisper_encoder.py b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/whisper_encoder.py
new file mode 100644
index 0000000..a1c97bb
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/core/tokenizer_25hz/vq/whisper_encoder.py
@@ -0,0 +1,406 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import math
+import torch
+import operator
+
+import numpy as np
+import torch.nn.functional as F
+
+from functools import lru_cache
+from typing import Optional, Union, List
+from torch import nn, Tensor
+from itertools import accumulate
+
+try:
+ from flash_attn.flash_attn_interface import flash_attn_varlen_func as flash_attn_varlen_func
+except ImportError:
+ try:
+ from flash_attn.flash_attn_interface import flash_attn_unpadded_func as flash_attn_varlen_func
+ except ImportError:
+ print("\n********\nWarning: flash-attn is not installed. Will only run the manual PyTorch version. Please install flash-attn for faster inference.\n********\n ")
+ flash_attn_varlen_func = None
+
+
+N_FFT = 400
+HOP_LENGTH = 160
+
+
+@lru_cache(maxsize=None)
+def mel_filters(device, n_mels: int) -> torch.Tensor:
+ """
+ load the mel filterbank matrix for projecting STFT into a Mel spectrogram.
+ Allows decoupling librosa dependency; saved using:
+
+ np.savez_compressed(
+ "mel_filters.npz",
+ mel_80=librosa.filters.mel(sr=16000, n_fft=400, n_mels=80),
+ mel_128=librosa.filters.mel(sr=16000, n_fft=400, n_mels=128),
+ )
+ """
+ assert n_mels in {80, 128}, f"Unsupported n_mels: {n_mels}"
+
+ filters_path = os.path.join(os.path.dirname(__file__), "assets", "mel_filters.npz")
+ with np.load(filters_path, allow_pickle=False) as f:
+ return torch.from_numpy(f[f"mel_{n_mels}"]).to(device)
+
+
+def log_mel_spectrogram(
+ audio: Union[str, np.ndarray, torch.Tensor],
+ n_mels: int = 80,
+ padding: int = 0,
+ device: Optional[Union[str, torch.device]] = None,
+):
+ """
+ Compute the log-Mel spectrogram of
+
+ Parameters
+ ----------
+ audio: Union[str, np.ndarray, torch.Tensor], shape = (*)
+ The path to audio or either a NumPy array or Tensor containing the audio waveform in 16 kHz
+
+ n_mels: int
+ The number of Mel-frequency filters, only 80 is supported
+
+ padding: int
+ Number of zero samples to pad to the right
+
+ device: Optional[Union[str, torch.device]]
+ If given, the audio tensor is moved to this device before STFT
+
+ Returns
+ -------
+ torch.Tensor, shape = (80, n_frames)
+ A Tensor that contains the Mel spectrogram
+ """
+ if not torch.is_tensor(audio):
+ audio = torch.from_numpy(audio)
+
+ if device is not None:
+ audio = audio.to(device)
+ if padding > 0:
+ audio = F.pad(audio, (0, padding))
+ window = torch.hann_window(N_FFT).to(audio.device)
+ stft = torch.stft(audio, N_FFT, HOP_LENGTH, window=window, return_complex=True)
+ magnitudes = stft[..., :-1].abs() ** 2
+
+ filters = mel_filters(audio.device, n_mels)
+ mel_spec = filters @ magnitudes
+
+ log_spec = torch.clamp(mel_spec, min=1e-10).log10()
+ log_spec = torch.maximum(log_spec, log_spec.max() - 8.0)
+ log_spec = (log_spec + 4.0) / 4.0
+ return log_spec
+
+
+def get_T_after_cnn(L_in, dilation=1):
+ for (padding, kernel_size, stride) in eval("[(1,3,1)] + [(1,3,2)] "):
+ L_out = L_in + 2 * padding - dilation * (kernel_size - 1) - 1
+ L_out = 1 + L_out // stride
+ L_in = L_out
+ return L_out
+
+
+def get_mel_audio(audio, padding=False, audio_vq_ds_rate = 1, n_mels = 128):
+ audio_len = len(audio)
+ if padding:
+ reduction = 160 * 2 * audio_vq_ds_rate
+ audio_pad = math.ceil(audio_len / reduction) * reduction - audio_len
+ mel = log_mel_spectrogram(audio, n_mels=n_mels, padding=audio_pad)
+ else:
+ mel = log_mel_spectrogram(audio, n_mels=n_mels) # [F,T]
+ return mel
+
+
+def sinusoids(length, channels, max_timescale=10000):
+ """Returns sinusoids for positional embedding"""
+ assert channels % 2 == 0
+ log_timescale_increment = np.log(max_timescale) / (channels // 2 - 1)
+ inv_timescales = torch.exp(-log_timescale_increment * torch.arange(channels // 2))
+ scaled_time = torch.arange(length)[:, np.newaxis] * inv_timescales[np.newaxis, :]
+ return torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=1)
+
+
+class Conv1d(nn.Conv1d):
+ def _conv_forward(
+ self, x: Tensor, weight: Tensor, bias: Optional[Tensor]
+ ) -> Tensor:
+ return super()._conv_forward(
+ x, weight.to(x.dtype), None if bias is None else bias.to(x.dtype)
+ )
+
+
+class ConvTranspose1d(nn.ConvTranspose1d):
+ def _conv_forward(
+ self, x: Tensor, weight: Tensor, bias: Optional[Tensor]
+ ) -> Tensor:
+ return super()._conv_forward(
+ x, weight.to(x.dtype), None if bias is None else bias.to(x.dtype)
+ )
+
+
+class Linear(nn.Linear):
+ def forward(self, x: Tensor) -> Tensor:
+ return F.linear(x, self.weight.to(x.dtype), None if self.bias is None else self.bias.to(x.dtype) )
+
+
+class MultiHeadAttention(nn.Module):
+ def __init__(self, n_state: int, n_head: int):
+ super().__init__()
+ self.n_head = n_head
+ self.query = Linear(n_state, n_state)
+ self.key = Linear(n_state, n_state, bias=False)
+ self.value = Linear(n_state, n_state)
+ self.out = Linear(n_state, n_state)
+
+ self.use_flash_attention = True
+
+ def forward(
+ self,
+ x: Tensor,
+ cu_seqlens = None,
+ ):
+ q = self.query(x)
+ k = self.key(x)
+ v = self.value(x)
+
+ if self.use_flash_attention:
+ if flash_attn_varlen_func is None:
+ x = self.qkv_attention_manual(q, k, v, cu_seqlens=cu_seqlens)
+ else:
+ if q.dtype not in [torch.float16, torch.bfloat16]:
+ x = self.qkv_attention_manual(q, k, v, cu_seqlens=cu_seqlens)
+ self.use_flash_attention = False
+ else:
+ x = self.qkv_flash_attention(q, k, v, cu_seqlens=cu_seqlens)
+ else:
+ x = self.qkv_attention_manual(q, k, v, cu_seqlens=cu_seqlens)
+
+ output = self.out(x)
+ return output
+
+ def qkv_flash_attention(
+ self, q: Tensor, k: Tensor, v: Tensor, cu_seqlens=None
+ ):
+ n_ctx, n_state = q.shape
+ # scale = (n_state // self.n_head) ** -0.25
+ q = q.view(n_ctx, self.n_head, -1)# (batch_size, seqlen, nheads, headdim)
+ k = k.view(n_ctx, self.n_head, -1)
+ v = v.view(n_ctx, self.n_head, -1)
+
+ max_seqlen = (cu_seqlens[1:] - cu_seqlens[:-1]).max().item()
+
+
+ x = flash_attn_varlen_func(
+ q, k, v, cu_seqlens, cu_seqlens, max_seqlen, max_seqlen, dropout_p=0.0
+ )
+ x = x.reshape(n_ctx, n_state)
+ return x
+
+ def qkv_attention_manual(
+ self, q: Tensor, k: Tensor, v: Tensor, cu_seqlens: Tensor
+ ):
+ n_ctx, n_state = q.shape
+ head_dim = n_state // self.n_head
+ scale = head_dim ** -0.5
+
+ q = q.view(n_ctx, self.n_head, head_dim)
+ k = k.view(n_ctx, self.n_head, head_dim)
+ v = v.view(n_ctx, self.n_head, head_dim)
+
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ batch_size = len(seqlens)
+ max_seqlen = max(seqlens)
+
+ q_padded = torch.zeros(batch_size, max_seqlen, self.n_head, head_dim, dtype=q.dtype, device=q.device)
+ k_padded = torch.zeros_like(q_padded)
+ v_padded = torch.zeros_like(q_padded)
+
+ for i in range(batch_size):
+ start_idx = cu_seqlens[i]
+ end_idx = cu_seqlens[i+1]
+ seq_len = seqlens[i]
+ q_padded[i, :seq_len] = q[start_idx:end_idx]
+ k_padded[i, :seq_len] = k[start_idx:end_idx]
+ v_padded[i, :seq_len] = v[start_idx:end_idx]
+
+ q_padded = q_padded.transpose(1, 2)
+ k_padded = k_padded.transpose(1, 2)
+ v_padded = v_padded.transpose(1, 2)
+
+ attn_mask = torch.arange(max_seqlen, device=q.device)[None, :] < torch.tensor(seqlens, device=q.device)[:, None]
+ attn_mask = attn_mask.unsqueeze(1).unsqueeze(2)
+
+ attn_mask = attn_mask.masked_fill(attn_mask == 0, -torch.finfo(q.dtype).max)
+
+ attn_scores = torch.matmul(q_padded, k_padded.transpose(-2, -1)) * scale
+ attn_scores = attn_scores + attn_mask
+ attn_weights = F.softmax(attn_scores, dim=-1)
+
+ context = torch.matmul(attn_weights, v_padded)
+
+ context = context.transpose(1, 2).contiguous().view(batch_size, max_seqlen, n_state)
+
+ output_packed = torch.cat([context[i, :seqlens[i]] for i in range(batch_size)], dim=0)
+
+ assert output_packed.shape == (n_ctx, n_state)
+
+ return output_packed
+
+
+class ResidualAttentionBlock(nn.Module):
+ def __init__(self, n_state: int, n_head: int,
+ enable_mp: bool = False, sequence_parallel: bool = False):
+ super().__init__()
+ n_mlp = n_state * 4
+ self.attn_ln = nn.LayerNorm(n_state)
+ self.mlp_ln = nn.LayerNorm(n_state)
+
+ self.attn = MultiHeadAttention(n_state, n_head)
+ self.mlp = nn.Sequential(
+ Linear(n_state, n_mlp), nn.GELU(), Linear(n_mlp, n_state)
+ )
+
+ def forward(
+ self,
+ x: Tensor,
+ cu_seqlens = None
+ ):
+ x = x + self.attn(self.attn_ln(x), cu_seqlens=cu_seqlens)
+ x = x + self.mlp(self.mlp_ln(x))
+ return x
+
+
+class WhisperEncoder(nn.Module):
+ def __init__(
+ self,
+ n_mels: int,
+ n_ctx: int,
+ n_state: int,
+ n_head: int,
+ n_layer: int,
+ n_window: int = 1500,
+ output_dim: int = 512,
+ grad_checkpointing: bool = False,
+ enable_mp: bool = False,
+ audio_sequence_parallel: bool = False,
+ ):
+ super().__init__()
+ self.conv1 = Conv1d(n_mels, n_state, kernel_size=3, padding=1)
+ self.conv2 = Conv1d(n_state, n_state, kernel_size=3, stride=2, padding=1)
+ self.register_buffer("positional_embedding", sinusoids(n_ctx, n_state))
+ self.n_layer = n_layer
+ self.n_mels = n_mels
+
+ self.blocks = nn.ModuleList(
+ [ResidualAttentionBlock(n_state, n_head, enable_mp=enable_mp, sequence_parallel=audio_sequence_parallel)
+ for _ in range(n_layer)]
+ )
+ self.ln_post = nn.LayerNorm(n_state)
+ self.avg_pooler = nn.AvgPool1d(2, stride=2)
+
+ self.proj = torch.nn.Linear(n_state, output_dim)
+
+ self.audio_bos_eos_token = nn.Embedding(2, output_dim)
+
+ self.output_dim = output_dim
+ self.grad_checkpointing = grad_checkpointing
+ self.enable_mp = enable_mp
+ self.n_head = n_head
+ self.n_state = n_state
+ self.n_window = n_window
+
+ self.audio_sequence_parallel = audio_sequence_parallel
+
+ self.tp_world_size = 1
+
+ self.set_audio_sync()
+
+ def set_audio_sync(self):
+ for name, param in self.named_parameters():
+ if not name.startswith("blocks"):
+ setattr(param, "audio_sync", True)
+
+ def forward(self, x_list: List[Tensor], audio_mellens:List[int], audio_aftercnnlens:List[int], audio_seqlens:List[int]):
+ """
+ x : torch.Tensor, shape = (n_mels, n_ctx)
+ the mel spectrogram of the audio
+ """
+
+ aftercnn_x_list = []
+ for each_x in x_list:
+ each_x_split_list = each_x.split(self.n_window * 2, dim=1)
+ for each_x_split in each_x_split_list:
+ each_x_split = F.gelu(self.conv1(each_x_split))
+ each_x_split = F.gelu(self.conv2(each_x_split))
+ each_x_split = each_x_split.permute(1, 0) # L,D
+ each_positional_embedding_split = self.positional_embedding[:each_x_split.shape[0]]
+ aftercnn_x_list.append(each_x_split+each_positional_embedding_split.to(each_x_split.dtype))
+
+ x = torch.cat(aftercnn_x_list, dim=0)
+ src_len = x.size(0)
+
+ output_list = []
+ for item in audio_aftercnnlens:
+ while item > self.n_window:
+ output_list.append(self.n_window)
+ item -= self.n_window
+ output_list.append(item)
+
+ cu_seqlens = list(accumulate(output_list, func=operator.add,initial=0))
+ cu_seqlens = torch.Tensor(cu_seqlens).to(device=x.device, dtype=torch.int32)
+
+ layer_id = 0
+ for block in self.blocks:
+ layer_id+=1
+ x = block(x, cu_seqlens=cu_seqlens)
+
+ if self.avg_pooler:
+ x_list = x.split(audio_aftercnnlens, dim=0)
+ token_x_list = []
+ for x in x_list:
+ x = x.permute(1, 0)
+ x = self.avg_pooler(x)
+ x = x.permute(1, 0)
+ token_x_list.append(x)
+ x = torch.cat(token_x_list, dim=0)
+
+ x = self.ln_post(x)
+ x = self.proj(x)
+
+ output = torch.zeros(
+ (x.size(0) + len(audio_seqlens) * 2, x.size(1)),
+ device=x.device, dtype=x.dtype
+ )
+
+ audio_seqlens_acc = list(accumulate(audio_seqlens, func=operator.add, initial=0))
+ start_ids = torch.tensor(audio_seqlens_acc[:-1], device=x.device, dtype=torch.int32)
+ end_ids = torch.tensor(audio_seqlens_acc[1:], device=x.device, dtype=torch.int32) - 1
+
+ audio_tokens_mask = torch.ones(output.size(0), device=x.device, dtype=torch.bool)
+ audio_tokens_mask[start_ids] = False
+ audio_tokens_mask[end_ids] = False
+ output[start_ids] = self.audio_bos_eos_token.weight[0].to(x.dtype)
+ output[end_ids] = self.audio_bos_eos_token.weight[1].to(x.dtype)
+ output[audio_tokens_mask] = x
+ return output
+
+ def lock(self, layers: int):
+ self.conv1.requires_grad_(False)
+ self.conv2.requires_grad_(False)
+ for i in range(min(layers, len(self.blocks))):
+ self.blocks[i].requires_grad_(False)
diff --git a/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_model.py b/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_model.py
new file mode 100644
index 0000000..f4d33bf
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_model.py
@@ -0,0 +1,877 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import base64
+import io
+import urllib.request
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+from urllib.parse import urlparse
+
+import librosa
+import numpy as np
+import soundfile as sf
+import torch
+from transformers import AutoConfig, AutoModel, AutoProcessor
+
+from ..core.models import Qwen3TTSConfig, Qwen3TTSForConditionalGeneration, Qwen3TTSProcessor
+
+AudioLike = Union[
+ str, # wav path, URL, base64
+ np.ndarray, # waveform (requires sr)
+ Tuple[np.ndarray, int], # (waveform, sr)
+]
+
+MaybeList = Union[Any, List[Any]]
+
+
+@dataclass
+class VoiceClonePromptItem:
+ """
+ Container for one sample's voice-clone prompt information that can be fed to the model.
+
+ Fields are aligned with `Qwen3TTSForConditionalGeneration.generate(..., voice_clone_prompt=...)`.
+ """
+ ref_code: Optional[torch.Tensor] # (T, Q) or (T,) depending on tokenizer 25Hz/12Hz
+ ref_spk_embedding: torch.Tensor # (D,)
+ x_vector_only_mode: bool
+ icl_mode: bool
+ ref_text: Optional[str] = None
+
+
+class Qwen3TTSModel:
+ """
+ A HuggingFace-style wrapper for Qwen3 TTS models (CustomVoice/VoiceDesign/Base) that provides:
+ - from_pretrained() initialization via AutoModel/AutoProcessor
+ - generation APIs for:
+ * CustomVoice: generate_custom_voice()
+ * VoiceDesign: generate_voice_design()
+ * Base: generate_voice_clone() + create_voice_clone_prompt()
+ - consistent output: (wavs: List[np.ndarray], sample_rate: int)
+
+ Notes:
+ - This wrapper expects the underlying model class to be `Qwen3TTSForConditionalGeneration`
+ - Language / speaker validation is done via model methods:
+ model.get_supported_languages(), model.get_supported_speakers()
+ """
+
+ def __init__(self, model: Qwen3TTSForConditionalGeneration, processor, generate_defaults: Optional[Dict[str, Any]] = None):
+ self.model = model
+ self.processor = processor
+ self.generate_defaults = generate_defaults or {}
+
+ self.device = getattr(model, "device", None)
+ if self.device is None:
+ try:
+ self.device = next(model.parameters()).device
+ except StopIteration:
+ self.device = torch.device("cpu")
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: str,
+ **kwargs,
+ ) -> "Qwen3TTSModel":
+ """
+ Load a Qwen3 TTS model and its processor in HuggingFace `from_pretrained` style.
+
+ This method:
+ 1) Loads config via AutoConfig (so your side can register model_type -> config/model).
+ 2) Loads the model via AutoModel.from_pretrained(...), forwarding `kwargs` unchanged.
+ 3) Loads the processor via AutoProcessor.from_pretrained(model_path).
+ 4) Loads optional `generate_config.json` from the model directory/repo snapshot if present.
+
+ Args:
+ pretrained_model_name_or_path (str):
+ HuggingFace repo id or local directory of the model.
+ **kwargs:
+ Forwarded as-is into `AutoModel.from_pretrained(...)`.
+ Typical examples: device_map="cuda:0", dtype=torch.bfloat16, attn_implementation="flash_attention_2".
+
+ Returns:
+ Qwen3TTSModel:
+ Wrapper instance containing `model`, `processor`, and generation defaults.
+ """
+ AutoConfig.register("qwen3_tts", Qwen3TTSConfig)
+ AutoModel.register(Qwen3TTSConfig, Qwen3TTSForConditionalGeneration)
+ AutoProcessor.register(Qwen3TTSConfig, Qwen3TTSProcessor)
+
+ model = AutoModel.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ if not isinstance(model, Qwen3TTSForConditionalGeneration):
+ raise TypeError(
+ f"AutoModel returned {type(model)}, expected Qwen3TTSForConditionalGeneration. "
+ )
+
+ processor = AutoProcessor.from_pretrained(pretrained_model_name_or_path, fix_mistral_regex=True,)
+
+ generate_defaults = model.generate_config
+ return cls(model=model, processor=processor, generate_defaults=generate_defaults)
+
+ def _supported_languages_set(self) -> Optional[set]:
+ langs = getattr(self.model, "get_supported_languages", None)
+ if callable(langs):
+ v = langs()
+ if v is None:
+ return None
+ return set([str(x).lower() for x in v])
+ return None
+
+ def _supported_speakers_set(self) -> Optional[set]:
+ spks = getattr(self.model, "get_supported_speakers", None)
+ if callable(spks):
+ v = spks()
+ if v is None:
+ return None
+ return set([str(x).lower() for x in v])
+ return None
+
+ def _validate_languages(self, languages: List[str]) -> None:
+ """
+ Validate that requested languages are supported by the model.
+
+ Args:
+ languages (List[str]): Language names for each sample.
+
+ Raises:
+ ValueError: If any language is not supported.
+ """
+ supported = self._supported_languages_set()
+ if supported is None:
+ return
+
+ bad = []
+ for lang in languages:
+ if lang is None:
+ bad.append(lang)
+ continue
+ if str(lang).lower() not in supported:
+ bad.append(lang)
+ if bad:
+ raise ValueError(f"Unsupported languages: {bad}. Supported: {sorted(supported)}")
+
+ def _validate_speakers(self, speakers: List[Optional[str]]) -> None:
+ """
+ Validate that requested speakers are supported by the Instruct model.
+
+ Args:
+ speakers (List[Optional[str]]): Speaker names for each sample.
+
+ Raises:
+ ValueError: If any speaker is not supported.
+ """
+ supported = self._supported_speakers_set()
+ if supported is None:
+ return
+
+ bad = []
+ for spk in speakers:
+ if spk is None or spk == "":
+ continue
+ if str(spk).lower() not in supported:
+ bad.append(spk)
+ if bad:
+ raise ValueError(f"Unsupported speakers: {bad}. Supported: {sorted(supported)}")
+
+ def _is_probably_base64(self, s: str) -> bool:
+ if s.startswith("data:audio"):
+ return True
+ if ("/" not in s and "\\" not in s) and len(s) > 256:
+ return True
+ return False
+
+ def _is_url(self, s: str) -> bool:
+ try:
+ u = urlparse(s)
+ return u.scheme in ("http", "https") and bool(u.netloc)
+ except Exception:
+ return False
+
+ def _decode_base64_to_wav_bytes(self, b64: str) -> bytes:
+ if "," in b64 and b64.strip().startswith("data:"):
+ b64 = b64.split(",", 1)[1]
+ return base64.b64decode(b64)
+
+ def _load_audio_to_np(self, x: str) -> Tuple[np.ndarray, int]:
+ if self._is_url(x):
+ with urllib.request.urlopen(x) as resp:
+ audio_bytes = resp.read()
+ with io.BytesIO(audio_bytes) as f:
+ audio, sr = sf.read(f, dtype="float32", always_2d=False)
+ elif self._is_probably_base64(x):
+ wav_bytes = self._decode_base64_to_wav_bytes(x)
+ with io.BytesIO(wav_bytes) as f:
+ audio, sr = sf.read(f, dtype="float32", always_2d=False)
+ else:
+ audio, sr = librosa.load(x, sr=None, mono=True)
+
+ if audio.ndim > 1:
+ audio = np.mean(audio, axis=-1)
+
+ return audio.astype(np.float32), int(sr)
+
+ def _normalize_audio_inputs(self, audios: Union[AudioLike, List[AudioLike]]) -> List[Tuple[np.ndarray, int]]:
+ """
+ Normalize audio inputs into a list of (waveform, sr).
+
+ Supported forms:
+ - str: wav path / URL / base64 audio string
+ - (np.ndarray, sr): waveform + sampling rate
+ - list of the above
+
+ Args:
+ audios:
+ Audio input(s).
+
+ Returns:
+ List[Tuple[np.ndarray, int]]:
+ List of (float32 waveform, original sr).
+
+ Raises:
+ ValueError: If a numpy waveform is provided without sr.
+ """
+ if isinstance(audios, list):
+ items = audios
+ else:
+ items = [audios]
+
+ out: List[Tuple[np.ndarray, int]] = []
+ for a in items:
+ if isinstance(a, str):
+ out.append(self._load_audio_to_np(a))
+ elif isinstance(a, tuple) and len(a) == 2 and isinstance(a[0], np.ndarray):
+ out.append((a[0].astype(np.float32), int(a[1])))
+ elif isinstance(a, np.ndarray):
+ raise ValueError("For numpy waveform input, pass a tuple (audio, sr).")
+ else:
+ raise TypeError(f"Unsupported audio input type: {type(a)}")
+ for i, a in enumerate(out):
+ if a[0].ndim > 1:
+ a[0] = np.mean(a[0], axis=-1).astype(np.float32)
+ out[i] = (a[0], a[1])
+ return out
+
+ def _ensure_list(self, x: MaybeList) -> List[Any]:
+ return x if isinstance(x, list) else [x]
+
+ def _build_assistant_text(self, text: str) -> str:
+ return f"<|im_start|>assistant\n{text}<|im_end|>\n<|im_start|>assistant\n"
+
+ def _build_ref_text(self, text: str) -> str:
+ return f"<|im_start|>assistant\n{text}<|im_end|>\n"
+
+ def _build_instruct_text(self, instruct: str) -> str:
+ return f"<|im_start|>user\n{instruct}<|im_end|>\n"
+
+ def _tokenize_texts(self, texts: List[str]) -> List[torch.Tensor]:
+ input_ids = []
+ for text in texts:
+ input = self.processor(text=text, return_tensors="pt", padding=True)
+ input_id = input["input_ids"].to(self.device)
+ input_id = input_id.unsqueeze(0) if input_id.dim() == 1 else input_id
+ input_ids.append(input_id)
+ return input_ids
+
+ def _merge_generate_kwargs(
+ self,
+ do_sample: Optional[bool] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ repetition_penalty: Optional[float] = None,
+ subtalker_dosample: Optional[bool] = None,
+ subtalker_top_k: Optional[int] = None,
+ subtalker_top_p: Optional[float] = None,
+ subtalker_temperature: Optional[float] = None,
+ max_new_tokens: Optional[int] = None,
+ **kwargs,
+ ) -> Dict[str, Any]:
+ """
+ Merge user-provided generation arguments with defaults from `generate_config.json`.
+
+ Rule:
+ - If the user explicitly passes a value (not None), use it.
+ - Otherwise, use the value from generate_config.json if present.
+ - Otherwise, fall back to the hard defaults.
+
+ Args:
+ do_sample, top_k, top_p, temperature, repetition_penalty,
+ subtalker_dosample, subtalker_top_k, subtalker_top_p, subtalker_temperature, max_new_tokens:
+ Common generation parameters.
+ **kwargs:
+ Other arguments forwarded to model.generate().
+
+ Returns:
+ Dict[str, Any]: Final kwargs to pass into model.generate().
+ """
+ hard_defaults = dict(
+ do_sample=True,
+ top_k=50,
+ top_p=1.0,
+ temperature=0.9,
+ repetition_penalty=1.05,
+ subtalker_dosample=True,
+ subtalker_top_k=50,
+ subtalker_top_p=1.0,
+ subtalker_temperature=0.9,
+ max_new_tokens=2048,
+ )
+
+ def pick(name: str, user_val: Any) -> Any:
+ if user_val is not None:
+ return user_val
+ if name in self.generate_defaults:
+ return self.generate_defaults[name]
+ return hard_defaults[name]
+
+ merged = dict(kwargs)
+ merged.update(
+ do_sample=pick("do_sample", do_sample),
+ top_k=pick("top_k", top_k),
+ top_p=pick("top_p", top_p),
+ temperature=pick("temperature", temperature),
+ repetition_penalty=pick("repetition_penalty", repetition_penalty),
+ subtalker_dosample=pick("subtalker_dosample", subtalker_dosample),
+ subtalker_top_k=pick("subtalker_top_k", subtalker_top_k),
+ subtalker_top_p=pick("subtalker_top_p", subtalker_top_p),
+ subtalker_temperature=pick("subtalker_temperature", subtalker_temperature),
+ max_new_tokens=pick("max_new_tokens", max_new_tokens),
+ )
+ return merged
+
+ # voice clone model
+ @torch.inference_mode()
+ def create_voice_clone_prompt(
+ self,
+ ref_audio: Union[AudioLike, List[AudioLike]],
+ ref_text: Optional[Union[str, List[Optional[str]]]] = None,
+ x_vector_only_mode: Union[bool, List[bool]] = False,
+ ) -> List[VoiceClonePromptItem]:
+ """
+ Build voice-clone prompt items from reference audio (and optionally reference text) using Base model.
+
+ Modes:
+ - x_vector_only_mode=True:
+ Only speaker embedding is used to clone voice; ref_text/ref_code are ignored.
+ This is mutually exclusive with ICL.
+ - x_vector_only_mode=False:
+ ICL mode is enabled automatically (icl_mode=True). In this case ref_text is required,
+ because the model continues/conditions on the reference text + reference speech codes.
+
+ Batch behavior:
+ - ref_audio can be a single item or a list.
+ - ref_text and x_vector_only_mode can be scalars or lists.
+ - If any of them are lists with length > 1, lengths must match.
+
+ Audio input:
+ - str: local wav path / URL / base64
+ - (np.ndarray, sr): waveform + sampling rate
+
+ Args:
+ ref_audio:
+ Reference audio(s) used to extract:
+ - ref_code via `model.speech_tokenizer.encode(...)`
+ - ref_spk_embedding via `model.extract_speaker_embedding(...)` (resampled to 24k)
+ ref_text:
+ Reference transcript(s). Required when x_vector_only_mode=False (ICL mode).
+ x_vector_only_mode:
+ Whether to use speaker embedding only. If False, ICL mode will be used.
+
+ Returns:
+ List[VoiceClonePromptItem]:
+ List of prompt items that can be converted into `voice_clone_prompt` dict.
+
+ Raises:
+ ValueError:
+ - If x_vector_only_mode=False but ref_text is missing.
+ - If batch lengths mismatch.
+ """
+ if self.model.tts_model_type != "base":
+ raise ValueError(
+ f"model with \ntokenizer_type: {self.model.tokenizer_type}\n"
+ f"tts_model_size: {self.model.tts_model_size}\n"
+ f"tts_model_type: {self.model.tts_model_type}\n"
+ "does not support create_voice_clone_prompt, Please check Model Card or Readme for more details."
+ )
+
+ ref_audio_list = self._ensure_list(ref_audio)
+ ref_text_list = self._ensure_list(ref_text) if isinstance(ref_text, list) else ([ref_text] * len(ref_audio_list))
+ xvec_list = self._ensure_list(x_vector_only_mode) if isinstance(x_vector_only_mode, list) else ([x_vector_only_mode] * len(ref_audio_list))
+
+ if len(ref_text_list) != len(ref_audio_list) or len(xvec_list) != len(ref_audio_list):
+ raise ValueError(
+ f"Batch size mismatch: ref_audio={len(ref_audio_list)}, ref_text={len(ref_text_list)}, x_vector_only_mode={len(xvec_list)}"
+ )
+
+ normalized = self._normalize_audio_inputs(ref_audio_list)
+
+ ref_wavs_for_code: List[np.ndarray] = []
+ ref_sr_for_code: List[int] = []
+ for wav, sr in normalized:
+ ref_wavs_for_code.append(wav)
+ ref_sr_for_code.append(sr)
+
+ if len(set(ref_sr_for_code)) == 1:
+ enc = self.model.speech_tokenizer.encode(ref_wavs_for_code, sr=ref_sr_for_code[0])
+ ref_codes = enc.audio_codes
+ else:
+ ref_codes = []
+ for wav, sr in normalized:
+ ref_codes.append(self.model.speech_tokenizer.encode(wav, sr=sr).audio_codes[0])
+
+ items: List[VoiceClonePromptItem] = []
+ for i, ((wav, sr), code, rtext, xvec_only) in enumerate(zip(normalized, ref_codes, ref_text_list, xvec_list)):
+ if not xvec_only:
+ if rtext is None or rtext == "":
+ raise ValueError(f"ref_text is required when x_vector_only_mode=False (ICL mode). Bad index={i}")
+
+ wav_resample = wav
+ if sr != self.model.speaker_encoder_sample_rate:
+ wav_resample = librosa.resample(y=wav_resample.astype(np.float32),
+ orig_sr=int(sr),
+ target_sr=self.model.speaker_encoder_sample_rate)
+
+ spk_emb = self.model.extract_speaker_embedding(audio=wav_resample,
+ sr=self.model.speaker_encoder_sample_rate)
+
+ items.append(
+ VoiceClonePromptItem(
+ ref_code=None if xvec_only else code,
+ ref_spk_embedding=spk_emb,
+ x_vector_only_mode=bool(xvec_only),
+ icl_mode=bool(not xvec_only),
+ ref_text=rtext,
+ )
+ )
+ return items
+
+ def _prompt_items_to_voice_clone_prompt(self, items: List[VoiceClonePromptItem]) -> Dict[str, Any]:
+ return dict(
+ ref_code=[it.ref_code for it in items],
+ ref_spk_embedding=[it.ref_spk_embedding for it in items],
+ x_vector_only_mode=[it.x_vector_only_mode for it in items],
+ icl_mode=[it.icl_mode for it in items],
+ )
+
+ # voice clone model
+ @torch.no_grad()
+ def generate_voice_clone(
+ self,
+ text: Union[str, List[str]],
+ language: Union[str, List[str]] = None,
+ ref_audio: Optional[Union[AudioLike, List[AudioLike]]] = None,
+ ref_text: Optional[Union[str, List[Optional[str]]]] = None,
+ x_vector_only_mode: Union[bool, List[bool]] = False,
+ voice_clone_prompt: Optional[Union[Dict[str, Any], List[VoiceClonePromptItem]]] = None,
+ non_streaming_mode: bool = False,
+ **kwargs,
+ ) -> Tuple[List[np.ndarray], int]:
+ """
+ Voice clone speech using the Base model.
+
+ You can provide either:
+ - (ref_audio, ref_text, x_vector_only_mode) and let this method build the prompt, OR
+ - `VoiceClonePromptItem` returned by `create_voice_clone_prompt`, OR
+ - a list of `VoiceClonePromptItem` returned by `create_voice_clone_prompt`.
+
+ `ref_audio` Supported forms:
+ - str: wav path / URL / base64 audio string
+ - (np.ndarray, sr): waveform + sampling rate
+ - list of the above
+
+ Input flexibility:
+ - text/language can be scalar or list.
+ - prompt can be single or batch.
+ - If batch mode (len(text)>1), lengths must match.
+
+ Args:
+ text:
+ Text(s) to synthesize.
+ language:
+ Language(s) for each sample.
+ ref_audio:
+ Reference audio(s) for prompt building. Required if voice_clone_prompt is not provided.
+ ref_text:
+ Reference text(s) used for ICL mode (required when x_vector_only_mode=False).
+ x_vector_only_mode:
+ If True, only speaker embedding is used (ignores ref_text/ref_code).
+ If False, ICL mode is used automatically.
+ voice_clone_prompt:
+ list[VoiceClonePromptItem] from `create_voice_clone_prompt`.
+ non_streaming_mode:
+ Using non-streaming text input, this option currently only simulates streaming text input when set to `false`,
+ rather than enabling true streaming input or streaming generation.
+ do_sample:
+ Whether to use sampling, recommended to be set to `true` for most use cases.
+ top_k:
+ Top-k sampling parameter.
+ top_p:
+ Top-p sampling parameter.
+ temperature:
+ Sampling temperature; higher => more random.
+ repetition_penalty:
+ Penalty to reduce repeated tokens/codes.
+ subtalker_dosample:
+ Sampling switch for the sub-talker (only valid for qwen3-tts-tokenizer-v2) if applicable.
+ subtalker_top_k:
+ Top-k for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_top_p:
+ Top-p for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_temperature:
+ Temperature for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ max_new_tokens:
+ Maximum number of new codec tokens to generate.
+ **kwargs:
+ Any other keyword arguments supported by HuggingFace Transformers `generate()` can be passed.
+ They will be forwarded to the underlying `Qwen3TTSForConditionalGeneration.generate(...)`.
+
+ Returns:
+ Tuple[List[np.ndarray], int]:
+ (wavs, sample_rate)
+
+ Raises:
+ ValueError:
+ If batch sizes mismatch or required prompt inputs are missing.
+ """
+ if self.model.tts_model_type != "base":
+ raise ValueError(
+ f"model with \ntokenizer_type: {self.model.tokenizer_type}\n"
+ f"tts_model_size: {self.model.tts_model_size}\n"
+ f"tts_model_type: {self.model.tts_model_type}\n"
+ "does not support generate_voice_clone, Please check Model Card or Readme for more details."
+ )
+
+ texts = self._ensure_list(text)
+ languages = self._ensure_list(language) if isinstance(language, list) else ([language] * len(texts) if language is not None else ["Auto"] * len(texts))
+ if len(languages) == 1 and len(texts) > 1:
+ languages = languages * len(texts)
+ if len(texts) != len(languages):
+ raise ValueError(f"Batch size mismatch: text={len(texts)}, language={len(languages)}")
+
+ self._validate_languages(languages)
+
+ if voice_clone_prompt is None:
+ if ref_audio is None:
+ raise ValueError("Either `voice_clone_prompt` or `ref_audio` must be provided.")
+ prompt_items = self.create_voice_clone_prompt(ref_audio=ref_audio, ref_text=ref_text, x_vector_only_mode=x_vector_only_mode)
+ if len(prompt_items) == 1 and len(texts) > 1:
+ prompt_items = prompt_items * len(texts)
+ if len(prompt_items) != len(texts):
+ raise ValueError(f"Batch size mismatch: prompt={len(prompt_items)}, text={len(texts)}")
+ voice_clone_prompt_dict = self._prompt_items_to_voice_clone_prompt(prompt_items)
+ ref_texts_for_ids = [it.ref_text for it in prompt_items]
+ else:
+ if isinstance(voice_clone_prompt, list):
+ prompt_items = voice_clone_prompt
+ if len(prompt_items) == 1 and len(texts) > 1:
+ prompt_items = prompt_items * len(texts)
+ if len(prompt_items) != len(texts):
+ raise ValueError(f"Batch size mismatch: prompt={len(prompt_items)}, text={len(texts)}")
+ voice_clone_prompt_dict = self._prompt_items_to_voice_clone_prompt(prompt_items)
+ ref_texts_for_ids = [it.ref_text for it in prompt_items]
+ else:
+ voice_clone_prompt_dict = voice_clone_prompt
+ ref_texts_for_ids = None
+
+ input_texts = [self._build_assistant_text(t) for t in texts]
+ input_ids = self._tokenize_texts(input_texts)
+
+ ref_ids = None
+ if ref_texts_for_ids is not None:
+ ref_ids = []
+ for i, rt in enumerate(ref_texts_for_ids):
+ if rt is None or rt == "":
+ ref_ids.append(None)
+ else:
+ ref_tok = self._tokenize_texts([self._build_ref_text(rt)])[0]
+ ref_ids.append(ref_tok)
+
+ gen_kwargs = self._merge_generate_kwargs(**kwargs)
+
+ talker_codes_list, _ = self.model.generate(
+ input_ids=input_ids,
+ ref_ids=ref_ids,
+ voice_clone_prompt=voice_clone_prompt_dict,
+ languages=languages,
+ non_streaming_mode=non_streaming_mode,
+ **gen_kwargs,
+ )
+
+ codes_for_decode = []
+ for i, codes in enumerate(talker_codes_list):
+ ref_code_list = voice_clone_prompt_dict.get("ref_code", None)
+ if ref_code_list is not None and ref_code_list[i] is not None:
+ codes_for_decode.append(torch.cat([ref_code_list[i].to(codes.device), codes], dim=0))
+ else:
+ codes_for_decode.append(codes)
+
+ wavs_all, fs = self.model.speech_tokenizer.decode([{"audio_codes": c} for c in codes_for_decode])
+
+ wavs_out: List[np.ndarray] = []
+ for i, wav in enumerate(wavs_all):
+ ref_code_list = voice_clone_prompt_dict.get("ref_code", None)
+ if ref_code_list is not None and ref_code_list[i] is not None:
+ ref_len = int(ref_code_list[i].shape[0])
+ total_len = int(codes_for_decode[i].shape[0])
+ cut = int(ref_len / max(total_len, 1) * wav.shape[0])
+ wavs_out.append(wav[cut:])
+ else:
+ wavs_out.append(wav)
+
+ return wavs_out, fs
+
+ # voice design model
+ @torch.no_grad()
+ def generate_voice_design(
+ self,
+ text: Union[str, List[str]],
+ instruct: Union[str, List[str]],
+ language: Union[str, List[str]] = None,
+ non_streaming_mode: bool = True,
+ **kwargs,
+ ) -> Tuple[List[np.ndarray], int]:
+ """
+ Generate speech with the VoiceDesign model using natural-language style instructions.
+
+ Args:
+ text:
+ Text(s) to synthesize.
+ language:
+ Language(s) for each sample.
+ instruct:
+ Instruction(s) describing desired voice/style. Empty string is allowed (treated as no instruction).
+ non_streaming_mode:
+ Using non-streaming text input, this option currently only simulates streaming text input when set to `false`,
+ rather than enabling true streaming input or streaming generation.
+ do_sample:
+ Whether to use sampling, recommended to be set to `true` for most use cases.
+ top_k:
+ Top-k sampling parameter.
+ top_p:
+ Top-p sampling parameter.
+ temperature:
+ Sampling temperature; higher => more random.
+ repetition_penalty:
+ Penalty to reduce repeated tokens/codes.
+ subtalker_dosample:
+ Sampling switch for the sub-talker (only valid for qwen3-tts-tokenizer-v2) if applicable.
+ subtalker_top_k:
+ Top-k for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_top_p:
+ Top-p for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_temperature:
+ Temperature for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ max_new_tokens:
+ Maximum number of new codec tokens to generate.
+ **kwargs:
+ Any other keyword arguments supported by HuggingFace Transformers `generate()` can be passed.
+ They will be forwarded to the underlying `Qwen3TTSForConditionalGeneration.generate(...)`.
+
+ Returns:
+ Tuple[List[np.ndarray], int]:
+ (wavs, sample_rate)
+ """
+ if self.model.tts_model_type != "voice_design":
+ raise ValueError(
+ f"model with \ntokenizer_type: {self.model.tokenizer_type}\n"
+ f"tts_model_size: {self.model.tts_model_size}\n"
+ f"tts_model_type: {self.model.tts_model_type}\n"
+ "does not support generate_voice_design, Please check Model Card or Readme for more details."
+ )
+
+ texts = self._ensure_list(text)
+ languages = self._ensure_list(language) if isinstance(language, list) else ([language] * len(texts) if language is not None else ["Auto"] * len(texts))
+ instructs = self._ensure_list(instruct)
+
+ if len(languages) == 1 and len(texts) > 1:
+ languages = languages * len(texts)
+ if len(instructs) == 1 and len(texts) > 1:
+ instructs = instructs * len(texts)
+
+ if not (len(texts) == len(languages) == len(instructs)):
+ raise ValueError(f"Batch size mismatch: text={len(texts)}, language={len(languages)}, instruct={len(instructs)}")
+
+ self._validate_languages(languages)
+
+ input_ids = self._tokenize_texts([self._build_assistant_text(t) for t in texts])
+
+ instruct_ids: List[Optional[torch.Tensor]] = []
+ for ins in instructs:
+ if ins is None or ins == "":
+ instruct_ids.append(None)
+ else:
+ instruct_ids.append(self._tokenize_texts([self._build_instruct_text(ins)])[0])
+
+ gen_kwargs = self._merge_generate_kwargs(**kwargs)
+
+ talker_codes_list, _ = self.model.generate(
+ input_ids=input_ids,
+ instruct_ids=instruct_ids,
+ languages=languages,
+ non_streaming_mode=non_streaming_mode,
+ **gen_kwargs,
+ )
+
+ wavs, fs = self.model.speech_tokenizer.decode([{"audio_codes": c} for c in talker_codes_list])
+ return wavs, fs
+
+ # custom voice model
+ @torch.no_grad()
+ def generate_custom_voice(
+ self,
+ text: Union[str, List[str]],
+ speaker: Union[str, List[str]],
+ language: Union[str, List[str]] = None,
+ instruct: Optional[Union[str, List[str]]] = None,
+ non_streaming_mode: bool = True,
+ **kwargs,
+ ) -> Tuple[List[np.ndarray], int]:
+ """
+ Generate speech with the CustomVoice model using a predefined speaker id, optionally controlled by instruction text.
+
+ Args:
+ text:
+ Text(s) to synthesize.
+ language:
+ Language(s) for each sample.
+ speaker:
+ Speaker name(s). Will be validated against `model.get_supported_speakers()` (case-insensitive).
+ instruct:
+ Optional instruction(s). If None, treated as empty (no instruction).
+ non_streaming_mode:
+ Using non-streaming text input, this option currently only simulates streaming text input when set to `false`,
+ rather than enabling true streaming input or streaming generation.
+ do_sample:
+ Whether to use sampling, recommended to be set to `true` for most use cases.
+ top_k:
+ Top-k sampling parameter.
+ top_p:
+ Top-p sampling parameter.
+ temperature:
+ Sampling temperature; higher => more random.
+ repetition_penalty:
+ Penalty to reduce repeated tokens/codes.
+ subtalker_dosample:
+ Sampling switch for the sub-talker (only valid for qwen3-tts-tokenizer-v2) if applicable.
+ subtalker_top_k:
+ Top-k for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_top_p:
+ Top-p for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ subtalker_temperature:
+ Temperature for sub-talker sampling (only valid for qwen3-tts-tokenizer-v2).
+ max_new_tokens:
+ Maximum number of new codec tokens to generate.
+ **kwargs:
+ Any other keyword arguments supported by HuggingFace Transformers `generate()` can be passed.
+ They will be forwarded to the underlying `Qwen3TTSForConditionalGeneration.generate(...)`.
+
+ Returns:
+ Tuple[List[np.ndarray], int]:
+ (wavs, sample_rate)
+
+ Raises:
+ ValueError:
+ If any speaker/language is unsupported or batch sizes mismatch.
+ """
+ if self.model.tts_model_type != "custom_voice":
+ raise ValueError(
+ f"model with \ntokenizer_type: {self.model.tokenizer_type}\n"
+ f"tts_model_size: {self.model.tts_model_size}\n"
+ f"tts_model_type: {self.model.tts_model_type}\n"
+ "does not support generate_custom_voice, Please check Model Card or Readme for more details."
+ )
+
+ texts = self._ensure_list(text)
+ languages = self._ensure_list(language) if isinstance(language, list) else ([language] * len(texts) if language is not None else ["Auto"] * len(texts))
+ speakers = self._ensure_list(speaker)
+ if self.model.tts_model_size in "0b6": # for 0b6 model, instruct is not supported
+ instruct = None
+ instructs = self._ensure_list(instruct) if isinstance(instruct, list) else ([instruct] * len(texts) if instruct is not None else [""] * len(texts))
+
+ if len(languages) == 1 and len(texts) > 1:
+ languages = languages * len(texts)
+ if len(speakers) == 1 and len(texts) > 1:
+ speakers = speakers * len(texts)
+ if len(instructs) == 1 and len(texts) > 1:
+ instructs = instructs * len(texts)
+
+ if not (len(texts) == len(languages) == len(speakers) == len(instructs)):
+ raise ValueError(
+ f"Batch size mismatch: text={len(texts)}, language={len(languages)}, speaker={len(speakers)}, instruct={len(instructs)}"
+ )
+
+ self._validate_languages(languages)
+ self._validate_speakers(speakers)
+
+ input_ids = self._tokenize_texts([self._build_assistant_text(t) for t in texts])
+
+ instruct_ids: List[Optional[torch.Tensor]] = []
+ for ins in instructs:
+ if ins is None or ins == "":
+ instruct_ids.append(None)
+ else:
+ instruct_ids.append(self._tokenize_texts([self._build_instruct_text(ins)])[0])
+
+ gen_kwargs = self._merge_generate_kwargs(**kwargs)
+
+ talker_codes_list, _ = self.model.generate(
+ input_ids=input_ids,
+ instruct_ids=instruct_ids,
+ languages=languages,
+ speakers=speakers,
+ non_streaming_mode=non_streaming_mode,
+ **gen_kwargs,
+ )
+
+ wavs, fs = self.model.speech_tokenizer.decode([{"audio_codes": c} for c in talker_codes_list])
+ return wavs, fs
+
+
+ def get_supported_speakers(self) -> Optional[List[str]]:
+ """
+ List supported speaker names for the current model.
+
+ This is a convenience wrapper around `model.get_supported_speakers()`.
+ If the underlying model does not expose speaker constraints (returns None),
+ this method also returns None.
+
+ Returns:
+ Optional[List[str]]:
+ - A sorted list of supported speaker names (lowercased), if available.
+ - None if the model does not provide supported speakers.
+ """
+ supported = self._supported_speakers_set()
+ if supported is None:
+ return None
+ return sorted(supported)
+
+
+ def get_supported_languages(self) -> Optional[List[str]]:
+ """
+ List supported language names for the current model.
+
+ This is a convenience wrapper around `model.get_supported_languages()`.
+ If the underlying model does not expose language constraints (returns None),
+ this method also returns None.
+
+ Returns:
+ Optional[List[str]]:
+ - A sorted list of supported language names (lowercased), if available.
+ - None if the model does not provide supported languages.
+ """
+ supported = self._supported_languages_set()
+ if supported is None:
+ return None
+ return sorted(supported)
diff --git a/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_tokenizer.py b/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_tokenizer.py
new file mode 100644
index 0000000..eae969d
--- /dev/null
+++ b/models/Qwen3-TTS/qwen_tts/inference/qwen3_tts_tokenizer.py
@@ -0,0 +1,411 @@
+# coding=utf-8
+# Copyright 2026 The Alibaba Qwen team.
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import base64
+import io
+import urllib.request
+from typing import List, Optional, Tuple, Union
+from urllib.parse import urlparse
+
+import librosa
+import numpy as np
+import soundfile as sf
+import torch
+from torch.nn.utils.rnn import pad_sequence
+from transformers import AutoConfig, AutoFeatureExtractor, AutoModel
+
+from ..core import (
+ Qwen3TTSTokenizerV1Config,
+ Qwen3TTSTokenizerV1Model,
+ Qwen3TTSTokenizerV2Config,
+ Qwen3TTSTokenizerV2Model,
+)
+
+AudioInput = Union[
+ str, # wav path, or base64 string
+ np.ndarray, # 1-D float array
+ List[str],
+ List[np.ndarray],
+]
+
+
+class Qwen3TTSTokenizer:
+ """
+ A wrapper for Qwen3 TTS Tokenizer 25Hz/12Hz with HuggingFace-style loading.
+
+ - from_pretrained(): loads speech tokenizer model via AutoModel and feature_extractor via AutoFeatureExtractor.
+ - encode(): supports wav path(s), base64 audio string(s), numpy array(s).
+ - decode(): accepts either the raw model encode output, or a minimal dict/list-of-dicts.
+
+ Notes:
+ - For numpy array input, you must pass `sr` so the audio can be resampled to model sample rate.
+ - Returned audio is float32 numpy arrays and the output sample rate.
+ """
+
+ def __init__(self):
+ self.model = None
+ self.feature_extractor = None
+ self.config = None
+ self.device = None
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: str, **kwargs) -> "Qwen3TTSTokenizer":
+ """
+ Initialize tokenizer with HuggingFace `from_pretrained` style.
+
+ Args:
+ pretrained_model_name_or_path (str):
+ HuggingFace repo id or local directory.
+ **kwargs (Any):
+ Forwarded to `AutoModel.from_pretrained(...)` directly.
+ Typical examples: device_map="cuda:0", dtype=torch.bfloat16, attn_implementation="eager".
+
+ Returns:
+ Qwen3TTSTokenizer:
+ Initialized instance with `model`, `feature_extractor`, `config`.
+ """
+ inst = cls()
+
+ AutoConfig.register("qwen3_tts_tokenizer_25hz", Qwen3TTSTokenizerV1Config)
+ AutoModel.register(Qwen3TTSTokenizerV1Config, Qwen3TTSTokenizerV1Model)
+
+ AutoConfig.register("qwen3_tts_tokenizer_12hz", Qwen3TTSTokenizerV2Config)
+ AutoModel.register(Qwen3TTSTokenizerV2Config, Qwen3TTSTokenizerV2Model)
+
+ inst.feature_extractor = AutoFeatureExtractor.from_pretrained(pretrained_model_name_or_path)
+ inst.model = AutoModel.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ inst.config = inst.model.config
+
+ inst.device = getattr(inst.model, "device", None)
+ if inst.device is None:
+ # fallback: infer from first parameter device
+ try:
+ inst.device = next(inst.model.parameters()).device
+ except StopIteration:
+ inst.device = torch.device("cpu")
+
+ return inst
+
+ def _is_probably_base64(self, s: str) -> bool:
+ if s.startswith("data:audio"):
+ return True
+ # Heuristic: no filesystem path separators and long enough.
+ if ("/" not in s and "\\" not in s) and len(s) > 256:
+ return True
+ return False
+
+ def _is_url(self, s: str) -> bool:
+ try:
+ u = urlparse(s)
+ return u.scheme in ("http", "https") and bool(u.netloc)
+ except Exception:
+ return False
+
+ def _decode_base64_to_wav_bytes(self, b64: str) -> bytes:
+ # Accept both "data:audio/wav;base64,...." and raw base64
+ if "," in b64 and b64.strip().startswith("data:"):
+ b64 = b64.split(",", 1)[1]
+ return base64.b64decode(b64)
+
+ def load_audio(
+ self,
+ x: str,
+ target_sr: int,
+ ) -> np.ndarray:
+ """
+ Load audio from wav path or base64 string, then resample to target_sr.
+
+ Args:
+ x (str):
+ A wav file path, or a base64 audio string (raw or data URL).
+ target_sr (int):
+ Target sampling rate.
+
+ Returns:
+ np.ndarray:
+ 1-D float32 waveform at target_sr.
+ """
+ if self._is_url(x):
+ with urllib.request.urlopen(x) as resp:
+ audio_bytes = resp.read()
+ with io.BytesIO(audio_bytes) as f:
+ audio, sr = sf.read(f, dtype="float32", always_2d=False)
+ elif self._is_probably_base64(x):
+ wav_bytes = self._decode_base64_to_wav_bytes(x)
+ with io.BytesIO(wav_bytes) as f:
+ audio, sr = sf.read(f, dtype="float32", always_2d=False)
+ else:
+ audio, sr = librosa.load(x, sr=None, mono=True)
+
+ if audio.ndim > 1:
+ audio = np.mean(audio, axis=-1)
+
+ if sr != target_sr:
+ audio = librosa.resample(y=audio, orig_sr=sr, target_sr=target_sr)
+
+ return audio.astype(np.float32)
+
+ def _normalize_audio_inputs(
+ self,
+ audios: AudioInput,
+ sr: Optional[int],
+ ) -> List[np.ndarray]:
+ """
+ Normalize all supported input types into a list of 1-D numpy float32 waveforms
+ at `self.feature_extractor.sampling_rate`.
+
+ Args:
+ audios (AudioInput):
+ - str: wav path OR base64 audio string
+ - np.ndarray: raw waveform (sr must be provided)
+ - list[str] / list[np.ndarray]
+ sr (Optional[int]):
+ Sampling rate for raw numpy input. Required if input is np.ndarray or list[np.ndarray].
+
+ Returns:
+ List[np.ndarray]:
+ List of float32 waveforms resampled to model input SR.
+ """
+ target_sr = int(self.feature_extractor.sampling_rate)
+
+ if isinstance(audios, (str, np.ndarray)):
+ audios = [audios]
+
+ if len(audios) == 0:
+ return []
+
+ if isinstance(audios[0], str):
+ # wav path list or base64 list
+ return [self.load_audio(x, target_sr=target_sr) for x in audios] # type: ignore[arg-type]
+
+ # numpy list
+ if sr is None:
+ raise ValueError("For numpy waveform input, you must provide `sr` (original sampling rate).")
+
+ out: List[np.ndarray] = []
+ for a in audios: # type: ignore[assignment]
+ if not isinstance(a, np.ndarray):
+ raise TypeError("Mixed input types are not supported. Use all paths/base64 or all numpy arrays.")
+ if a.ndim > 1:
+ a = np.mean(a, axis=-1)
+ if int(sr) != target_sr:
+ a = librosa.resample(y=a.astype(np.float32), orig_sr=int(sr), target_sr=target_sr)
+ out.append(a.astype(np.float32))
+ return out
+
+ def encode(
+ self,
+ audios: AudioInput,
+ sr: Optional[int] = None,
+ return_dict: bool = True,
+ ):
+ """
+ Batch-encode audio into discrete codes (and optional conditioning, depending on 25Hz/12Hz).
+
+ Args:
+ audios (AudioInput):
+ Supported forms:
+ - np.ndarray: waveform (requires sr)
+ - list[np.ndarray]: waveforms (requires sr)
+ - str: wav path OR base64 audio string
+ - list[str]: wav paths and/or base64 strings
+ sr (Optional[int], default=None):
+ Original sampling rate for numpy waveform input.
+ return_dict (bool, default=True):
+ Forwarded to model.encode(...). If True, returns ModelOutput.
+
+ Returns:
+ 25Hz:
+ Qwen3TTSTokenizerV1EncoderOutput (if return_dict=True) with fields:
+ - audio_codes: List[torch.LongTensor] each (codes_len,)
+ - xvectors: List[torch.FloatTensor] each (xvector_dim,)
+ - ref_mels: List[torch.FloatTensor] each (mel_len, mel_dim)
+ 12Hz:
+ Qwen3TTSTokenizerV2EncoderOutput (if return_dict=True) with fields:
+ - audio_codes: List[torch.LongTensor] each (codes_len, num_quantizers)
+
+ If return_dict=False, returns the raw tuple from model.encode.
+ """
+ wavs = self._normalize_audio_inputs(audios, sr=sr)
+
+ inputs = self.feature_extractor(
+ raw_audio=wavs,
+ sampling_rate=int(self.feature_extractor.sampling_rate),
+ return_tensors="pt",
+ )
+ inputs = inputs.to(self.device).to(self.model.dtype)
+
+ with torch.inference_mode():
+ # model.encode expects (B, T) and (B, T)
+ enc = self.model.encode(
+ inputs["input_values"].squeeze(1),
+ inputs["padding_mask"].squeeze(1),
+ return_dict=return_dict,
+ )
+ return enc
+
+ def decode(
+ self,
+ encoded,
+ ) -> Tuple[List[np.ndarray], int]:
+ """
+ Decode back to waveform.
+
+ Usage:
+ 1) Pass the raw output of `encode(...)` directly (recommended).
+ - 25Hz: expects fields audio_codes, xvectors, ref_mels
+ - 12Hz: expects field audio_codes
+ 2) Pass a dict or list[dict] (minimal form) for custom pipelines:
+ - 25Hz dict keys: {"audio_codes", "xvectors", "ref_mels"}
+ - 12Hz dict keys: {"audio_codes"}
+ Values can be torch tensors or numpy arrays.
+
+ Args:
+ encoded (Any):
+ - ModelOutput returned by `encode()`, OR
+ - dict, OR
+ - list[dict]
+
+ Returns:
+ Tuple[List[np.ndarray], int]:
+ - wavs: list of 1-D float32 numpy arrays
+ - sample_rate: int, model output sampling rate
+ """
+ model_type = self.model.get_model_type()
+
+ def _to_tensor(x, dtype=None):
+ if isinstance(x, torch.Tensor):
+ return x
+ x = np.asarray(x)
+ t = torch.from_numpy(x)
+ if dtype is not None:
+ t = t.to(dtype)
+ return t
+
+ # Normalize `encoded` into the same shapes as the official demo uses.
+ if hasattr(encoded, "audio_codes"):
+ # ModelOutput from encode()
+ audio_codes_list = encoded.audio_codes
+ xvectors_list = getattr(encoded, "xvectors", None)
+ ref_mels_list = getattr(encoded, "ref_mels", None)
+ elif isinstance(encoded, dict):
+ audio_codes_list = encoded["audio_codes"]
+ xvectors_list = encoded.get("xvectors", None)
+ ref_mels_list = encoded.get("ref_mels", None)
+ elif isinstance(encoded, list):
+ # list of dicts
+ audio_codes_list = [e["audio_codes"] for e in encoded]
+ xvectors_list = [e["xvectors"] for e in encoded] if ("xvectors" in encoded[0]) else None
+ ref_mels_list = [e["ref_mels"] for e in encoded] if ("ref_mels" in encoded[0]) else None
+ else:
+ raise TypeError("`encoded` must be an encode output, a dict, or a list of dicts.")
+
+ # Ensure list form for per-sample tensors
+ if isinstance(audio_codes_list, torch.Tensor):
+ # Could be a single sample tensor or an already padded batch tensor.
+ t = audio_codes_list
+ if t.dim() == 1:
+ # 25Hz single sample: (C,) -> (1, C)
+ t = t.unsqueeze(0)
+ elif t.dim() == 2:
+ # 12Hz single sample: (C, Q) -> (1, C, Q)
+ t = t.unsqueeze(0)
+ audio_codes_padded = t.to(self.device)
+ else:
+ # List[Tensor/np]
+ audio_codes_list = [_to_tensor(c, dtype=torch.long) for c in audio_codes_list]
+ audio_codes_padded = pad_sequence(audio_codes_list, batch_first=True, padding_value=0).to(self.device)
+
+ with torch.inference_mode():
+ if model_type == "qwen3_tts_tokenizer_25hz":
+ if xvectors_list is None or ref_mels_list is None:
+ raise ValueError("25Hz decode requires `xvectors` and `ref_mels`.")
+
+ if isinstance(xvectors_list, torch.Tensor):
+ xvectors_batch = xvectors_list
+ if xvectors_batch.dim() == 1: # (D,) -> (1, D)
+ xvectors_batch = xvectors_batch.unsqueeze(0)
+ xvectors_batch = xvectors_batch.to(self.device).to(self.model.dtype)
+ else:
+ xvectors_list = [_to_tensor(x, dtype=torch.float32) for x in xvectors_list]
+ xvectors_batch = torch.stack(xvectors_list, dim=0).to(self.device).to(self.model.dtype)
+
+ if isinstance(ref_mels_list, torch.Tensor):
+ ref_mels_padded = ref_mels_list
+ if ref_mels_padded.dim() == 2: # (T, M) -> (1, T, M)
+ ref_mels_padded = ref_mels_padded.unsqueeze(0)
+ ref_mels_padded = ref_mels_padded.to(self.device).to(self.model.dtype)
+ else:
+ ref_mels_list = [_to_tensor(m, dtype=torch.float32) for m in ref_mels_list]
+ ref_mels_padded = pad_sequence(ref_mels_list, batch_first=True, padding_value=0).to(self.device).to(self.model.dtype)
+
+ dec = self.model.decode(audio_codes_padded, xvectors_batch, ref_mels_padded, return_dict=True)
+ wav_tensors = dec.audio_values
+
+ elif model_type == "qwen3_tts_tokenizer_12hz":
+ dec = self.model.decode(audio_codes_padded, return_dict=True)
+ wav_tensors = dec.audio_values
+
+ else:
+ raise ValueError(f"Unknown model type: {model_type}")
+
+ wavs = [w.to(torch.float32).detach().cpu().numpy() for w in wav_tensors]
+ return wavs, int(self.model.get_output_sample_rate())
+
+ def get_model_type(self) -> str:
+ """
+ Get the underlying tokenizer model type.
+
+ Returns:
+ str: Model type string from `self.model.config.model_type`
+ (e.g. "qwen3_tts_tokenizer_25hz" / "qwen3_tts_tokenizer_12hz").
+ """
+ return self.model.get_model_type()
+
+ def get_input_sample_rate(self) -> int:
+ """
+ Get the expected input sample rate for encoding.
+
+ Returns:
+ int: Input sample rate (Hz).
+ """
+ return int(self.model.get_input_sample_rate())
+
+ def get_output_sample_rate(self) -> int:
+ """
+ Get the output sample rate for decoded waveforms.
+
+ Returns:
+ int: Output sample rate (Hz).
+ """
+ return int(self.model.get_output_sample_rate())
+
+ def get_encode_downsample_rate(self) -> int:
+ """
+ Get the encoder downsample rate (waveform samples per code step).
+
+ Returns:
+ int: Encode downsample rate.
+ """
+ return int(self.model.get_encode_downsample_rate())
+
+ def get_decode_upsample_rate(self) -> int:
+ """
+ Get the decoder upsample rate (waveform samples per code step).
+
+ Returns:
+ int: Decode upsample rate.
+ """
+ return int(self.model.get_decode_upsample_rate())
\ No newline at end of file